学前导读:线性代数这章到底在学什么
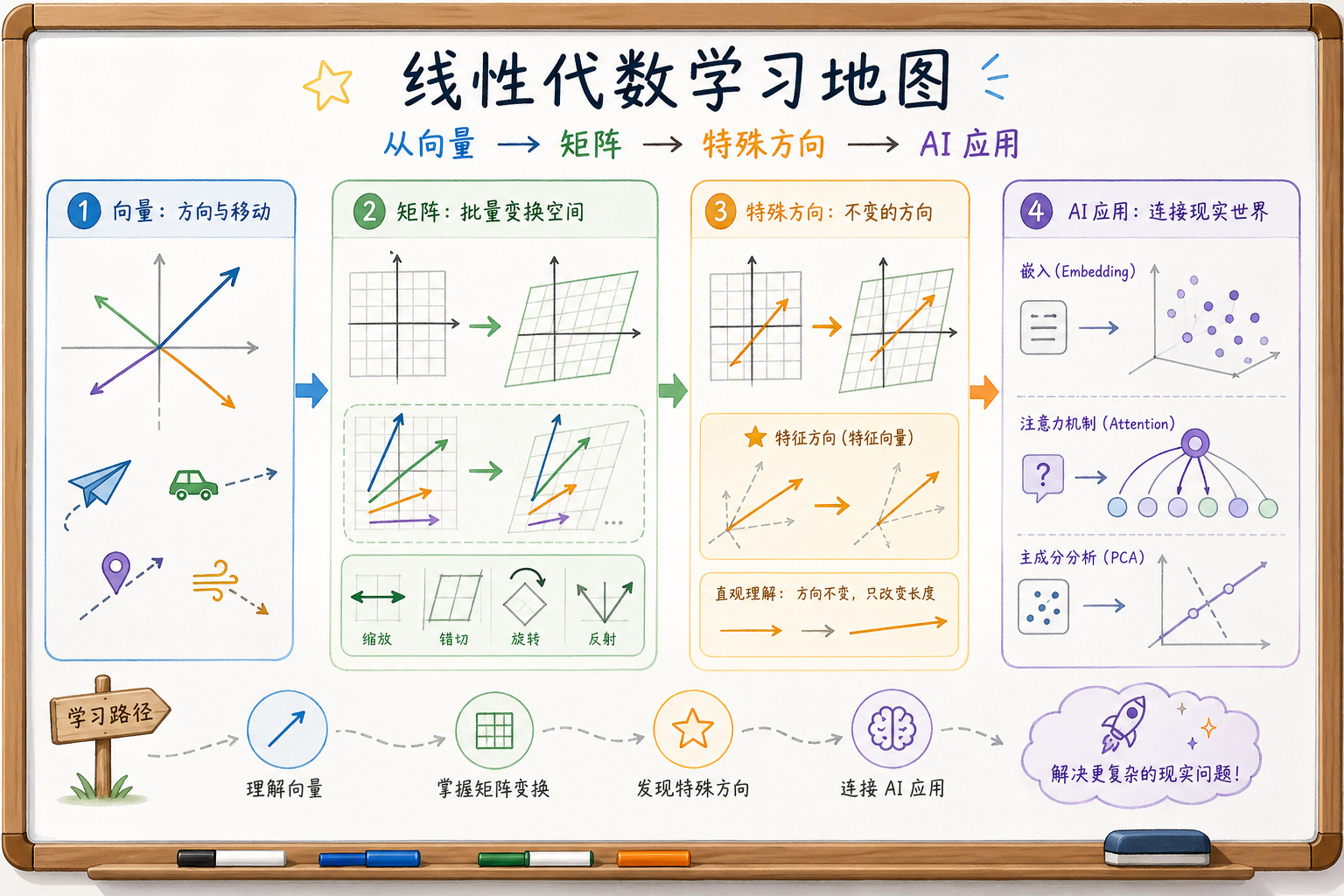
对新人来说,这一章最重要的不是证明定理,而是先建立一张地图:
- 为什么 AI 里到处都是向量和矩阵
- 这四节课之间是什么关系
- 学到什么程度就足够支撑后面的机器学习和深度学习
学习目标
- 知道线性代数这章在整套课里的位置
- 看懂“向量 -> 矩阵 -> 特征值 -> 线性变换”的关系
- 知道新人该重点掌握什么、哪些内容先求直觉就够
- 在正式进入公式前,先建立 AI 场景里的使用感
先说一个很重要的心理预期
线性代数本来就是可以单独学很久的一门课。
所以这一章的目标,不是把所有证明、定理和推广都讲完,而是先让你:
- 不怕向量和矩阵
- 看懂最常见的运算到底在做什么
- 能把这些对象和 AI 里的数据��、权重、相似度、PCA 连起来
如果你现在读完一遍还不能“熟练做题”,这完全正常。
更重要的标准是:
- 你有没有开始把“向量 / 矩阵”当成 AI 的语言,而不是一堆陌生符号
一、为什么 AI 里到处都是线性代数?
因为 AI 的很多对象,本质上都可以表示成“数字数组”,而线性代数就是研究这些数字数组如何表示、如何变换、如何比较的一套语言。
| AI 场景 | 你看到的对象 | 在线性代数里怎么看 |
|---|---|---|
| 一条用户数据 | 年龄、收入、城市等级、活跃度 | 一个向量 |
| 一批样本 | 很多条用户数据堆在一起 | 一个矩阵 |
| 文本向量检索 | 查询和文档谁更像 | 向量相似度 |
| 神经网络一层 | 输入乘权重再加偏置 | 矩阵乘法 |
| PCA 降维 | 压缩特征又尽量少丢信息 | 特征值和特征向量 |
所以你可以把这一章理解成:
- 向量:学会描述一个对象
- 矩阵:学会同时处理一批对象,或者对对象做变换
- 特征值:学会找到“最重要的方向”
- 向量空间:学会从更高视角理解维度、基和变换
二、这一章四节之间是什么关系?
你可以把整章压缩成一句话:
先学会把数据写成向量,再学会用矩阵批量处理向量,最后学会从这些变换里找出最重要的结构。
三、为什么这章对 AI 特别关键?
因为后面你会反复看到这些东西:
- 一条样本是向量
- 一批样本是矩阵
- 一层神经网络是矩阵乘法
- 相似度检索要用点积或余弦相似度
- PCA 要找最重要的方向
也就是说,线性代数在 AI 里不是“背景知识”,而是:
你看模型和数据时最常用的一种观察语言。
新人最应该怎么学这一章?
4.1 第一步:先把向量学明白
你最少要弄懂这些事:
- 向量就是一串有序数字
- 向量长度、点积、余弦相似度分别在衡量什么
- 为什么 RAG、推荐系统、词向量都会用到相似度
4.2 第二步:再把矩阵当成“批量处理机器”
你最少要弄懂这些事:
- 一批样本堆起来就是矩阵
- 矩阵乘法其实就是“行和列做点积”
- 为什么神经网络一层可以写成
X @ W + b
4.3 第三步:把特征值当成“特殊方向”
你最少要弄懂这些事:
- 大多数向量被矩阵作用后,方向会变
- 但有些特殊方向只会被拉长或缩短
- PCA 就是在找数据变化最大的那些方向
4.4 第四步:把向量空间当成加深理解的选修
这一节更像“把前面学过的内容抬高一个视角”。
如果你当前目标是尽快学机器学习和深度学习,可以先把:
- 线性无关
- 基
- 维度
- 线性变换
理解到“会解释、会用代码验证”的程度,再继续往后走。
4.5 一个更适合新人的阅读顺序
建议你每节都按下面顺序看:
- 先看类比和图
- 再看最小代码
- 最后再看公式和定义
尤其在线性代数里,这样会比一开始就盯着符号看,舒服很多。
五、这一章建议怎么分配时间?
如果你想把这一章学得更稳,一个很适合新人的参考节奏是:
-
向量:2~4 小时
重点不是做题,而是把“对象 -> 向量 -> 相似度”真正讲顺。 -
矩阵:3~5 小时
重点把“批量处理”和X @ W这条主线看懂。 -
特征值:3~5 小时
重点先建立“特殊方向”和 PCA 直觉,不急着求很会算。 -
向量空间:2~4 小时
这节更像加深理解,适合在前面三节稳住后再读。
如果你一天只啃 1 节,通常会比连续硬刷 4 节更稳。
六、学这一章最常见的误解
- 误以为线性代数就是一堆公式,其实它首先是描述数据和变换的语言
- 误以为看不懂证明就学不会 AI,其实先看懂图和代码已经很有价值
- 误以为数学和代码可以分开学,其实一分开就很容易越来越虚
- 误以为高维向量画不出来就无法理解,其实二维图只是帮助建立直觉
七、先跑一个贯穿整章的最小例子
下面这段小代码,几乎把这一章的主线都串起来了:
- 一条样本是向量
- 多条样本堆起来是矩阵
- 和权重做点积可以得到打分
- 一批样本和权重矩阵相乘可以一次算出多组结果
import numpy as np
student = np.array([90, 85, 92])
print("单个学生向量:", student)
students = np.array([
[90, 85, 92],
[70, 88, 75],
[95, 91, 89],
])
print("样本矩阵形状:", students.shape) # (3, 3)
weights = np.array([0.4, 0.2, 0.4])
single_score = student @ weights
print("单个学生综合分:", round(single_score, 2))
all_scores = students @ weights
print("所有学生综合分:", all_scores.round(2))
八、学完这章后,你至少应该会什么?
- 看到一条数据,知道它可以写成向量
- 看到一批数据,知道它可以写成矩阵
- 看到点积,知道它在衡量什么
- 看到矩阵乘法,知道它是在做批量变换
- 看到特征值,知道它和 PCA、主方向有关
如果你还觉得这章“太抽象”,最该先回头看什么?
最值得回看的通常不是最后面的特征值,而是最前面的:
- 向量怎么表示一个对象
- 矩阵怎么一次处理一批对象
- 点积到底在比较什么
因为这三件事一旦稳了,后面更抽象的内容会好很多。
新人和进阶学习者怎么读
新人第一次学这一章时,先抓住主线和最小可运行例子。你不需要一次理解所有细节,只要能说清楚这一章解决什么问题、输入输出是什么、最小项目怎么跑起来,就可以继续往后走。
有经验的学习者可以把这一章当成查漏补缺和工程化练习:关注边界条件、失败案例、评估方式、代码可复现性,以及它和前后阶段的连接。读完后最好能把本章内容沉淀到自己的作品 README 或实验记录里。
学习时间与难度建议
| 学习方式 | 建议投入 | 目标 |
|---|---|---|
| 快速浏览 | 20~30 分钟 | 看懂本章解决什么问题,知道后面会用到哪里 |
| 最小通关 | 1~2 小时 | 跑通一个最小例子,完成本章小项目出口 |
| 深入练习 | 半天~1 天 | 补充错误分析、对比实验或项目 README 记录 |
本章自测问题
| 自测问题 | 通过标准 |
|---|---|
| 这一章解决什么问题? | 能用一句话说明它在整门课里的位置 |
| 最小输入输出是什么? | 能说清楚例子需要什么输入,会产生什么结果 |
| 常见失败点在哪里? | 能列出至少一个报错、效果差或理解偏差的原因 |
| 学完后能沉淀什么? | 能把本章产出写进项目 README、实验记录或作品集 |
本章小项目出口
学完这一章后,建议完成一个最小练习:选择一个本章最核心的概念或工具,做出一个可以运行、可以截图、可以写进 README 的小成果。它不需要复杂,但要能说明输入是什么、处理过程是什么、输出结果是什么。
过关标准
这一章结束时,你应该能用自己的话说明本章解决什么问题、它和前后学习站有什么关系,并能完成本章小项目出口的最小版本。
如果你还能记录一次常见错误、一次调试过程或一次结果改进,就说明你已经不只是“看过内容”,而是在把这一章变成自己的项目经验。