9.8.1 Evaluation and Safety ロードマップ:Score、Guard、Trace
Agent は動くだけでは不十分です。成功したか、process は安全だったか、failure がどこで起きたかを知る必要があります。
まず guardrail stack を見る

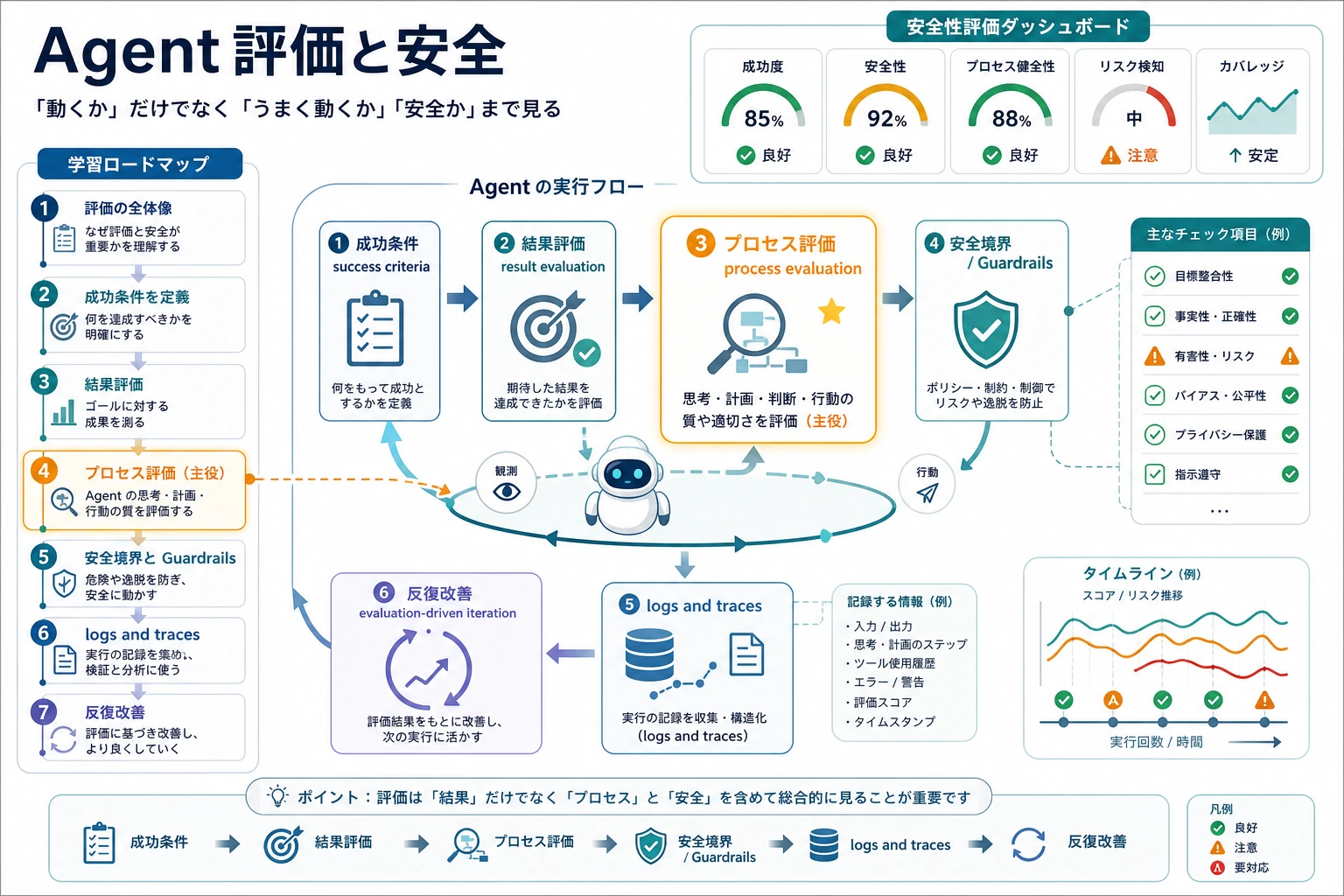
Evaluation は system が有効かを示します。Safety は system が何をしてよいかを決めます。Observability はどこで壊れたかを示します。
Launch scorecard check を動かす
final output と execution process の両方を評価します。
run = {
"task_success": True,
"tool_error": False,
"permission_confirmed": True,
"trace_saved": True,
"cost_usd": 0.08,
}
launch_ok = (
run["task_success"]
and not run["tool_error"]
and run["permission_confirmed"]
and run["trace_saved"]
and run["cost_usd"] < 0.10
)
print("launch_ok:", launch_ok)
print("scorecard:", "task, tools, safety, trace, cost")
出力:
launch_ok: True
scorecard: task, tools, safety, trace, cost
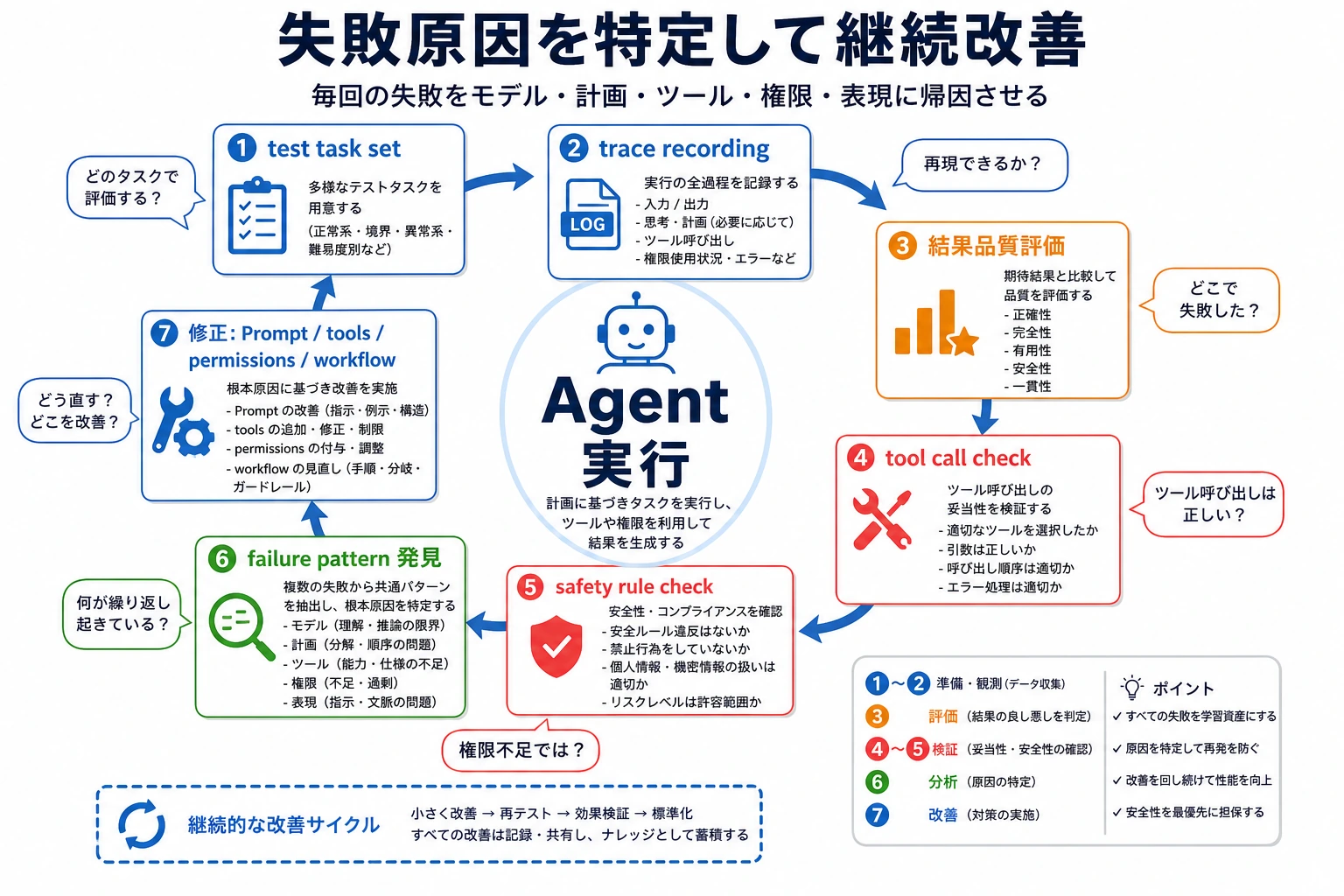
滑らかな final answer だけでは十分な evidence ではありません。replayable tasks と process traces を残します。
この順番で学ぶ
| 手順 | 読む内容 | 実践アウトプット |
|---|---|---|
| 1 | Evaluation methods | result evaluation と process evaluation を分ける |
| 2 | Benchmarks | public benchmarks は reference として使い、product replacement にしない |
| 3 | Safety and alignment | prompt injection、over-permission、leakage、hallucination を識別する |
| 4 | Guardrails | input filter、output validation、permissions、human confirmation を追加する |
| 5 | Observability | logs、traces、errors、latency、cost、failure reason を保存する |
合格ライン
すべての Agent run を、goal、plan、tool calls、observations、final answer、safety rule、cost、failure reason からレビューできれば、この章は合格です。
出口ミニプロジェクトは、10〜20 task の evaluation set と、少なくとも 3 つの safety rules です。