9.4.2 记忆系统概述
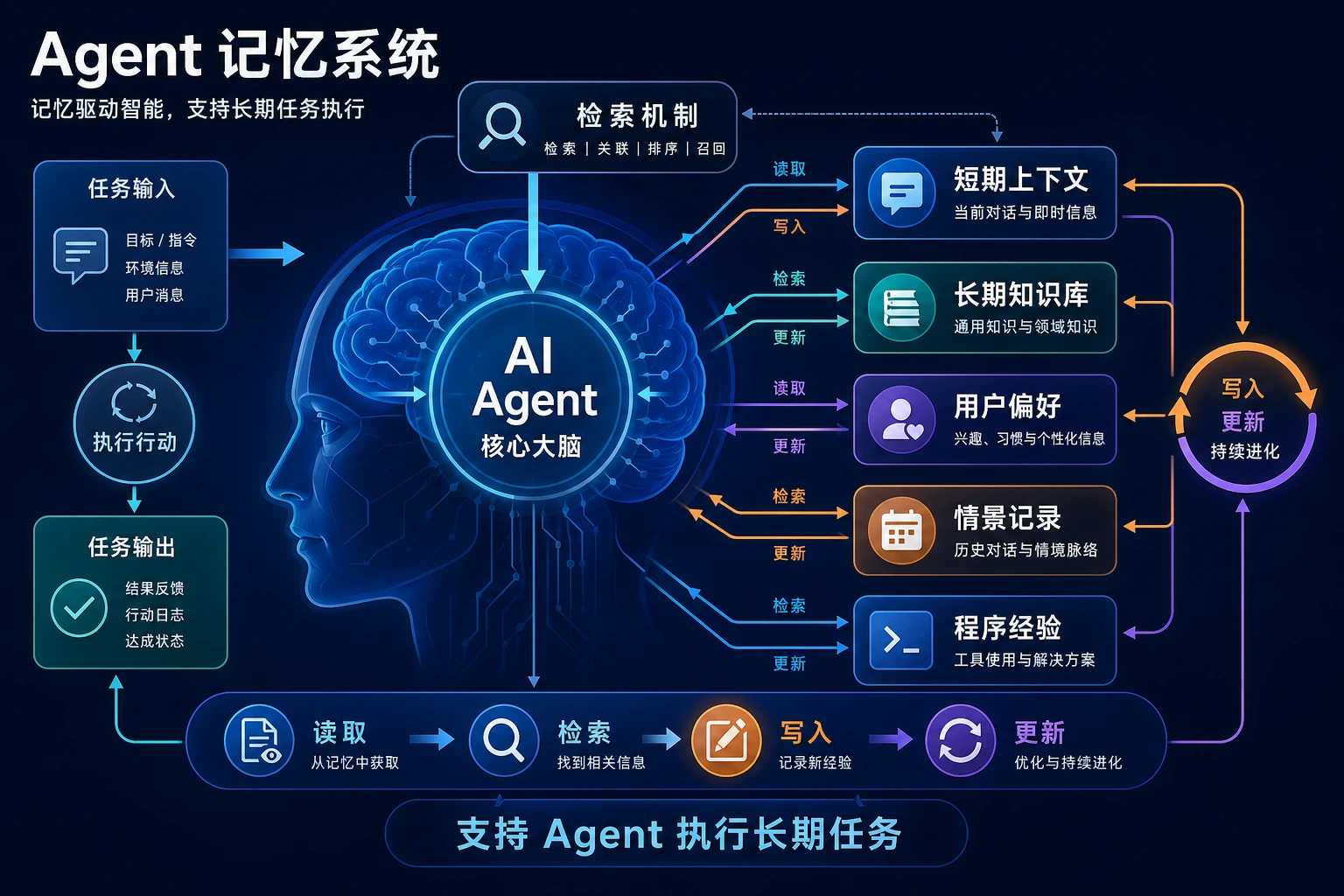
很多 Agent 系统一开始看起来很聪明,但一旦任务一长、回合一多,就会暴露一个本质问题:
它不记得自己刚才在干什么。
所以记忆系统不是“锦上添花”,而是 Agent 从一次性回答器走向持续任务系统的关键一层。
学习目标
- 理解为什么 Agent 需要记忆,而不仅仅是上下文窗口
- 分清短期、长期、情景、程序记忆的区别
- 看懂一个最小的多层记忆结构
- 建立对“记忆不是越多越好”的正确直觉
- 知道后面几节分别在解决哪一层问题
新人先掌握 / 进阶再理解
如果你是新人,这一节先抓住一句话:Agent 记忆不是把所有聊天记录都塞回模型,而是把当前任务、长期偏好、过去经历和可复用流程分层保存、按需取用。
如果你已经做过 Agent 项目,可以进一步关注:哪些信息应该写入长期记忆,什么时候应该读取,如何避免短期噪声污染长期事实,以及记忆是否真的改善了任务完成率。
为什么 Agent 需要记忆?
没有记忆,系统就像每次都重新开机
假设用户和 Agent 的对话是这样的:
- “我想查退款政策”
- “主要看时间范围”
- “如果我已经学了 30%,还能退吗?”
如果系统每次都只看最后一句:
“如果我已经学了 30%,还能退吗?”
它其实缺了大量关键上下文。
所以记忆系统在解决什么?
它在解决:
- 当前任务如何保持连贯
- 过去信息怎样有选择地保留
- 未来决策怎样利用这些保留下来的内容
一句话说:
记忆系统是在帮 Agent 抵抗“每一步都重新开始”的失忆感。
记忆不等于“把所有历史全塞进去”
一个常见误解
很多人一说记忆,第一反应就是:
- 把历史消息全存起来
- 需要时全塞给模型
但这通常会带来:
- token 成本爆炸
- 延迟上升
- 噪声过多
- 真正重要的信息反而被淹掉
记忆系统真正要做的是筛选和组织
所以记忆系统不是简单的“多存点东西”,而是:
在有限预算下,保留最有价值的信息,并用对的方式组织它。
这和人类记忆也很像:
- 不是把一切原封不动记住
- 而是会压缩、选择、归纳
先建立一张完整地图
记忆系统常见分层
| 记忆类型 | 更像什么 | 主要解决什么 |
|---|---|---|
| 短期记忆 | 工作台 | 当前任务上下文 |
| 长期记忆 | 档案库 | 跨回合稳定信息 |
| 情景记忆 | 任务经历 | 过去发生过什么 |
| 程序记忆 | 操作手册 | 某类任务该怎么做 |
一句话先记住
- 短期记忆:这次任务正在发生什么
- 长期记忆:这个用户 / 这个系统长期是什么样
- 情景记忆:过去某次经历的记录
- 程序记忆:一套可复用的做事流程
这四种记忆不是总要全都上,但它们组成了一个非常实用的思考框架。
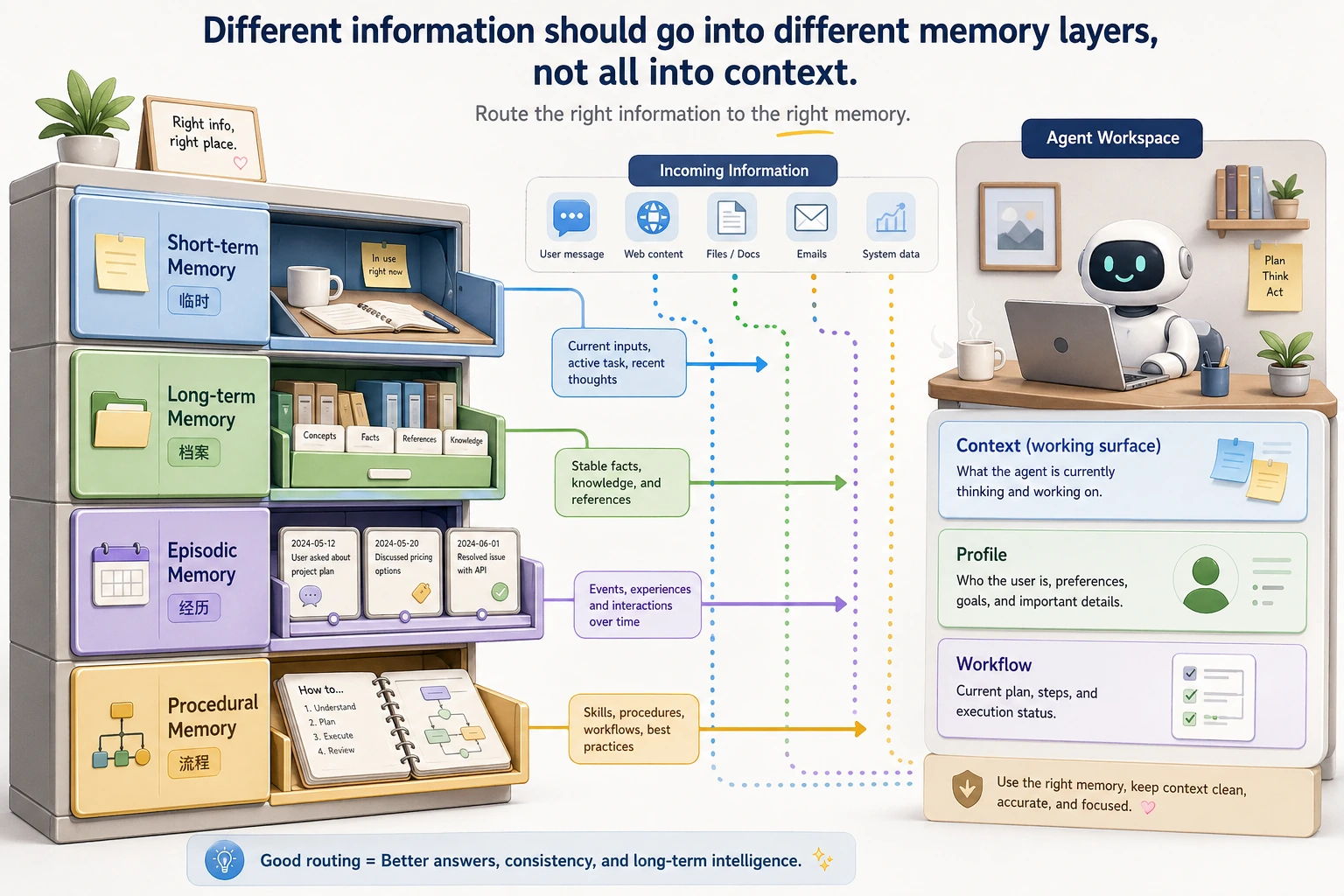
这张图不是要求你一次做满四类记忆,而是帮你判断“这条信息该放哪”。当前任务放 short-term,稳定偏好放 long-term,单次经历放 episodic,可复用流程放 procedural。
短期记忆:当前任务的工作区
它通常存什么?
- 最近几轮对话
- 当前任务目标
- 中间工具结果
- 正在执行到哪一步
为什么它最先重要?
因为用户最容易感知到的失败,往往来自短期记忆出错:
- 系统忘了刚说过什么
- 工具刚查过的结果又查一遍
- 上一步已经决定的事下一步又推翻
这也是为什么下一节我们会先专门讲短期记忆。
长期记忆:跨回合依然有价值的信息
它通常存什么?
例如:
- 用户偏好:喜欢简洁回答
- 用户背景:是 Python 初学者
- 项目背景:当前正在做 RAG 系统
和短期记忆最大的区别
短期记忆服务“这一次任务”。 长期记忆服务“以后遇到类似情况时还能继续用”。
所以长期记忆更像档案,而不是当前工作台。
情景记忆和程序记忆是什么?
情景记忆(episodic memory)
可以理解成:
过去发生过的一次具体经历。
例如:
- “上次用户问退款,最终发现是超过 7 天导致不可退”
它更像一条带时间和事件背景的记录。
程序记忆(procedural memory)
可以理解成:
一套已经被证明有用的做事步骤。
例如:
- “处理退款问题时,先查订单,再查政策,再判断资格”
这更像经验流程,而不是单次事件。
为什么要区分这两类?
因为:
- 情景记忆更像“我经历过什么”
- 程序记忆更像“我学会怎么做”
这两种记忆会直接影响 Agent 的可迁移能力。
一个最小多层记忆示例
下面这个例子虽然简单,但能帮你快速建立“多层记忆结构”直觉。
memory = {
"short_term": {
"messages": ["我想查退款政策", "主要看时间范围"],
"current_goal": "判断退款资格"
},
"long_term": {
"user_preference": "回答要简洁",
"skill_level": "Python 初学者"
},
"episodic": [
"上次处理退款问题时,用户因为学习进度过高而不能退款"
],
"procedural": {
"refund_workflow": ["查订单", "查政策", "判断资格", "返回结论"]
}
}
print(memory)
预期输出:
{'short_term': {'messages': ['我想查退款政策', '主要看时间范围'], 'current_goal': '判断退款资格'}, 'long_term': {'user_preference': '回答要简洁', 'skill_level': 'Python 初学者'}, 'episodic': ['上次处理退款问题时,用户因为学习进度过高而不能退款'], 'procedural': {'refund_workflow': ['查订单', '查政策', '判断资格', '返回结论']}}
这段代码真正教了什么?
它在教你:
记忆不是一个桶,而是多层、分工不同的信息结构。
如果把所有内容混成一堆文本,系统会越来越难用。
记忆系统设计时最常见的权衡
记多少?
- 太少:系统容易失忆
- 太多:系统容易混乱、成本升高
记成原文还是摘要?
- 原文:细节更完整
- 摘要:更省上下文
什么时候写入、什么时候读取?
不是所有内容都值得写入长期记忆。 也不是每次回答都要把所有长期记忆都读出来。
所以记忆系统的关键,不只是“存”,更是:
- 写入策略
- 检索策略
- 清理策略
一个很重要的工程提醒
记忆系统不是越复杂越好。
很多项目一开始最需要的其实只是:
- 短期消息窗口
- 一点结构化状态
如果一开始就上:
- 向量长期记忆
- 多层情景摘要
- 程序记忆图谱
很可能会把系统复杂度拉得过高。
所以更稳妥的原则通常是:
从最小可用记忆开始,再逐步升级。
初学者最常踩的坑
把记忆理解成“聊天记录归档”
这只是很浅的一层。
只关注存储,不关注读取与使用
存了但不会在正确时机取出来,记忆就没有真正工作。
不区分短期和长期
最后会导致:
- 当前状态混乱
- 长期偏好被短期噪声污染
记忆系统最值得展示什么
如果把记忆系统做成作品集项目,最值得展示的不是“我存了很多历史记录”,而是:
| 展示内容 | 说明 |
|---|---|
| 记忆分层 | 哪些是短期状态,哪些是长期偏好,哪些是情景记录或流程经验 |
| 写入规则 | 什么信息值得保存,什么信息只留在当前任务里 |
| 读取规则 | 回答或执行任务前,系统如何选择相关记忆 |
| 错误案例 | 哪些记忆造成了误导,后来如何修正或清理 |
| 效果对比 | 有记忆和无记忆时,任务连贯性或成功率有什么变化 |
这会让别人看到你理解的是“记忆工程”,而不是简单的聊天记录归档。
这一节的学习闭环
| 层次 | 你应该能做到什么 |
|---|---|
| 直觉 | 能解释为什么 Agent 需要抵抗“每一步都重新开始” |
| 结构 | 能分清短期、长期、情景、程序记忆分别负责什么 |
| 工程 | 能说出写入、读取、清理三类策略为什么重要 |
| 项目 | 能设计一个带记忆分层和错误案例的 Agent demo |
小结
这一节最重要的不是背四种记忆名词,而是抓住这条主线:
记忆系统的本质,是让 Agent 在跨步、跨回合、跨任务时,不必每次都从零开始。
真正有用的记忆系统,通常不是“存得最多”,而是“分层清楚、写读有策略、能真正支持决策”。
练习
- 用自己的项目场景,分别举一个短期记忆和长期记忆的例子。
- 想一想:如果用户短期内连续改需求,哪些信息应该留在短期记忆而不是长期记忆?
- 试着设计一个简单的“程序记忆”流程,比如“处理订单退款”的步骤清单。
- 用自己的话解释:为什么说记忆系统的难点不只是存储,而是选择和组织?