学前导读:概率与统计这章到底在学什么
对新人来说,这一章最容易出现的问题不是“公式不会算”,而是学着学着不知道这些概念到底和 AI 有什么关系。
这一章其实在解决同一件事:
当世界充满不确定性时,我们怎样描述不确定、怎样从数据反推规律、怎样衡量模型到底有多确定。
学习目标
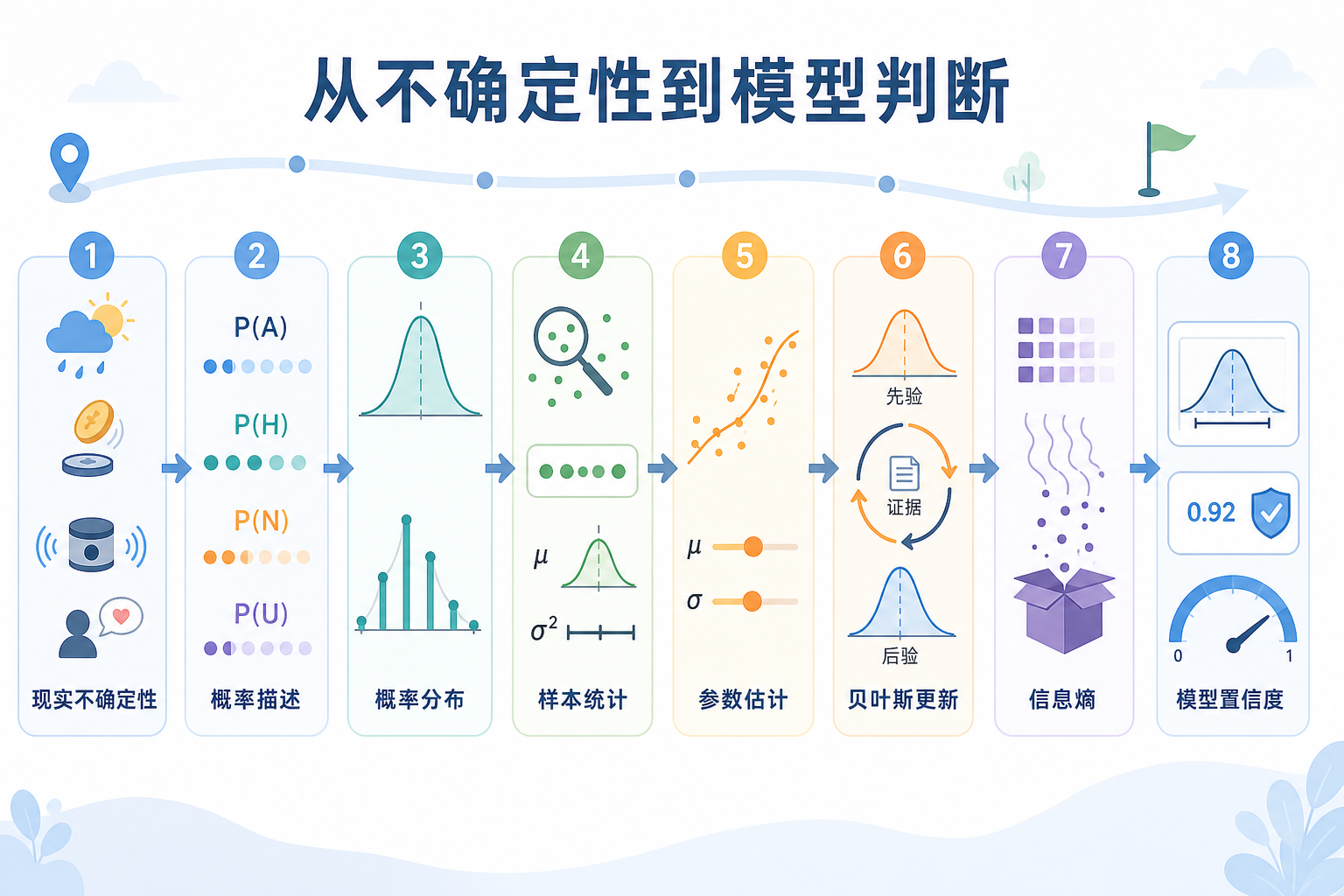
- 建立“概率 -> 分布 -> 推断 -> 信息论”的整章地图
- 知道这一章每节课在 AI 里的位置
- 知道新人应该先抓哪些直觉,再看公式
先说一个很重要的学习预期
概率与统计本来就不是几节课能“学完”的内容。
所以这一章更现实的目标是:
- 先让你不怕概率符号
- 先让你知道“为什么模型老在输出概率”
- 先让你看懂分布、推断和信息论在 AI 里各自扮演什么角色
你不需要一开始就把所有公式推得很熟,
但你应该开始能说清:
- 它们分别在描述什么不确定性
- 为什么这些概念会直接影响模型训练和判断
一、这一章四节之间是什么关系?
你可以把这一章记成四个问题:
- 概率基础:某件事发生的可能性有多大?
- 概率分布:如果不是一次事件,而是一整类随机现象,它整体长什么样?
- 统计推断:看到了数据,怎样反推出背后的参数和结论?
- 信息论:模型的预测到底有多不确定、和真实分布差多远?
二、这一章和 AI 的关系
| 章节 | 在 AI 里最直接的作用 |
|---|---|
| 概率基础 | 分类概率、贝叶斯更新、垃圾邮件判断 |
| 概率分布 | 正态分布、噪声建模、随机初始化、数据统计 |
| 统计推断 | MLE、MAP、A/B 测试、参数估计 |
| 信息论 | 熵、交叉熵、KL 散度、分类损失函数 |
很多 AI 名词如果只背表面,会很散;但一旦放回这条主线就会清楚很多。
例如:
- 模型输出
0.93,其实是在给一个概率 CrossEntropyLoss其实来自信息论MLE其实是在做“什么参数最能解释这批数据”贝叶斯其实是在做“有了新证据后,怎样更新判断”
三、为什么 AI 特别离不开这一章?
因为 AI 处理的世界,几乎从来都不是完全确定的。
比如:
- 模型只会说“80% 可能是猫”
- 检测结果总有误报和漏报
- 文本分类也常常不是 100% 确定
- 训练时 loss 和交叉熵都和概率视角直接相关
所以你可以把这章先理解成:
给 AI 系统补一套面对不确定性时的语言。
新人最应该怎么学这一章?
4.1 先学直觉,不先死磕符号
比如:
- 条件概率先想“已知某件事发生后,再看另一件事的概率”
- 分布先想“随机现象整体长什么样”
- MLE 先想“哪个参数最能解释观测数据”
- 熵先想“到底有多不确定”
4.2 每个概念都要连回一个 AI 场景
如果你学完一个概念,回答不出“它在 AI 里用来干嘛”,那它大概率还没有真正进入你的理解。
4.3 不用追求一次全会
这一章很多内容在后面会反复出现:
- 5 机器学习入门到实战会继续碰到概率和统计推断
- 6 深度学习与 Transformer 基础以后会继续碰到梯度、损失和优化
- 7 大模型原理、Prompt 与微调、8 LLM 应用开发与 RAG 会继续碰到交叉熵、KL 散度、贝叶斯视角
所以这章更重要的是先建立第一次清晰理解。
五、这一章建议怎么分配时间?
一个比较适合新人的参考节奏是:
-
概率基础:2~4 小时
重点把“条件概率”和“贝叶斯更新”看顺。 -
概率分布:2~4 小时
重点把“单次事件”升级成“整体规律”。 -
统计推断:2~4 小时
重点看懂 MLE、MAP、A/B 测试这些判断为什么成立。 -
信息论:2~4 小时
重点看懂熵、交叉熵、KL 散度为什么会直接进 loss。
这样学会比“先背一堆符号”稳很多。
六、学完这章后,你至少应该会什么?
- 看到一个模型概率输出时,不会把它当成“绝对结论”
- 知道条件概率、贝叶斯更新和分布各自是在说什么
- 知道 MLE、MAP、假设检验大概在解决什么问题
- 知道熵、交叉熵和 KL 散度为什么会出现在 AI 训练里
如果你读这章时开始发虚,先抓哪几件事最值?
最值得先抓的是:
- 概率是在描述“不确定性”
- 条件概率是在说“有了新信息以后,判断会怎么变”
- 分布是在说“随机现象整体长什么样”
- 交叉熵和信息论最后会直接长进 loss 里
只要这四条稳了,这章就已经很值。
新人和进阶学习者怎么读
新人第一次学这一章时,先抓住主线和最小可运行例子。你不需要一次理解所有细节,只要能说清楚这一章解决什么问题、输入输出是什么、最小项目怎么跑起来,就可以继续往后走。
有经验的学习者可以把这一章当成查漏补缺和工程化练习:关注边界条件、失败案例、评估方式、代码可复现性,以及它和前后阶段的连接。读完后最好能把本章内容沉淀到自己的作品 README 或实验记录里。
学习时间与难度建议
| 学习方式 | 建议投入 | 目标 |
|---|---|---|
| 快速浏览 | 20~30 分钟 | 看懂本章解决什么问题,知道后面会用到哪里 |
| 最小通关 | 1~2 小时 | 跑通一个最小例子,完成本章小项目出口 |
| 深入练习 | 半天~1 天 | 补充错误分析、对比实验或项目 README 记录 |
本章自测问题
| 自测问题 | 通过标准 |
|---|---|
| 这一章解决什么问题? | 能用一句话说明它在整门课里的位置 |
| 最小输入输出是什么? | 能说清楚例子需要什么输入,会产生什么结果 |
| 常见失败点在哪里? | 能列出至少一个报错、效果差或理解偏差的原因 |
| 学完后能沉淀什么? | 能把本章产出写进项目 README、实验记录或作品集 |
本章小项目出口
学完这一章后,建议完成一个最小练习:选择一个本章最核心的概念或工具,做出一个可以运行、可以截图、可以写进 README 的小成果。�它不需要复杂,但要能说明输入是什么、处理过程是什么、输出结果是什么。
过关标准
这一章结束时,你应该能用自己的话说明本章解决什么问题、它和前后学习站有什么关系,并能完成本章小项目出口的最小版本。
如果你还能记录一次常见错误、一次调试过程或一次结果改进,就说明你已经不只是“看过内容”,而是在把这一章变成自己的项目经验。