9.4.4 长期记忆
短期记忆解决的是:
- 当前这次任务正在发生什么
长期记忆解决的是:
- 这个用户、这个项目、这个系统在更长时间尺度上是什么样
很多 Agent 一开始会把长期记忆想成一句话:
- 把重要信息存起来
但真正落地时,问题会立刻变成:
哪些信息真的值得长期保留,旧信息和新信息冲突时该信谁?
学习目标
- 理解长期记忆和短期记忆的职责边界
- 学会区分用户偏好、稳定背景、临时事实三类信息
- 理解长期记忆写入、更新、冲突处理和读取的基本策略
- 通过可运行示例掌握一个最小长期记忆存取器
先建立一张地图
长期记忆更适合按“写什么 -> 怎么更新 -> 怎么取用”来理解:
所以这节真正想解决的是:
- 长期记忆为什么不是“多存一点”
- 为什么写入和读取策略同样重要
什么信息适合进入长期记忆?
未来大概率还会用到
长期记忆最重要的标准不是“看起来重要”, 而是:
- 未来还有复用价值
例如:
- 用户偏好:喜欢简洁回答
- 用户背景:是初学者
- 项目背景:当前正在做退款助手
这些信息都可能跨很多轮继续发挥作用。
相对稳定,而不是瞬时波动
例如:
- “今天心情不好” 更像短期上下文
- “长期偏好表格总结” 更像长期特征
如果把短期波动也写进长期记忆, 系统很快会学到很多噪声。
一个类比
长期记忆更像“用户档案”和“项目档案”, 不是聊天记录备份箱。
档案强调:
- 稳定
- 可复用
- 有版本感
一个更适合新人的总类比
你可以把长期记忆理解成:
- 在给用户和项目维护档案卡
档案卡里应该写的是:
- 未来还会反复用到的信息
而不是:
- 这次聊天里一时的情绪波动
- 临时说的一句随口要求
这个类比很重要,因为它会帮新人从一开始就避免把长期记忆做成“无限聊天日志”。
长期记忆最常见的三类内容
用户偏好
例如:
- 喜欢简洁
- 喜欢中文
- 输出最好带表格
稳定背景信息
例如:
- 用户角色是运营同学
- 用户正在做 RAG 项目
- 所属团队主要使用 Python
长期任务上下文
例如:
- 本周重点在做退款模块优化
- 当前项目的成功标准是什么
这类信息不像“最近 3 轮消息”那样短命, 也不像情景记忆那样带具体单次事件。
长期记忆最难的不是“存”,而是“更新”
因为新信息可能会推翻旧信息
例如之前记录:
- 用户喜欢详细解释
后来用户连续多次说:
- 以后请尽量简洁
这时系统不能简单同时保留两条, 否则读取时会自相矛盾。
所以长期记忆通常需要:
- 时间戳
- 置信度
- 更新策略
常见策略包括:
- 新记录覆盖旧记录
- 新旧并存,但高置信度优先
- 保留版本历史,只在读取时选最新
为什么“置信度”很重要?
因为用户随口一句话,不一定就该被永远写死。 例如:
- “这次先不用表格”
未必等于:
- “以后永远别用表格”
所以长期记忆最好有:
- 观察次数
- 明确度
- 置信度
一个很适合初学者先记的写入判断表
| 信息类型 | 更适合短期还是长期 |
|---|---|
| 这次先简洁一点 | 更偏短期 |
| 用户长期喜欢中文 | 更偏长期 |
| 当前项目是退款助手 | 更偏长期任务背景 |
| 今天心情不好 | 更偏短期 |
这个表很适合新人,因为它会帮助你先回答一个最容易混乱的问题:
- 到底什么值得进长期记忆
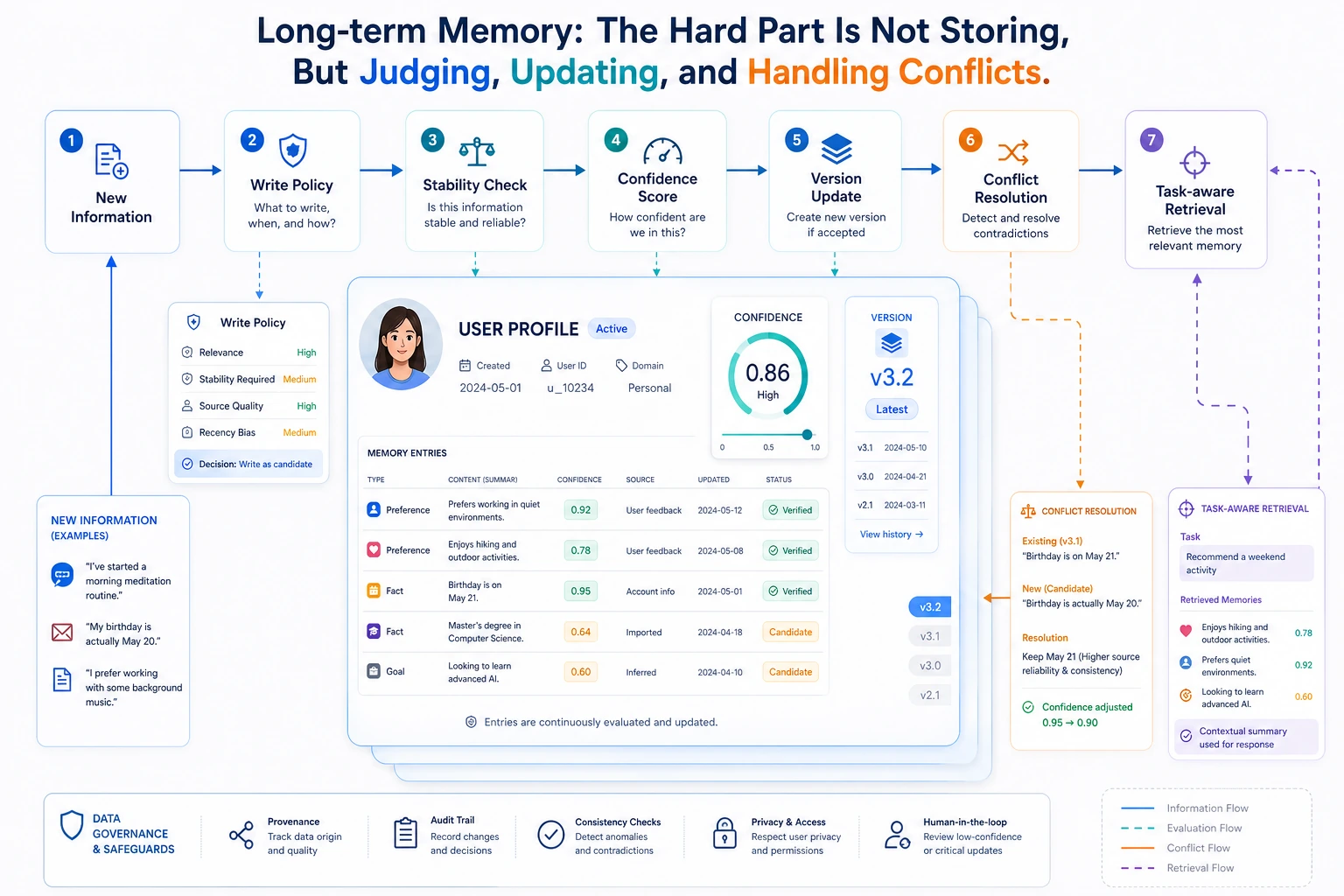
长期记忆不是“永久聊天记录”。看图时重点关注 write policy、confidence、version 和 retrieval:系统要先判断值不值得写,再处理新旧冲突,最后按当前任务取回相关事实。
先跑一个最小长期记忆存取器
这个示例会做四件事:
- 写入长期记忆
- 更新已有记忆
- 用置信度和时间排序读取
- 按用户隔离记忆
from dataclasses import dataclass
@dataclass
class LongTermFact:
user_id: str
key: str
value: str
confidence: float
updated_at: int
class LongTermMemoryStore:
def __init__(self):
self.items = []
self.clock = 0
def _tick(self):
self.clock += 1
return self.clock
def upsert(self, user_id, key, value, confidence=0.6):
now = self._tick()
for item in self.items:
if item.user_id == user_id and item.key == key:
# 新值更高置信时,覆盖旧值
if confidence >= item.confidence:
item.value = value
item.confidence = confidence
item.updated_at = now
return item
fact = LongTermFact(
user_id=user_id,
key=key,
value=value,
confidence=confidence,
updated_at=now,
)
self.items.append(fact)
return fact
def get_profile(self, user_id):
records = [item for item in self.items if item.user_id == user_id]
records.sort(key=lambda x: (x.confidence, x.updated_at), reverse=True)
return {item.key: item.value for item in records}
store = LongTermMemoryStore()
store.upsert("u_001", "response_style", "detailed", confidence=0.4)
store.upsert("u_001", "response_style", "concise", confidence=0.9)
store.upsert("u_001", "language", "zh", confidence=0.8)
store.upsert("u_002", "response_style", "table", confidence=0.7)
print("u_001 profile:", store.get_profile("u_001"))
print("u_002 profile:", store.get_profile("u_002"))
预期输出:
u_001 profile: {'response_style': 'concise', 'language': 'zh'}
u_002 profile: {'response_style': 'table'}
这个例子最值得注意什么?
不是“能不能存进去”, 而是:
- 同一个 key 会被更新
- 置信度更高的信息会覆盖旧值
- 读取时是按用户聚合的 profile
这已经比“往列表 append 一条字符串”更接近真实长期记忆。
为什么这里用 key-value 很合理?
因为长期记忆里很多信息天然就是 profile 型:
response_stylelanguageproject_name
这类信息用键值结构会比纯文本段落更容易控。
什么时候不适合用这种形式?
如果信息本身更像一段故事或一次经历, 那更适合:
- 情景记忆
而不是简单 key-value。
再看一个最小“写入决策”示例
facts = [
{"text": "以后尽量用中文", "stability": "high", "target": "long_term"},
{"text": "这次回答先短一点", "stability": "low", "target": "short_term"},
]
for fact in facts:
print(fact)
预期输出:
{'text': '以后尽量用中文', 'stability': 'high', 'target': 'long_term'}
{'text': '这次回答先短一点', 'stability': 'low', 'target': 'short_term'}
这个示例虽然很小,但它很适合帮助初学者先建立一个关键习惯:
- 写入记忆前,先问这条信息到底是长期还是短期
长期记忆怎么读取才不会“又多又乱”?
读取时不要把所有东西都塞进上下文
就算长期记忆存了很多条, 回答当前问题时也不一定都相关。
更好的方式是:
- 先按用户过滤
- 再按键或主题过滤
- 最后只抽当前最相关的几条
一个极简按主题过滤示例
def select_relevant_profile(profile, query):
selected = {}
if "回答" in query or "风格" in query:
if "response_style" in profile:
selected["response_style"] = profile["response_style"]
if "中文" in query or "语言" in query:
if "language" in profile:
selected["language"] = profile["language"]
return selected
profile = store.get_profile("u_001")
print(select_relevant_profile(profile, "之后回答风格保持一致"))
预期输出:
{'response_style': 'concise'}
这说明长期记忆真正有效, 还取决于读取策略。
第一次做长期记忆系统时,最稳的默认顺序
更稳的顺序通常是:
- 先只存最稳定的用户偏好
- 先做简单 key-value profile
- 先把冲突更新规则写清楚
- 再补更复杂的读取和检索策略
这样会比一开始就做“大而全记忆系统”更容易做稳。
如果你的目标是“知识库驱动的课件生成助手”,哪些信息值得长期记?
这类项目最容易犯的错是:
- 把每次课件主题都写进长期记忆
但实际上,很多主题只是一次任务, 并不适合长期保留。
更适合进长期记忆的,往往是这些稳定偏好:
| 信息 | 更偏长期还是短期 |
|---|---|
| 用户长期偏好输出成 Word | 长期 |
| 用户长期喜欢课堂讲解风格 | 长期 |
| 用户本次要做“折扣应用题”课件 | 短期 |
| 这次只需要 3 道练习题 | 更偏短期 |
| 用户长期面向“小学高年级”备课 | 长期或半长期 |
你可以先把它压成一句话:
长期记忆记偏好和稳定背景,短期状态记这次任务细节。
一个更像真实项目的长期 profile 示例
profile = {
"preferred_doc_format": "word",
"preferred_style": "课堂讲解",
"preferred_language": "zh",
"default_audience": "小学高年级",
"prefer_source_refs": True,
}
print(profile)
预期输出:
{'preferred_doc_format': 'word', 'preferred_style': '课堂讲解', 'preferred_language': 'zh', 'default_audience': '小学高年级', 'prefer_source_refs': True}
这个例子最值得新人注意的是:
- 长期记忆不是帮你记住“这次要写什么”
- 而是帮系统记住“你通常喜欢它怎么写”
长期记忆最容易踩的坑
误区一:用户说过一次就永久写入
这会导致很多偶然偏好被永久固化。
误区二:长期记忆和短期记忆不分层
结果就是:
- 当前对话信息和长期档案搅在一起
系统会越来越乱。
误区三:只管写入,不管更新和冲突
冲突不处理,长期记忆迟早自相矛盾。
如果把它做成项目或系统设计,最值得展示什么
最值得展示的通常不是:
- “我存了很多历史”
而是:
- 哪些信息会进长期记忆
- 冲突信息怎么更新
- 当前任务只会取回哪些相关档案
- 为什么这套策略不会把系统越存越乱
这样别人会更容易看出:
- 你理解的是长期档案系统
- 不只是做了一个消息仓库
小结
这节最重要的不是把长期记忆理解成“存更多信息”, 而是理解它的本质:
长期记忆是在为 Agent 建一个会随时间更新的稳定档案,而不是囤积历史消息。
只要你抓住“稳定、可复用、可更新”这三个关键词, 后面再设计长期档案系统时就不会走偏。
练习
- 给示例加一个
source字段,区分“用户显式声明”和“系统推断”,然后让写入策略对两者区别对待。 - 想一想:
这次先简洁一点为什么不一定适合直接写成长期偏好? - 如果用户偏好经常变化,你会用覆盖、版本保留,还是置信度衰减?为什么?
- 你会如何把长期记忆和短期记忆组合起来服务当前回答?