12.3.4 デジタルヒューマン技術【選択】
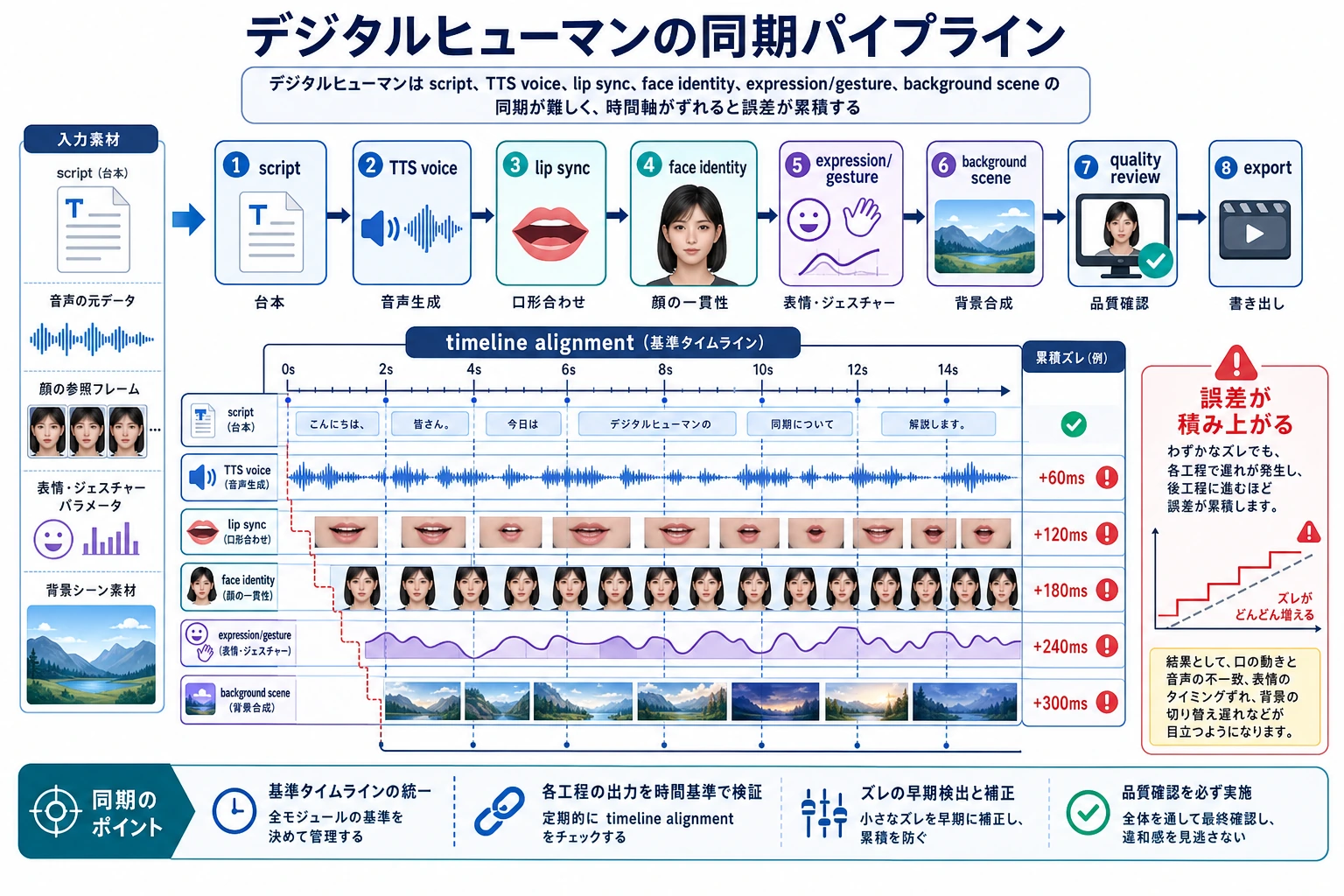
デジタルヒューマンの体験は、単独のモデルではなく、複数モジュールの同期で決まります。図を見るときは、台本、TTS、口形同期、表情や動き、本人らしさの一貫性、検閲、書き出しのあいだで、誤差がどのように段階的に伝わるかに注目してください。
多くの人はデジタルヒューマンを見ると、最初にこう思います。
「これはとても強力な動画生成モデルなのでは?」
でも、より正確な理解はたいてい次のようになります。
デジタルヒューマンは、むしろ複数モジュールが協力するシステムに近い。
なぜなら、実際には次のようなものを同時に扱う必要があるからです。
- テキスト
- 音声
- 口形
- 表情
- 人物レンダリング
学習目標
- デジタルヒューマンシステムの最も重要なモジュール構成を理解する
- それがなぜ単なる「動画生成」ではないのかを理解する
- 最小限のデジタルヒューマンのワークフローを読み取れるようになる
- デジタルヒューマンプロジェクトの複雑さの原因に対する正しい直感を身につける
まずは全体図をつくろう
デジタルヒューマンシステムは、「テキスト / 音声 / 口形 / レンダリング」の4層で考えると理解しやすいです。
この節で本当に解決したいのは、次の2点です。
- なぜデジタルヒューマンは単一モデルの問題ではないのか
- なぜ本質的にマルチモジュール協調システムに近いのか
一、デジタルヒューマンは何をしているのか?
いちばんシンプルな理解
デジタルヒューマンシステムが通常やりたいことは、次のようなものです。
- 文字列や音声を与える
- 仮想人物が「本物の人のように」話すように見せる
これは動画生成に見えるけれど、なぜ完全には同じではないのか?
なぜなら、デジタルヒューマンでは単に「動画を生成する」だけでなく、次の点も満たす必要があるからです。
- 話している内容が合っている
- 口の動きが合っている
- 人物の本人らしさが安定している
- 表情や動きが不自然すぎない
つまり、普通の動画生成よりも、次の点を強く重視します。
人物の一貫性 + 音声駆動の一貫性。
初学者にとってわかりやすい全体のたとえ
デジタルヒューマンシステムは、次のように考えるとわかりやすいです。
- 仮想司会者の制作ライン
テキストは台本、
TTS はナレーション、
口形同期は口や表情の動き、
レンダリングは最後にキャラクターを本当に映像として仕上げる工程です。
このたとえは初心者にとても向いています。なぜなら、次のことを先に掴めるからです。
- デジタルヒューマンは「何もないところから突然動画が出てくる」わけではない
- 複数のモジュールが一緒に内容を演じて動画にしている
二、なぜデジタルヒューマンシステムは本質的に「マルチモジュール・パイプライン」なのか?
大まかなワークフローは、通常このようになります。
- テキストを生成する、またはテキストを受け取る
- TTS で音声を生成する
- 音声に基づいて口形 / 顔の動きを駆動する
- 仮想の人物像をレンダリングする
pipeline = ["text", "tts", "lip_sync", "avatar_render"]
print(pipeline)
期待される出力:
['text', 'tts', 'lip_sync', 'avatar_render']
これはチェックリストとして読めます。どれか1つの段階が弱いと、他が動いていても最終的なデジタルヒューマンは不自然に見えます。

このシンプルなリストの一番大事な役割は、次の点を見せることです。
デジタルヒューマンは単一のブラックボックスではなく、つながった処理の連鎖である。
初学者がまず覚えるとよいモジュール分担表
| モジュール | まず覚えるべき役割 |
|---|---|
| テキスト / 台本 | 何を話すかを決める |
| 音声生成 | どう聞こえるかを決める |
| 口形駆動 | 口の形がついていけるかを決める |
| キャラクターレンダリング | 画面の中でその人が最終的にどう見えるかを決める |
この表は初心者にとても向いています。なぜなら、デジタルヒューマンという「かっこいい言葉」を、具体的なモジュールに分解して見られるようになるからです。
三、最も重要なステップ:口形同期(lip sync)
なぜこれがデジタルヒューマン体験の中心なのか?
ユーザーは「口の動きが合っていない」ことに非常に敏感だからです。
音声が良く、見た目がきれいでも、口形が明らかに合っていないと、システム全体がとても不自然に見えます。
これは本質的に何をしているのか?
やっていることは単純で、
- 音声を入力する
- それに対応する口の動きを予測する
というものです。
これはデジタルヒューマンシステムの中でも、非常に典型的な「音声で視覚を駆動する」タスクです。
四、なぜデジタルヒューマンは「本人らしさの一貫性」に対する要求が高いのか?
普通の動画生成では、ユーザーは映像全体を見ることが多いです。
一方、デジタルヒューマンでは、しばしば次の1つの主体に注目します。
- 同じ顔
- 同じキャラクター
- 同じブランドイメージ
そのため、デジタルヒューマンのタスクは本質的に次の要求が高くなります。
- 本人らしさの安定
- 細部の一貫性
これが、デジタルヒューマンシステムが次の点を特に重視する理由でもあります。
- 専用キャラクターモデリング
- アバター駆動
- talking head の制御
五、最小限の「デジタルヒューマンシステム状態」の例
digital_human_request = {
"text": "AI フルスタックコースへようこそ。",
"speaker": "female_01",
"avatar": "teacher_avatar_v1",
"style": "formal"
}
print(digital_human_request)
期待される出力:
{'text': 'AI フルスタックコースへようこそ。', 'speaker': 'female_01', 'avatar': 'teacher_avatar_v1', 'style': 'formal'}
このリクエストはすでにテキストだけではありません。声、アバター、表現スタイルを固定することで、同じ内容を一貫したキャラクターの演技にできます。
この例が教えてくれるのは、次のことです。
- 入力はテキストだけではない
- システムには、キャラクター、音声スタイル、表現方法も必要
だからこそ、デジタルヒューマンのプロジェクトは単一モデルのデモというより、むしろ「製品システム」に近いのです。
六、より完全なワークフローの直感
たとえば、1本のデジタルヒューマン動画の生成プロセスは、ざっくり次のように書けます。
- テキスト -> 音声
- 音声 -> 口形 / 顔の動き
- 人物テンプレート + 動き -> 動画フレーム
workflow = {
"input_text": "AI フルスタックコースへようこそ。",
"audio": "generated_speech.wav",
"face_motion": "lip_sync_features",
"output_video": "teacher_avatar_video.mp4"
}
print(workflow)
期待される出力:
{'input_text': 'AI フルスタックコースへようこそ。', 'audio': 'generated_speech.wav', 'face_motion': 'lip_sync_features', 'output_video': 'teacher_avatar_video.mp4'}
出力動画は最後の成果物であり、システム全体ではありません。その前に音声と動きの特徴が作られ、それらが同期している必要があります。
このコードはデジタルヒューマンを実装しているわけではありません。
でも、次の大事な事実をつかむ助けになります。
デジタルヒューマンは、「テキスト、音声、視覚レンダリング」を段階的に変換するシステムである。
初学者がまず覚えるとよいプロジェクト確認表
| まず何を確認するべきか | なぜ重要か |
|---|---|
| 音声が自然か | 声の自然さは擬人化の印象に直結する |
| 口形が追従しているか | ユーザーは口のずれにとても敏感 |
| キャラクターが安定しているか | 本人らしさが不安定だと違和感が大きい |
| スタイルが一貫しているか | 音声、人物、文章が別々のシステムのように見えてはいけない |
この表は初心者に向いています。なぜなら、「デジタルヒューマンがなんだか変に見える」という問題を、原因ごとに分けて考えられるようになるからです。
七、なぜデジタルヒューマンプロジェクトは想像以上に難しいのか?
モジュール間の誤差が段階的に積み重なる
たとえば、次のようなことが起きます。
- テキスト生成が不自然
- TTS の音声が硬い
- 口形同期が少しずれる
- 表情も少し不自然
すると、最後の見た目はかなり悪くなります。
人間は顔にとても敏感
人は「顔」と「話している口の動き」のずれに非常に敏感です。
そのため、デジタルヒューマンは普通の生成タスクよりも、通すのが難しいことがよくあります。
八、デジタルヒューマンはなぜプロダクト価値が高いのか?
なぜなら、次のような用途にとても向いているからです。
- 教育の説明
- カスタマーサポートの案内
- マーケティングの司会
- 多言語の説明
その価値は「技術がすごい」ことそのものよりも、むしろ次の点にあります。
言語コンテンツを、より臨場感のある表現形式にできる。
九、とても重要なエンジニアリング判断
多くのデジタルヒューマン製品は、「完全に本物らしいこと」を目指すというより、次のバランスを重視します。
- 十分に安定している
- 十分に自然に見える
- 十分に低コストである
これはとても重要です。なぜなら、極端に高いリアルさを追いかけると、コストと複雑さが一気に増えるからです。
そのため、実際には次のようなものをよく見かけます。
- カートゥーン調の avatar
- セミリアルな表現
- 軽量な talking head
その背景には、工程上・製品上のトレードオフがあることが多いです。
これをプロジェクトやシステム設計にするなら、何を見せるのが一番よいか
一番見せるべきなのは、たいてい次のような点です。
- 「デジタルヒューマン動画を作りました」だけではないこと
- テキストがどのようにワークフローに入るか
- 音声、口形、レンダリングがそれぞれどのモジュールに担当されているか
- どの部分で失真しやすいか
- 安定性、コスト、リアルさのあいだでどう取捨選択したか
こうすると、相手にも次のことが伝わりやすくなります。
- あなたはデジタルヒューマンのシステム工学を理解している
- 単なる動画生成 demo ではない
まとめ
この節で最も大事なのは、「デジタルヒューマン」という言葉を覚えることではなく、次の理解です。
デジタルヒューマンシステムは、本質的にテキスト、音声、動き、人物レンダリングを組み合わせたマルチモジュールシステムである。
本当に難しいのは、単に動画を生成することではありません。
それらのモジュールが最後に、1人の統一感があり信頼できる人物表現として見えるようにすることです。
練習
- 自分の言葉で説明してみましょう:なぜデジタルヒューマンは「普通の動画生成」と単純には考えられないのか?
- 考えてみましょう:デジタルヒューマンシステムの中で、なぜ口形同期は特に重要なのか?
- 教育用の仮想講師を作るなら、どのモジュールが必須ですか?
- 自分の言葉で説明してみましょう:なぜ多くのデジタルヒューマン製品は「最高のリアルさ」よりも「安定性とコスト」を重視するのか?