4.4 实操:第 4 章完整数学工作坊
这一页把第 4 章变成一条可以跟着操作的练习线。这里不会要求你证明每个公式,而是用一个小脚本把最重要的数学直觉跑出来:向量用来比较相似度,概率用来描述不确定性,熵和损失用来衡量“意外程度”,梯度告诉参数该往哪里移动。
脚本只使用 Python 标准库。第一次运行不需要 NumPy、不需要绘图库,也不需要 Notebook 配置。它仍然会生成 CSV、SVG 图和 README,让你像检查一个小工程产物一样复盘数学。
每一步都按同一个节奏来:先看图,再运行代码,最后检查输出文件。如果公式很抽象,就问自己:它在表示什么对象、衡量什么不确定性,或者指导什么更新?
你会做出什么
完成后,你会得到一个名为 ch04_math_workshop_evidence 的文件夹,里面包含:
| 文件 | 它能证明什么 |
|---|---|
vector_similarity.csv | 你能用小向量计算点积、范数、余弦相似度和距离。 |
probability_simulation.csv | 你能模拟重复抽样,并看到抽样波动。 |
gradient_descent.csv | 你能逐步追踪参数更新过程。 |
math_cards.md | 你能把公式翻译成 AI 模型语言。 |
vector_similarity.svg | 你能看到向量比较,而不是只读公式。 |
probability_simulation.svg | 你能看到观测概率围绕期望概率波动。 |
gradient_descent.svg | 你能看到优化过程中 loss 下降。 |
README.md | 你能解释怎样复跑、怎样复盘。 |
图解检查点:整条路线
写代码前,先把这些图当作工作坊地图。
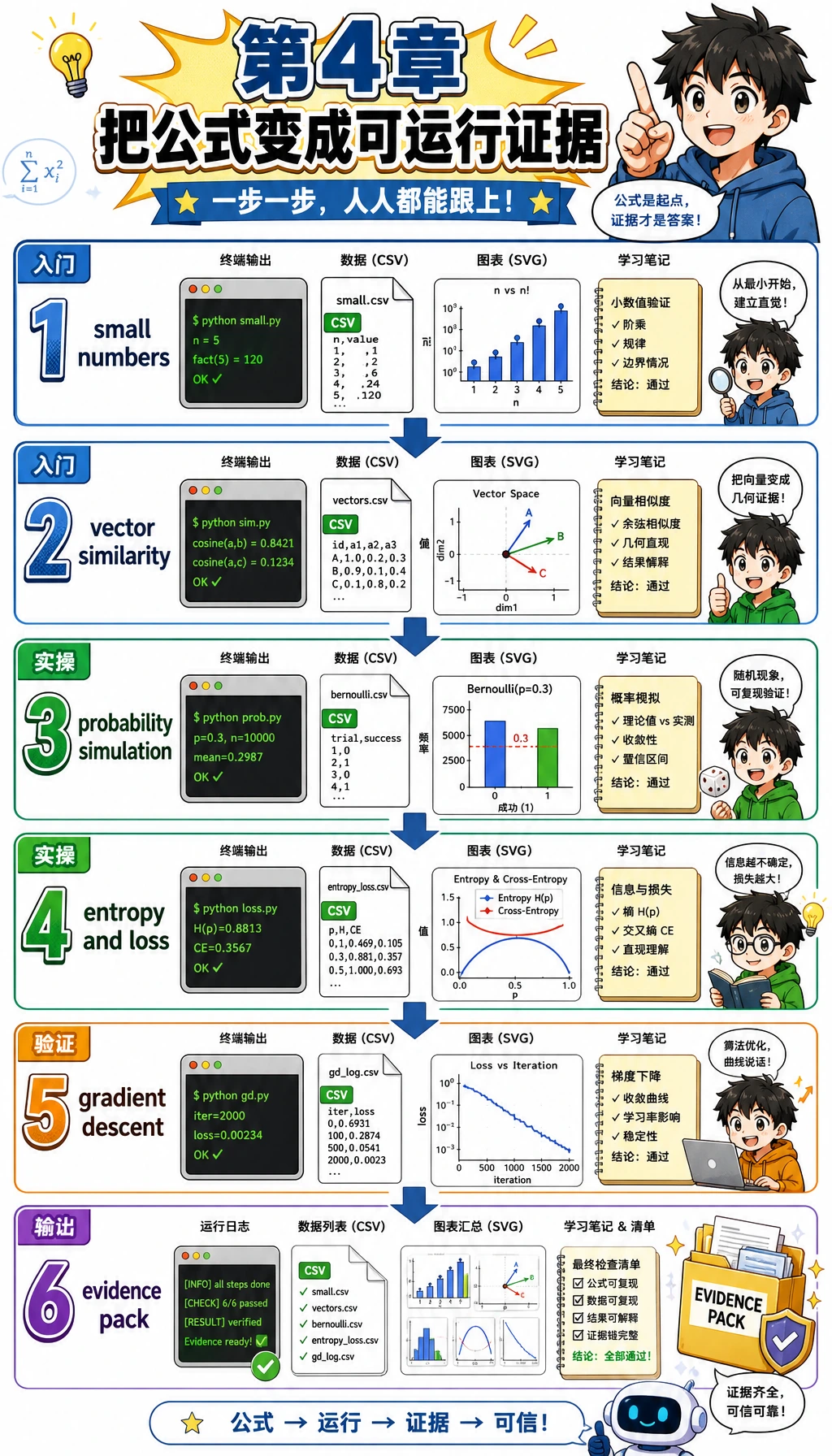
整条路线是:先用小数字,再写代码,最后留下可见证据。
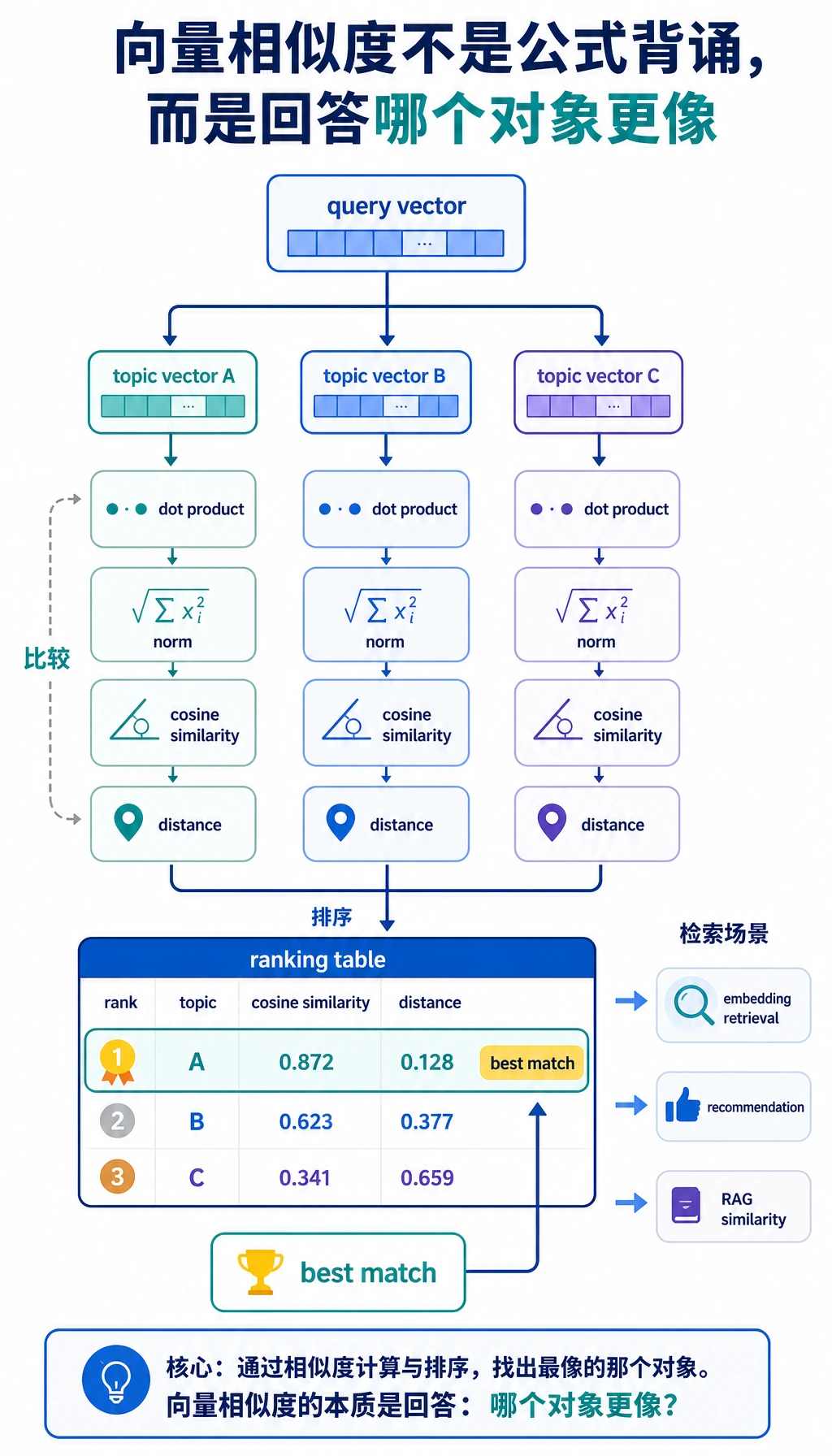
向量这一步只回答一个问题:哪个主题向量和查询向量最像?
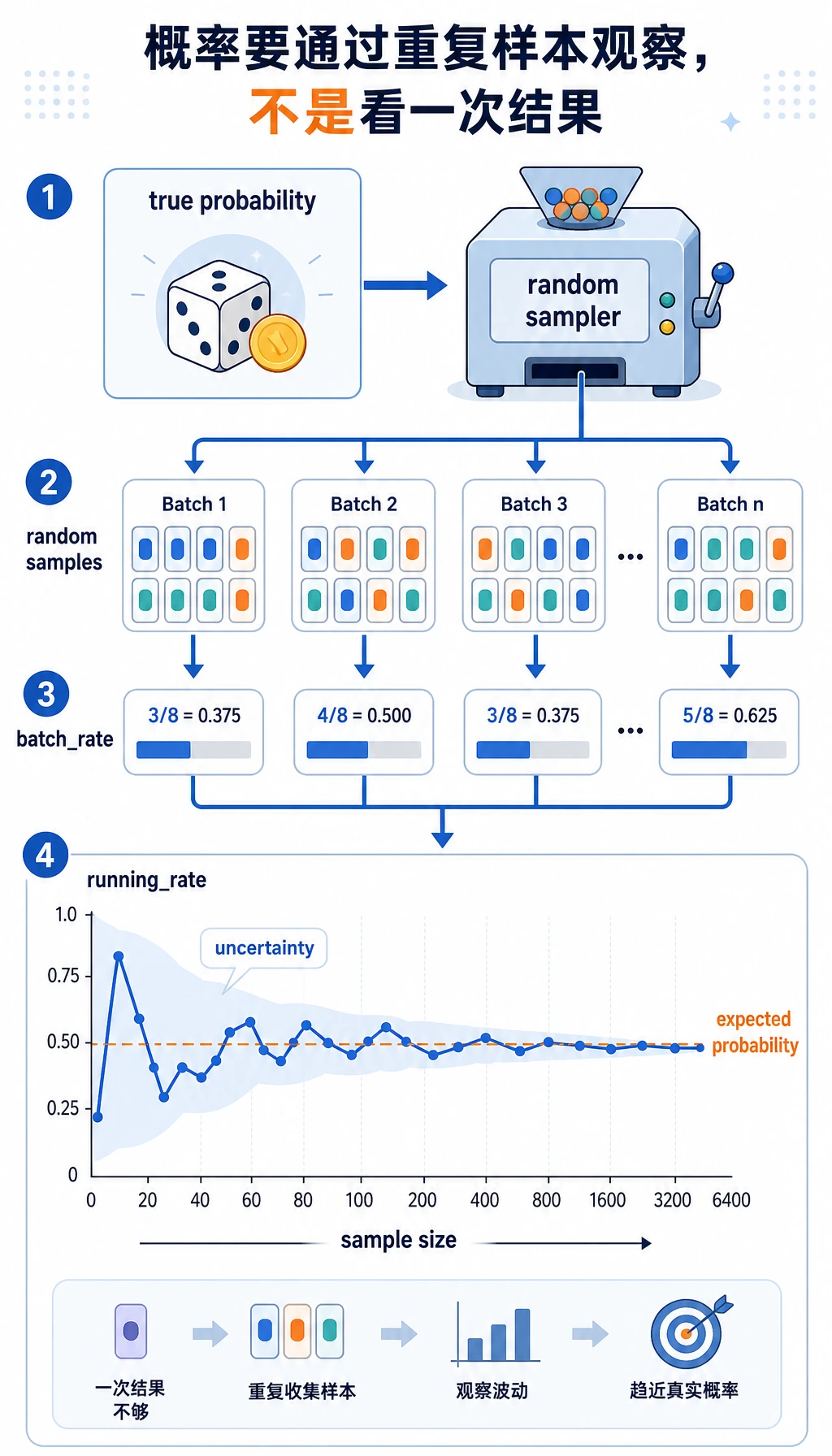
概率这一步说明:模型分数不是一个神奇真相,而是对很多样本中不确定性的总结方式。
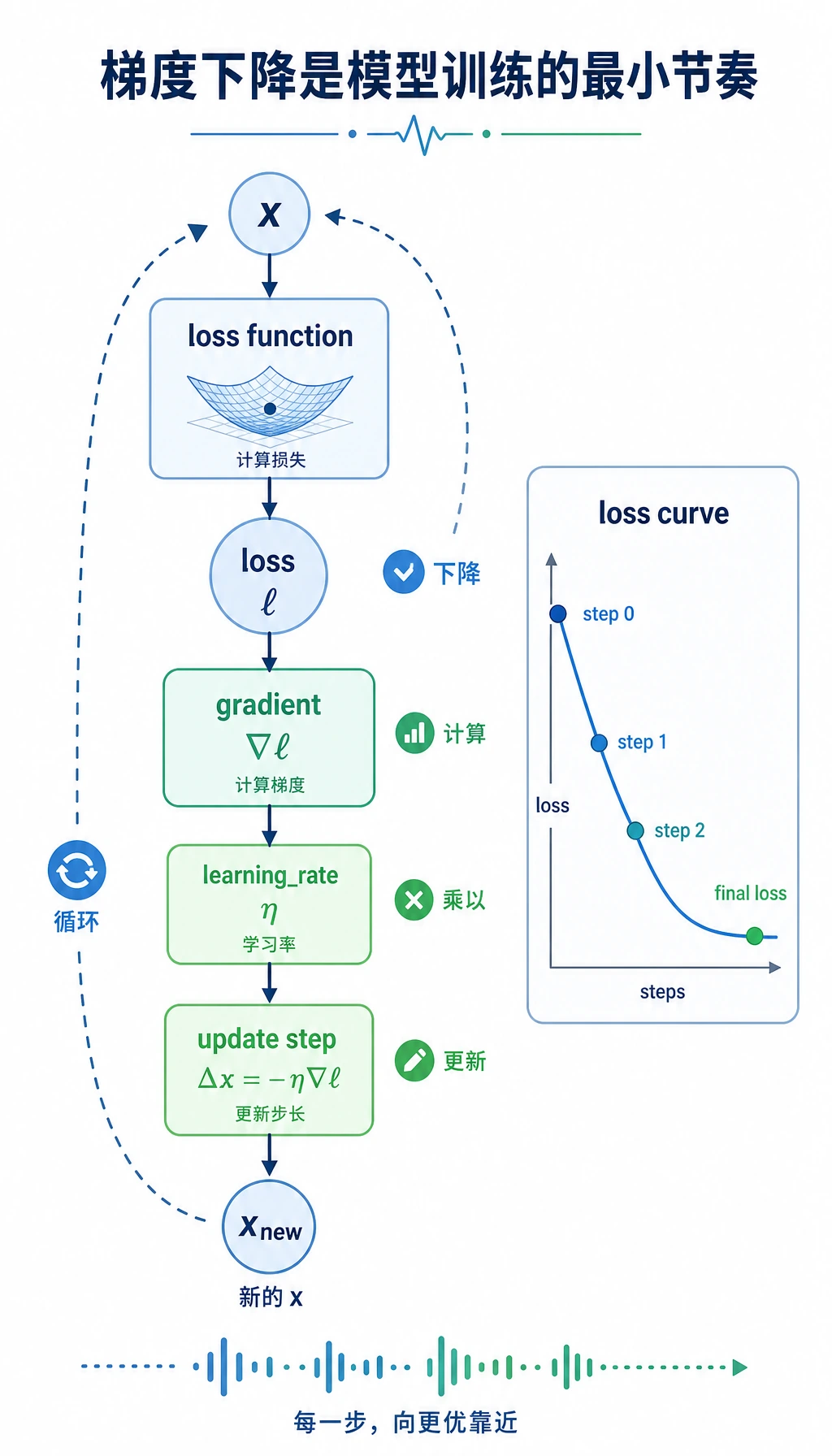
梯度下降这一步展示训练节奏:计算 loss,计算斜率,更新参数,然后重复。
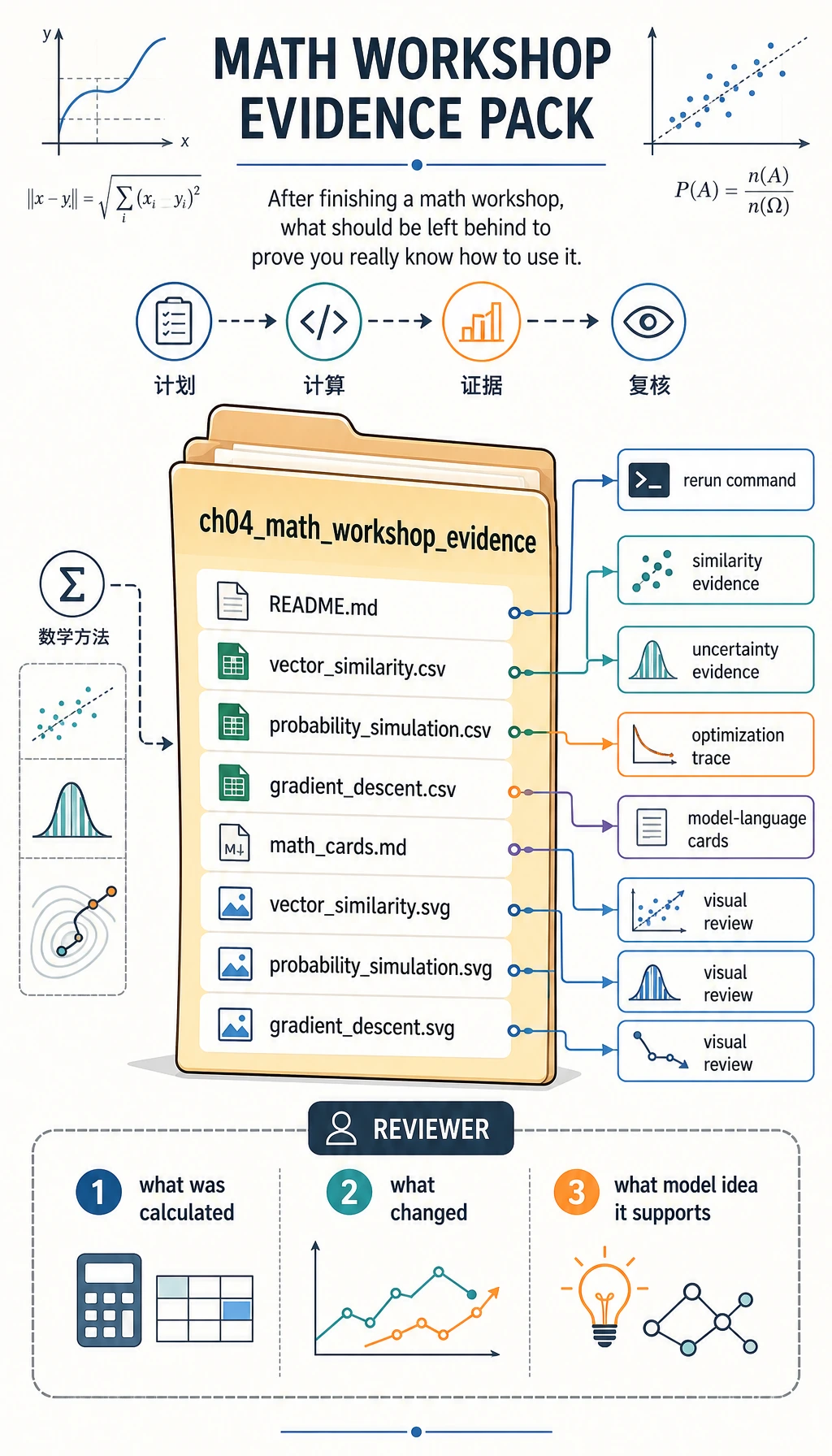
证据文件夹是最终学习产物。它让你不用靠记忆,也能回头复盘数学。
创建项目文件夹
先创建一个本地小文件夹:
mkdir ch04_math_hands_on
cd ch04_math_hands_on
然后创建文件 math_workshop.py。
粘贴并运行工作坊代码
把下面代码保存到 math_workshop.py:
import csv
import math
import random
from pathlib import Path
OUT_DIR = Path("ch04_math_workshop_evidence")
QUERY = ("ai_math_foundation", [1.0, 0.7, 0.2])
TOPICS = [
("vector_similarity", [1.0, 0.8, 0.1], "Embedding and retrieval need similarity."),
("probability", [0.2, 1.0, 0.7], "Classification confidence needs uncertainty."),
("gradient_descent", [0.8, 0.2, 1.0], "Training needs a direction of improvement."),
]
def dot(a, b):
return sum(x * y for x, y in zip(a, b))
def norm(v):
return math.sqrt(sum(x * x for x in v))
def cosine_similarity(a, b):
return dot(a, b) / (norm(a) * norm(b))
def euclidean_distance(a, b):
return math.sqrt(sum((x - y) ** 2 for x, y in zip(a, b)))
def run_vector_similarity():
query_name, query = QUERY
rows = []
for topic, vector, note in TOPICS:
rows.append(
{
"query": query_name,
"topic": topic,
"dot": round(dot(query, vector), 4),
"query_norm": round(norm(query), 4),
"topic_norm": round(norm(vector), 4),
"cosine_similarity": round(cosine_similarity(query, vector), 4),
"euclidean_distance": round(euclidean_distance(query, vector), 4),
"model_language": note,
}
)
return sorted(rows, key=lambda row: row["cosine_similarity"], reverse=True)
def run_probability_simulation(seed=42, batches=12, trials_per_batch=20, true_probability=0.65):
random.seed(seed)
rows = []
running_successes = 0
running_trials = 0
for batch in range(1, batches + 1):
successes = sum(1 for _ in range(trials_per_batch) if random.random() < true_probability)
running_successes += successes
running_trials += trials_per_batch
rows.append(
{
"batch": batch,
"batch_trials": trials_per_batch,
"batch_successes": successes,
"batch_rate": round(successes / trials_per_batch, 4),
"running_rate": round(running_successes / running_trials, 4),
"expected_probability": true_probability,
}
)
return rows
def entropy(probabilities):
return -sum(p * math.log2(p) for p in probabilities if p > 0)
def binary_cross_entropy(predicted_probability, actual_label):
p = min(max(predicted_probability, 1e-9), 1 - 1e-9)
return -(actual_label * math.log(p) + (1 - actual_label) * math.log(1 - p))
def run_information_examples():
confident = [0.9, 0.1]
uncertain = [0.5, 0.5]
return {
"entropy_confident_bits": round(entropy(confident), 4),
"entropy_uncertain_bits": round(entropy(uncertain), 4),
"loss_good_prediction": round(binary_cross_entropy(0.9, 1), 4),
"loss_bad_prediction": round(binary_cross_entropy(0.2, 1), 4),
}
def run_gradient_descent(start=3.5, learning_rate=0.2, steps=12):
def loss(x):
return (x - 1.4) ** 2 + 0.6
def gradient(x):
return 2 * (x - 1.4)
x = start
rows = []
for step in range(steps + 1):
current_loss = loss(x)
current_gradient = gradient(x)
rows.append(
{
"step": step,
"x": round(x, 6),
"loss": round(current_loss, 6),
"gradient": round(current_gradient, 6),
"learning_rate": learning_rate,
}
)
x = x - learning_rate * current_gradient
return rows
def write_csv(path, rows, fieldnames):
with path.open("w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(rows)
def scale(value, old_min, old_max, new_min, new_max):
if old_max == old_min:
return (new_min + new_max) / 2
ratio = (value - old_min) / (old_max - old_min)
return new_min + ratio * (new_max - new_min)
def write_vector_svg(path, rows):
width, height = 640, 420
bars = []
for index, row in enumerate(rows):
bar_width = int(row["cosine_similarity"] * 360)
y = 80 + index * 90
bars.append(
f'<text x="40" y="{y}" font-size="18">{row["topic"]}</text>'
f'<rect x="240" y="{y - 22}" width="{bar_width}" height="28" fill="#4f8cff" />'
f'<text x="{250 + bar_width}" y="{y}" font-size="16">{row["cosine_similarity"]}</text>'
)
svg = f'''<svg xmlns="http://www.w3.org/2000/svg" width="{width}" height="{height}" viewBox="0 0 {width} {height}">
<rect width="100%" height="100%" fill="#ffffff"/>
<text x="40" y="40" font-size="24" font-family="Arial">Vector similarity by cosine</text>
{''.join(bars)}
</svg>'''
path.write_text(svg, encoding="utf-8")
def write_probability_svg(path, rows):
width, height = 700, 420
points = []
for row in rows:
x = scale(row["batch"], 1, len(rows), 70, 640)
y = scale(row["running_rate"], 0.4, 0.9, 330, 80)
points.append((x, y))
polyline = " ".join(f"{x:.1f},{y:.1f}" for x, y in points)
expected_y = scale(rows[0]["expected_probability"], 0.4, 0.9, 330, 80)
circles = "".join(f'<circle cx="{x:.1f}" cy="{y:.1f}" r="5" fill="#f26d3d"/>' for x, y in points)
svg = f'''<svg xmlns="http://www.w3.org/2000/svg" width="{width}" height="{height}" viewBox="0 0 {width} {height}">
<rect width="100%" height="100%" fill="#ffffff"/>
<text x="40" y="40" font-size="24" font-family="Arial">Running probability estimate</text>
<line x1="70" y1="{expected_y:.1f}" x2="640" y2="{expected_y:.1f}" stroke="#888" stroke-dasharray="8 6"/>
<text x="70" y="{expected_y - 10:.1f}" font-size="14">expected p=0.65</text>
<polyline points="{polyline}" fill="none" stroke="#f26d3d" stroke-width="3"/>
{circles}
</svg>'''
path.write_text(svg, encoding="utf-8")
def write_gradient_svg(path, rows):
width, height = 700, 420
losses = [row["loss"] for row in rows]
points = []
for row in rows:
x = scale(row["step"], 0, rows[-1]["step"], 70, 640)
y = scale(row["loss"], min(losses), max(losses), 330, 80)
points.append((x, y))
polyline = " ".join(f"{x:.1f},{y:.1f}" for x, y in points)
circles = "".join(f'<circle cx="{x:.1f}" cy="{y:.1f}" r="5" fill="#2f9e44"/>' for x, y in points)
svg = f'''<svg xmlns="http://www.w3.org/2000/svg" width="{width}" height="{height}" viewBox="0 0 {width} {height}">
<rect width="100%" height="100%" fill="#ffffff"/>
<text x="40" y="40" font-size="24" font-family="Arial">Gradient descent lowers loss</text>
<polyline points="{polyline}" fill="none" stroke="#2f9e44" stroke-width="3"/>
{circles}
</svg>'''
path.write_text(svg, encoding="utf-8")
def write_math_cards(path, info_examples):
content = f"""# Math Cards
## Vector
Model language: a vector is a small numeric description of an object.
Workshop evidence: `vector_similarity.csv` shows which topic vector is closest to the query.
## Probability
Model language: probability is a controlled way to talk about uncertainty.
Workshop evidence: `probability_simulation.csv` shows observed rates moving around the expected rate.
## Entropy and Loss
Model language: entropy measures uncertainty; loss measures how painful a prediction mistake is.
Confident entropy: {info_examples['entropy_confident_bits']} bits.
Uncertain entropy: {info_examples['entropy_uncertain_bits']} bits.
Good prediction loss: {info_examples['loss_good_prediction']}.
Bad prediction loss: {info_examples['loss_bad_prediction']}.
## Gradient
Model language: a gradient tells a parameter which direction changes the loss fastest.
Workshop evidence: `gradient_descent.csv` shows x moving toward the low-loss point.
"""
path.write_text(content, encoding="utf-8")
def write_readme(path, best_topic, final_gradient_row):
content = f"""# Chapter 4 Math Workshop Evidence
Run command: `python math_workshop.py`
Best vector match: `{best_topic}`.
Final gradient descent point: x={final_gradient_row['x']}, loss={final_gradient_row['loss']}.
Review order:
1. Open `vector_similarity.csv`.
2. Open `probability_simulation.csv`.
3. Open `gradient_descent.csv`.
4. Read `math_cards.md`.
5. Inspect the SVG files.
"""
path.write_text(content, encoding="utf-8")
def main():
OUT_DIR.mkdir(exist_ok=True)
vector_rows = run_vector_similarity()
probability_rows = run_probability_simulation()
info_examples = run_information_examples()
gradient_rows = run_gradient_descent()
write_csv(
OUT_DIR / "vector_similarity.csv",
vector_rows,
["query", "topic", "dot", "query_norm", "topic_norm", "cosine_similarity", "euclidean_distance", "model_language"],
)
write_csv(
OUT_DIR / "probability_simulation.csv",
probability_rows,
["batch", "batch_trials", "batch_successes", "batch_rate", "running_rate", "expected_probability"],
)
write_csv(
OUT_DIR / "gradient_descent.csv",
gradient_rows,
["step", "x", "loss", "gradient", "learning_rate"],
)
write_vector_svg(OUT_DIR / "vector_similarity.svg", vector_rows)
write_probability_svg(OUT_DIR / "probability_simulation.svg", probability_rows)
write_gradient_svg(OUT_DIR / "gradient_descent.svg", gradient_rows)
write_math_cards(OUT_DIR / "math_cards.md", info_examples)
write_readme(OUT_DIR / "README.md", vector_rows[0]["topic"], gradient_rows[-1])
print("STEP 1: Vector similarity")
print(f"best_match={vector_rows[0]['topic']} cosine={vector_rows[0]['cosine_similarity']}")
print("\nSTEP 2: Probability simulation")
print(f"final_running_rate={probability_rows[-1]['running_rate']} expected={probability_rows[-1]['expected_probability']}")
print("\nSTEP 3: Entropy and loss")
print(f"confident_entropy={info_examples['entropy_confident_bits']} uncertain_entropy={info_examples['entropy_uncertain_bits']}")
print(f"good_loss={info_examples['loss_good_prediction']} bad_loss={info_examples['loss_bad_prediction']}")
print("\nSTEP 4: Gradient descent")
print(f"start_loss={gradient_rows[0]['loss']} final_x={gradient_rows[-1]['x']} final_loss={gradient_rows[-1]['loss']}")
print("\nSTEP 5: Evidence files")
for name in [
"README.md",
"vector_similarity.csv",
"probability_simulation.csv",
"gradient_descent.csv",
"math_cards.md",
"vector_similarity.svg",
"probability_simulation.svg",
"gradient_descent.svg",
]:
print((OUT_DIR / name).as_posix())
if __name__ == "__main__":
main()
运行:
python math_workshop.py
如果你的系统使用 python3,运行:
python3 math_workshop.py
预期输出
你应该看到接近下面的输出:
STEP 1: Vector similarity
best_match=vector_similarity cosine=0.9944
STEP 2: Probability simulation
final_running_rate=0.6833 expected=0.65
STEP 3: Entropy and loss
confident_entropy=0.469 uncertain_entropy=1.0
good_loss=0.1054 bad_loss=1.6094
STEP 4: Gradient descent
start_loss=5.01 final_x=1.404571 final_loss=0.600021
STEP 5: Evidence files
ch04_math_workshop_evidence/README.md
ch04_math_workshop_evidence/vector_similarity.csv
ch04_math_workshop_evidence/probability_simulation.csv
ch04_math_workshop_evidence/gradient_descent.csv
ch04_math_workshop_evidence/math_cards.md
ch04_math_workshop_evidence/vector_similarity.svg
ch04_math_workshop_evidence/probability_simulation.svg
ch04_math_workshop_evidence/gradient_descent.svg
如果你改了随机种子、学习率或迭代次数,数字略有不同是正常的。
怎样阅读这些文件
先打开 vector_similarity.csv。不要只看最高分,也要比较 dot、cosine_similarity 和 euclidean_distance。真正重要的习惯是把指标和问题连起来:你关心方向相同、长度相近,还是两者都关心?
再打开 probability_simulation.csv。观察 batch_rate 和 running_rate。单个 batch 可能波动很大,但累计比例会更稳定。这就是为什么模型评估里样本量、评估集和置信度都很重要。
最后打开 gradient_descent.csv。顺着 x、loss 和 gradient 看。刚开始梯度较大,随着 x 接近低 loss 点,梯度会变小。这就是模型训练的小数字版本。
每个概念如何翻译成模型语言
| 概念 | 公式里是什么 | 模型语言里是什么 | 工作坊文件 |
|---|---|---|---|
| Vector | 一串数字 | 对对象的紧凑数值描述 | vector_similarity.csv |
| Dot product | 对应分量相乘再相加 | 两个方向有多一致 | vector_similarity.csv |
| Cosine similarity | 点积除以两个长度 | 去掉长度影响后的相似度 | vector_similarity.csv |
| Probability | 0 到 1 的数 | 事件有多可能、模型有多不确定 | probability_simulation.csv |
| Entropy | 期望惊讶程度 | 一个分布有多不确定 | math_cards.md |
| Cross-entropy loss | 对错误自信的惩罚 | 预测错得有多痛 | math_cards.md |
| Gradient | 变化最快的方向 | 参数应该往哪里移动 | gradient_descent.csv |
新人常见错误排查
| 现象 | 可能原因 | 处理方式 |
|---|---|---|
python: command not found | 你的系统使用 python3 | 运行 python3 math_workshop.py |
| SVG 文件打开后像文本 | 编辑器打开了 SVG 源码 | 用浏览器打开它 |
| 概率输出略有不同 | 你改了随机种子或试验次数 | 保持 seed=42 可得到文档中的结果 |
| 梯度下降跳得太猛 | 学习率太大 | 试试 learning_rate=0.05 |
| 梯度下降走得太慢 | 学习率太小 | 先看稳定版本,再试 learning_rate=0.3 |
| 数字看起来没意义 | 你在脱离模型问题读数字 | 先问:这是相似度、不确定性,还是更新方向? |
跟做练习
- 把
QUERY改成[0.1, 1.0, 0.7]。哪个主题最相似?为什么? - 把
true_probability从0.65改成0.5。累计比例会怎样变化? - 把
learning_rate从0.2改成0.05。loss 还会下降吗?速度变快还是变慢? - 在
math_cards.md里新增一节,用自己的话解释矩阵乘法。 - 给每个文件写一句话,说明它怎样连接到后续章节:机器学习、深度学习、RAG 或 LLM。
退出检查清单
- 我能在本地跑通这个工作坊。
- 我能解释为什么向量相似度可以支持检索或推荐。
- 我能解释为什么概率需要重复样本,而不是一次幸运结果。
- 我能解释为什么不确定分布的熵更大。
- 我能解释为什么梯度下降会让参数小步更新。
- 我保存了证据文件夹,并能解释每个文件证明了什么。
如果六项都能勾上,第 4 章就不再只是公式章节,而是一套可运行的模型直觉工具箱。