9.4.2 メモリシステムの概要
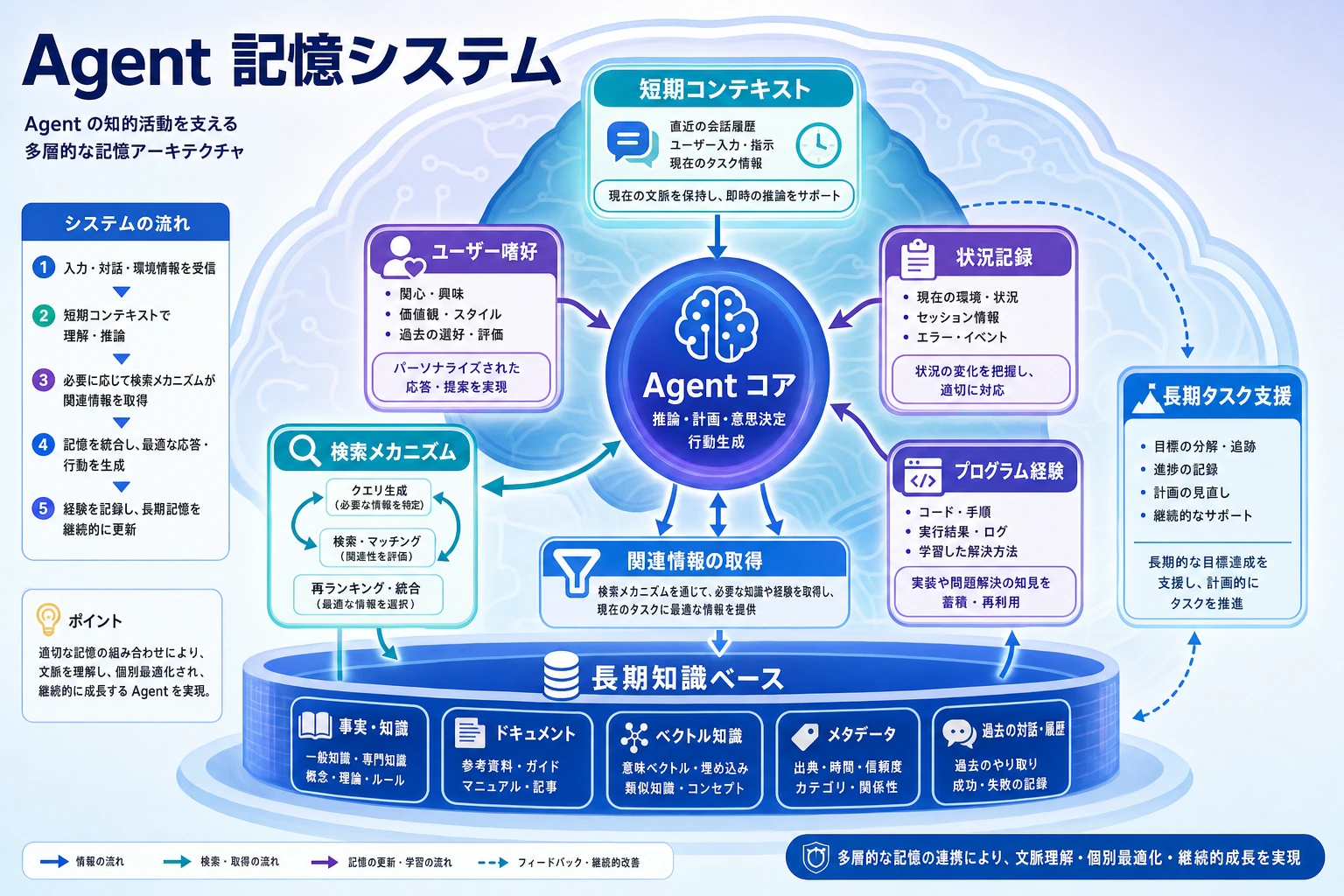
多くの Agent システムは、最初はとても賢く見えます。けれど、タスクが長くなったり、やり取りの回数が増えたりすると、ある本質的な問題が見えてきます。
直前まで何をしていたのかを覚えていない。
そのため、メモリシステムは「あると便利な追加機能」ではなく、Agent を一回きりの回答機から継続的なタスクシステムへ進化させるための重要な層です。
学習目標
- なぜ Agent に記憶が必要なのかを、コンテキストウィンドウだけではない視点で理解する
- 短期・長期・エピソード・手続き記憶の違いを区別する
- 最小構成の多層メモリ構造を読み取れるようになる
- 「記憶は多ければ多いほど良いわけではない」という感覚を身につける
- これからの各節が、どの層の問題を解いているのかを把握する
まずは初学者向け / その後に発展理解
初学者の方は、この節ではまず一言だけ押さえてください。Agent の記憶とは、会話履歴をすべてモデルに入れ直すことではありません。現在のタスク、長期的な好み、過去の経験、再利用できる手順を階層的に保存し、必要なときに取り出すことです。
すでに Agent プロジェクトを作ったことがある方は、次の点も意識してみてください。どの情報を長期記憶に書き込むべきか、いつ読み出すべきか、短期ノイズが長期の事実を汚染しないようにするにはどうするか、そして記憶が本当にタスク成功率を改善しているのか、という点です。
なぜ Agent に記憶が必要なのか?
記憶がないと、毎回再起動しているようなものになる
ユーザーと Agent の会話が次のようになったとします。
- 「返金ポリシーを確認したいです」
- 「主に期間を見たいです」
- 「もしすでに 30% 学んでいたら、返金できますか?」
もしシステムが毎回最後の一文だけを見るなら、
「もしすでに 30% 学んでいたら、返金できますか?」
という発話だけでは、重要な前提がたくさん抜け落ちてしまいます。
では、メモリシステムは何を解決するのか?
解決したいのは次のようなことです。
- 現在のタスクをどう一貫して進めるか
- 過去の情報をどう選んで残すか
- これからの判断に、その残した情報をどう使うか
一言でいうと、
メモリシステムは、Agent が「毎回最初からやり直す」ような忘却感に抵抗するための仕組みです。
記憶は「履歴を全部入れること」ではない
よくある誤解
記憶と聞くと、多くの人はまず次のように考えます。
- 過去のメッセージを全部保存する
- 必要なときに全部モデルへ入れる
しかし、これはたいてい次の問題を引き起こします。
- token コストの増大
- レイテンシの上昇
- ノイズの増加
- 本当に重要な情報が埋もれる
メモリシステムが本当にやるべきこと
メモリシステムは、単に「もっと多く保存する」ことではありません。むしろ、
限られた予算の中で、最も価値のある情報を残し、適切な形で整理すること
が重要です。
これは人間の記憶にもよく似ています。
- すべてをそのまま覚えているわけではない
- 圧縮し、選び、要約している
まずは全体の地図を作る
代表的な記憶の階層
| 記憶の種類 | たとえ | 主に解決すること |
|---|---|---|
| 短期記憶 | 作業台 | 現在のタスクの文脈 |
| 長期記憶 | 収納庫 | 回をまたいで安定している情報 |
| エピソード記憶 | タスクの経験 | 何が起きたか |
| 手続き記憶 | 操作マニュアル | その種のタスクをどう進めるか |
まずは一言で覚える
- 短期記憶: 今回のタスクで何が起きているか
- 長期記憶: このユーザー / このシステムが長期的にどういうものか
- エピソード記憶: 過去のある具体的な出来事の記録
- 手続き記憶: 再利用できる作業フロー
この 4 つは、いつも全部必要というわけではありませんが、とても実用的な考え方の枠組みになります。
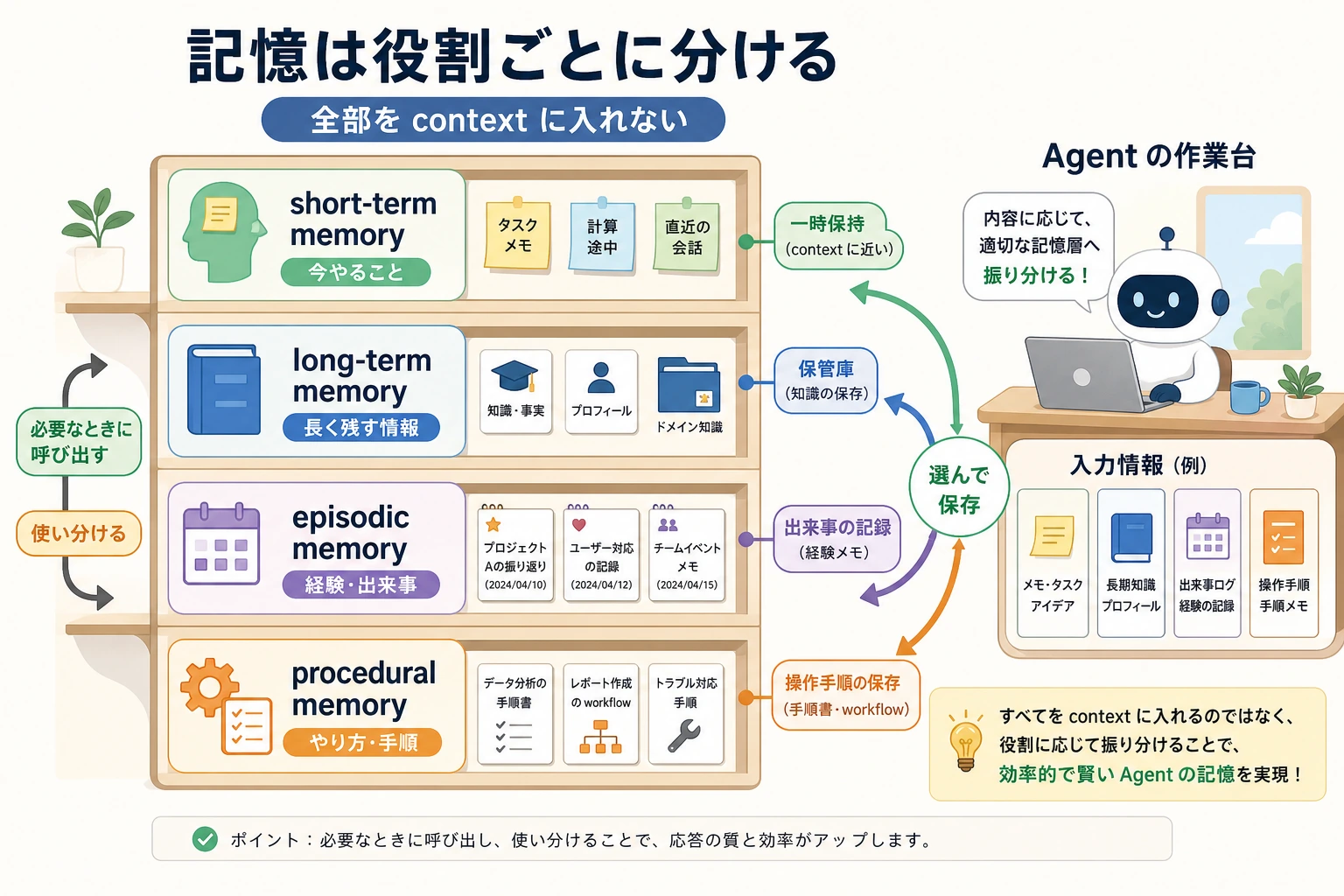
この図は、4 種類すべての記憶を一度に作れという意味ではありません。むしろ「この情報はどこに置くべきか」を判断するためのものです。現在のタスクは short-term、安定した好みは long-term、1 回きりの経験は episodic、再利用できる手順は procedural に置きます。
短期記憶: 現在のタスクの作業領域
ふつう何を保存するのか?
- 最近の数ターンの会話
- 現在のタスク目標
- 中間のツール結果
- どこまで実行したか
なぜ最初に重要なのか?
ユーザーが最もすぐに失敗として感じるのは、短期記憶のミスです。
- システムが直前の発言を忘れる
- さっき調べた結果をまた調べる
- 1 つ前に決めたことを次のステップでひっくり返す
だからこそ、次の節ではまず短期記憶を詳しく扱います。
長期記憶: 回をまたいでも価値がある情報
ふつう何を保存するのか?
たとえば次のような情報です。
- ユーザーの好み: 回答は簡潔が好き
- ユーザーの背景: Python 初学者
- プロジェクトの背景: 今 RAG システムを作っている
短期記憶との最大の違い
短期記憶は「今回のタスク」のため。
長期記憶は「次に似た状況が来たときにも使える」ためです。
つまり長期記憶は、現在の作業台というより、保管された記録に近いものです。
エピソード記憶と手続き記憶とは?
エピソード記憶(episodic memory)
次のように理解できます。
過去に起きた、1 回の具体的な経験。
たとえば、
- 「前回ユーザーが返金を質問したとき、学習進捗が 7 日を超えていて返金不可だった」
のような記録です。
これは、時間や出来事の背景を持った 1 つの記録に近いものです。
手続き記憶(procedural memory)
次のように理解できます。
すでに役に立つと分かっている作業手順のまとまり。
たとえば、
- 「返金の問い合わせを処理するときは、まず注文を確認し、次にポリシーを確認し、最後に条件を判断する」
のようなものです。
これは単発の出来事というより、経験から得た手順です。
なぜこの 2 つを分けるのか?
なぜなら、
- エピソード記憶は「何を経験したか」
- 手続き記憶は「どうやるかを学んだか」
という違いがあるからです。
この違いは、Agent の再利用性に直接影響します。
最小構成の多層メモリ例
次の例はシンプルですが、多層メモリ構造の感覚をつかむのに役立ちます。
memory = {
"short_term": {
"messages": ["返金ポリシーを確認したいです", "主に期間を見たいです"],
"current_goal": "返金資格を判断する"
},
"long_term": {
"user_preference": "回答は簡潔にする",
"skill_level": "Python 初学者"
},
"episodic": [
"前回返金問題を処理したとき、ユーザーは学習進捗が高すぎて返金できなかった"
],
"procedural": {
"refund_workflow": ["注文を確認", "ポリシーを確認", "資格を判断", "結論を返す"]
}
}
print(memory)
期待される出力:
{'short_term': {'messages': ['返金ポリシーを確認したいです', '主に期間を見たいです'], 'current_goal': '返金資格を判断する'}, 'long_term': {'user_preference': '回答は簡潔にする', 'skill_level': 'Python 初学者'}, 'episodic': ['前回返金問題を処理したとき、ユーザーは学習進捗が高すぎて返金できなかった'], 'procedural': {'refund_workflow': ['注文を確認', 'ポリシーを確認', '資格を判断', '結論を返す']}}
このコードが本当に教えていること
このコードが教えているのは、
記憶は 1 つのバケツではなく、役割の違う複数の層からなる情報構造だ
ということです。
もしすべてを 1 つのテキストのかたまりにしてしまうと、システムはだんだん使いにくくなります。
メモリシステム設計でよくあるトレードオフ
どれくらい保存するか?
- 少なすぎる: システムが忘れやすい
- 多すぎる: システムが混乱しやすく、コストも上がる
原文で残すか、要約するか?
- 原文: 細部まで残せる
- 要約: コンテキストを節約できる
いつ書き込み、いつ読み出すか?
すべての情報を長期記憶に書く必要はありません。
また、毎回の回答で長期記憶を全部読み出す必要もありません。
つまり、メモリシステムで大事なのは「保存」だけではなく、
- 書き込み戦略
- 検索戦略
- クリーニング戦略
です。
とても重要な実装上の注意
メモリシステムは、複雑にすればするほど良いわけではありません。
多くのプロジェクトで、最初に本当に必要なのは次のようなものです。
- 短期メッセージウィンドウ
- 少しの構造化状態
最初からいきなり
- ベクトル長期記憶
- 多層エピソード要約
- 手続き記憶グラフ
まで入れると、システムの複雑さが一気に高くなりすぎることがあります。
そのため、より安全な方針はたいてい次の通りです。
まずは最小構成のメモリから始めて、少しずつ拡張する。
初学者がよくハマるポイント
記憶を「会話ログの保存」と考えてしまう
これは、とても浅い理解です。
保存だけを気にして、読み出しと利用を考えない
保存しても、正しいタイミングで取り出せなければ、記憶は本当に機能していません。
短期と長期を区別しない
その結果、次のような問題が起こります。
- 現在の状態がごちゃごちゃになる
- 長期の好みが短期ノイズに汚染される
メモリシステムで見せると価値が高いもの
メモリシステムをポートフォリオ用プロジェクトとして見せるなら、「たくさんの履歴を保存しました」よりも、次のような点のほうがずっと重要です。
| 見せる内容 | 説明 |
|---|---|
| 記憶の階層化 | どれが短期状態か、どれが長期の好みか、どれがエピソード記録か、どれが手順の経験か |
| 書き込みルール | どんな情報を保存し、どんな情報は今のタスクだけに留めるか |
| 読み出しルール | 回答や実行の前に、どの記憶を関連ありと判断するか |
| エラーケース | どの記憶が誤解を生み、あとでどう修正・削除したか |
| 効果比較 | 記憶あり / 記憶なしで、タスクの一貫性や成功率がどう変わるか |
これによって、あなたが理解しているのが単なる会話ログの保存ではなく、「記憶のエンジニアリング」だと伝わります。
この節の学習サイクル
| レベル | できるようになること |
|---|---|
| 直感 | なぜ Agent は「毎回最初からやり直す」ことに抵抗する必要があるのかを説明できる |
| 構造 | 短期・長期・エピソード・手続き記憶がそれぞれ何を担当するか区別できる |
| 実装 | 書き込み・読み出し・クリーニングの 3 種類の戦略がなぜ重要か説明できる |
| プロジェクト | 記憶の階層化とエラーケースを含む Agent デモを設計できる |
まとめ
この節で最も大事なのは、4 種類の記憶名を暗記することではありません。主軸は次の 1 文です。
メモリシステムの本質は、Agent がステップをまたぎ、回をまたぎ、タスクをまたいでも、毎回ゼロから始めなくてよいようにすることです。
本当に役立つメモリシステムは、たくさん保存することではなく、階層がはっきりしていて、書き込み・読み出しに戦略があり、意思決定をちゃんと支えられるものです。
練習
- 自分のプロジェクトを題材に、短期記憶と長期記憶の例をそれぞれ 1 つ挙げてください。
- もしユーザーが短い時間のうちに何度も要件を変えたら、どの情報を短期記憶に残し、どの情報を長期記憶に入れないべきか考えてみてください。
- たとえば「注文の返金を処理する」ための手順リストのように、簡単な「手続き記憶」フローを設計してみてください。
- 自分の言葉で説明してみてください。なぜメモリシステムの難しさは、保存だけではなく、選択と整理にあるのでしょうか。