9.4.6 メモリ工学の実装
前の「メモリシステムの概念」の話では、いちばん誤解しやすいのが次の点です。
- メモリとは、情報を保存すること
でも、実際に工程として作ると、難しいのは「保存できるか」ではなく、むしろ次の点です。
何を書くか、いつ書くか、どう検索するか、いつ消すか。
この4つで、メモリシステムが「役立つもの」になるか、「高いだけで散らかるもの」になるかが決まります。
学習目標
- メモリ工学の中心になる意思決定、つまり書き込み・検索・期限切れ・圧縮を理解する
- 最小限で動くメモリの読み書き経路を設計できるようになる
- 「メモリが多いほど良い」わけではない理由を理解する
- 動作する例を通して、メモリのスコア付けと整理の基本実装を学ぶ
メモリ工学は本当に何を解決するのか?
メモリシステムは「箱」ではなく、方針付きの流れ
会話やツールの結果を全部ロングタームメモリに入れてしまうと、短期的にはすごく完全そうに見えますが、長期的には次のような問題がよく起こります。
- ノイズがどんどん増える
- 検索の命中率が下がる
- token コストが上がる
- 本当に大事な事実が埋もれる
だから、メモリ工学の中心は「全部保存すること」ではなく、「方針を持って保存すること」です。
メモリの流れは、まず4つに分けられる
write:書き込むかどうかindex:書き込んだ後、どう整理するかretrieve:検索時にどう並べるかlifecycle:期限切れ、整理、圧縮
この4つがはっきりしていれば、システムはかなり安定しやすくなります。
たとえで考える
メモリシステムは、物置よりも図書館に近いです。
- 物置は「入れる」ことだけを見る
- 図書館は「目録化、検索、入れ替え、保管」を見る
Agent が長く動き続けるには、後者に近づける必要があります。
書き込み方針:どんな情報がロングタームメモリに入る価値があるのか?
すべてのメッセージを保存する必要はない
例えば、次の2つは価値がかなり違います。
- 「こんにちは、いますか?」
- 「ユーザーは簡潔な回答を好み、3点以内にしてほしい」
2つ目は長期保存に向いていますが、1つ目は普通は保存する価値がありません。
実用的な書き込み判断
まずは次の3つの質問でふるいにかけられます。
- この情報は将来また使うか?
- この情報はユーザー、タスク、または方針と関係があるか?
- この情報は十分安定していて、一時的なノイズではないか?
よく書き込む情報の種類
- ユーザーの好み
- 安定した背景情報
- 重要なタスクの結論
- 検証済みで再利用できる手順の要約
逆に、そのままロングタームメモリに入れないほうがよいものは次の通りです。
- 一時的な中間ログ
- くり返しのあいさつ
- 検証できない推測的な内容
検索方針:どうやって「役に立つメモリ」を取り出すのか?
検索は単なる意味の近さではない
純粋な類似度だけだと、工程上とても重要な情報を見落とすことがあります。たとえば次のような点です。
- そのメモリは古すぎないか
- そのメモリ自体の重要度は高いか
- 現在のユーザーに関係しているか
よくあるスコアの組み合わせ
検索スコアは、複数の要素を重み付けして作れます。
- 意味的またはキーワードの関連度
- 重要度スコア
- 新しさの減衰
- 出典の信頼度
これは、「似ているか」だけを見るより、ずっと安定します。
なぜ減衰を考えるのか
情報の中には、時間がたつと古くなるものがあります。
時間減衰がないと、システムはとても古い好みや文脈を、いつまでも現在の判断に使ってしまうかもしれません。
ライフサイクル:期限切れ、整理、圧縮
TTL はオプションではない
次のようなメモリは、もともと寿命が短いです。
- 現在の会話セッションだけの一時的なパラメータ
- 1回きりの状態フラグ
こういう情報には、TTL を付けるのがよいです。
整理は「定期的にまとめて消す」だけではない
よりよい方法は、たいてい次の組み合わせです。
- 期限切れチェック
- 価値の低いものの削除
- 重複内容の統合
圧縮があると長期運用しやすくなる
記録が増えてきたら、同じ種類の履歴を要約にまとめることができます。たとえば次のようなイメージです。
- 直近20件の「ユーザーの好み確認」を1件の安定した好み記録にまとめる
これにより、検索ノイズとコンテキストの圧迫をかなり減らせます。
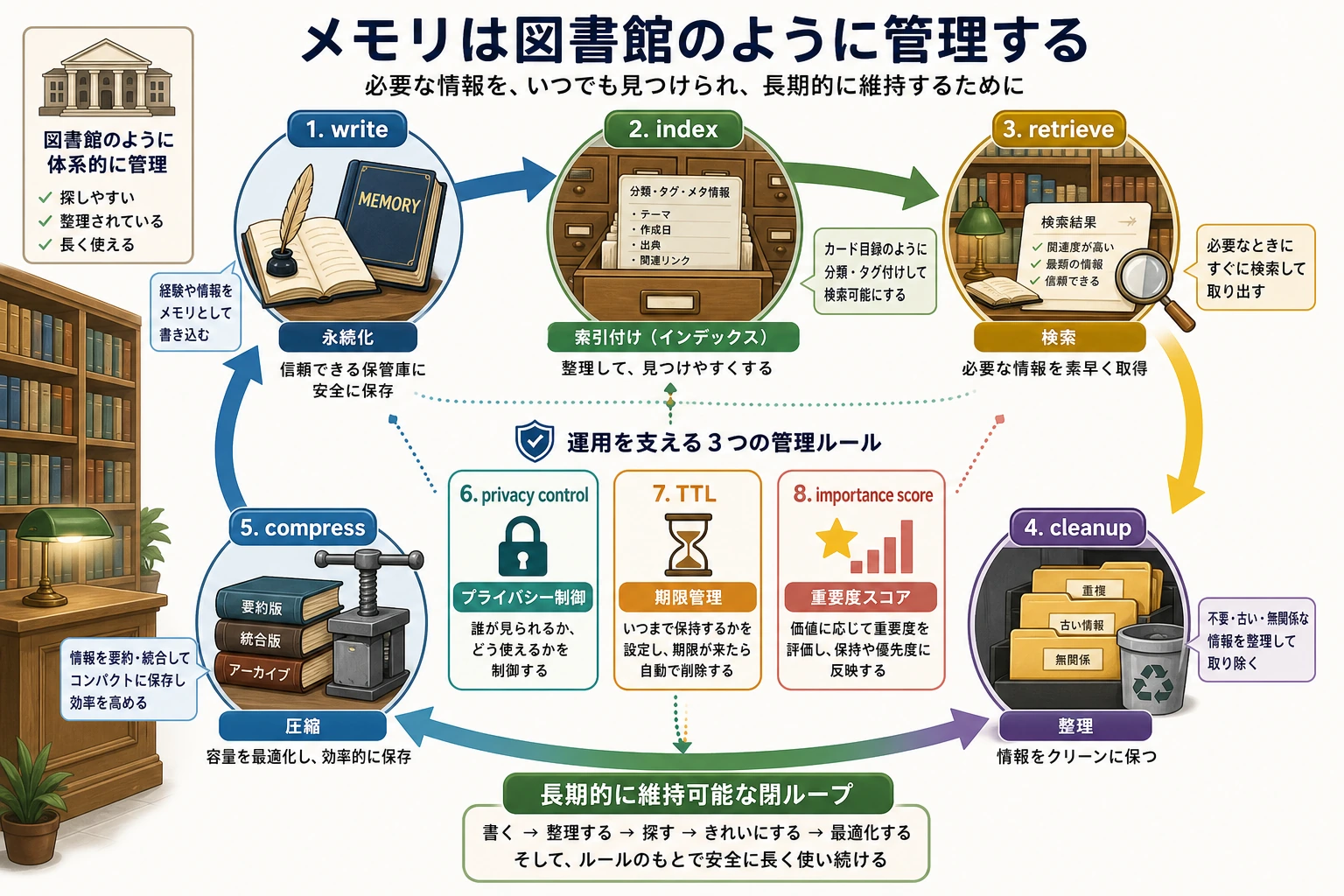
この図はライフサイクルの順で読むとわかりやすいです。write は書き込むかどうか、index はどう整理するか、retrieve はどう取り出すか、cleanup / compress はいつ整理・圧縮するかを決めます。メモリ工学の難しさは、保存そのものより方針にあります。
まずは実行できる最小メモリエンジンを動かしてみよう
次の例では、以下をまとめて示します。
- 短期メッセージウィンドウ
- ロングタームメモリへの書き込み(importance と TTL 付き)
- クエリ検索(関連度 + 重要度 + 新しさ)
- 期限切れの整理
from dataclasses import dataclass
from collections import deque
import math
@dataclass
class MemoryItem:
memory_id: int
text: str
tags: list
source: str
importance: float
created_step: int
ttl_steps: int | None
class MemoryEngine:
def __init__(self, short_window=4):
self.short_messages = deque(maxlen=short_window)
self.long_memories = []
self.step = 0
self._next_id = 1
def tick(self):
self.step += 1
def add_short_message(self, role, content):
self.short_messages.append({"role": role, "content": content, "step": self.step})
def write_long_memory(self, text, tags=None, source="dialogue", importance=0.5, ttl_steps=None):
tags = tags or []
normalized = text.strip().lower()
# 極小の重複排除: 完全に同じテキストは再度書き込まない
for item in self.long_memories:
if item.text.strip().lower() == normalized and self._is_alive(item):
return item.memory_id
memory = MemoryItem(
memory_id=self._next_id,
text=text,
tags=tags,
source=source,
importance=float(importance),
created_step=self.step,
ttl_steps=ttl_steps,
)
self._next_id += 1
self.long_memories.append(memory)
return memory.memory_id
def _is_alive(self, item):
if item.ttl_steps is None:
return True
return (self.step - item.created_step) <= item.ttl_steps
def cleanup(self):
self.long_memories = [item for item in self.long_memories if self._is_alive(item)]
def _tokenize(self, text):
lowered = text.lower()
compacted = lowered.replace(" ", "")
tokens = set(lowered.split())
tokens.update(compacted[i : i + 2] for i in range(max(len(compacted) - 1, 0)))
return tokens
def retrieve(self, query, top_k=3):
query_tokens = self._tokenize(query)
scored = []
for item in self.long_memories:
if not self._is_alive(item):
continue
item_tokens = self._tokenize(item.text) | set(tag.lower() for tag in item.tags)
overlap = len(query_tokens & item_tokens)
age = self.step - item.created_step
recency = math.exp(-age / 20) # 新しいほどスコアが高い
score = (0.55 * overlap) + (0.30 * item.importance) + (0.15 * recency)
scored.append((item, round(score, 4)))
scored.sort(key=lambda x: x[1], reverse=True)
return scored[:top_k]
engine = MemoryEngine(short_window=3)
engine.add_short_message("user", "返金条件について知りたいです")
engine.write_long_memory(
"ユーザーの好み: 回答は簡潔に、最大3点まで",
tags=["preference", "style", "簡潔", "スタイル"],
importance=0.95,
)
engine.tick()
engine.add_short_message("assistant", "はい、簡潔に説明します")
engine.write_long_memory(
"一時的なデバッグ用マーカー: 今回は実験プロンプト v2 を使用",
tags=["debug"],
importance=0.2,
ttl_steps=1,
)
engine.tick()
engine.write_long_memory(
"返金ポリシーの重要ポイント: 7日以内かつ学習進度が20%未満",
tags=["refund", "policy", "返金", "ポリシー"],
importance=0.9,
)
print("cleanup 前:", [m.text for m in engine.long_memories])
engine.tick()
engine.cleanup()
print("cleanup 後 :", [m.text for m in engine.long_memories])
results = engine.retrieve("簡潔なスタイルで返金ポリシーを答えてください", top_k=2)
print("\nretrieval:")
for item, score in results:
print(item.memory_id, round(score, 4), item.text)
想定出力:
cleanup 前: ['ユーザーの好み: 回答は簡潔に、最大3点まで', '一時的なデバッグ用マーカー: 今回は実験プロンプト v2 を使用', '返金ポリシーの重要ポイント: 7日以内かつ学習進度が20%未満']
cleanup 後 : ['ユーザーの好み: 回答は簡潔に、最大3点まで', '返金ポリシーの重要ポイント: 7日以内かつ学習進度が20%未満']
retrieval:
3 3.1627 返金ポリシーの重要ポイント: 7日以内かつ学習進度が20%未満
1 0.9641 ユーザーの好み: 回答は簡潔に、最大3点まで

このコードで特に学ぶべき3点
- 書き込みは無条件ではない
importance、tags、重複排除で書き込み品質を制御している - 検索は純粋な類似度だけではない
関連度、重要度、新しさを合わせて並べ替えている - ライフサイクルは必須
ttl_stepsとcleanupで長期的な肥大化を防いでいる
なぜ「デバッグ用マーカー」が消えるのは妥当なのか?
それは一時情報で、ttl_steps=1 が設定されているからです。
その後も残しておくと、検索結果を汚すだけになることが多いです。
なぜ「ユーザーの好み」と「返金ポリシー」が優先的に呼び出されるのか?
クエリの語が同時に次を引き起こしているからです。
簡潔は好みメモリに対応する返金ポリシーはポリシーメモリに対応する
しかも、どちらも importance が高く、期限切れでもありません。
工程実務では、さらにどんな層が必要か?
プライバシーと機密情報の扱い
ロングタームメモリに書き込む前に、通常は次を行います。
- PII のマスキング
- コンプライアンス上のフィールド除外
保存先とインデックス
例ではメモリ上の構造を使いました。
実際のシステムでは、よく次のようなものを接続します。
- KV / ドキュメントDB
- ベクトルDB
- リレーショナルDB
監視指標
最低でも、次の指標は見たほうがよいです。
- メモリ命中率
- 期限切れ整理率
- 平均召回件数
- 誤召回率
指標がないと、メモリシステムはどんどんブラックボックスになりやすいです。
よくある誤解
誤解1:メモリは多いほど賢い
メモリが多いほど、うるさくなることもあります。
大事なのは総量ではなく、有効なメモリの割合です。
誤解2:書き込みだけして、整理しない
これを続けると、長期的に検索ノイズがたまり、後から効果が下がります。
誤解3:意味検索だけで十分
メモリ工学は必ず「検索 + 方針」の組み合わせです。
単なるベクトル検索だけでは、すべての問題は解決できません。
まとめ
この節でいちばん大事なのは、また別の「メモリの種類名」を覚えることではなく、工程としての判断を持つことです。
メモリシステムが使えるかどうかは、保存コンポーネントを接続したかではなく、書き込み・検索・ライフサイクルの3つの方針がきちんと閉じているかで決まる。
この閉ループが動き始めて、
はじめてメモリシステムは概念から安定した能力になります。
演習
- 例に「出典の信頼度」フィールドを追加し、検索スコアに含めてみましょう。
ttl_stepsをもっと短く、または長くして、召回結果がどう変わるか観察しましょう。- 「永遠に期限切れにならないが、重要度が低い」メモリを1つ設計して、結果を汚すかどうか確認しましょう。
- 「ユーザーの好み」と「一時的なデバッグ情報」に、どのように別々の書き込み方針を設定しますか?