5.1.3 Scikit-learn ハンズオン:fit、transform、Pipeline
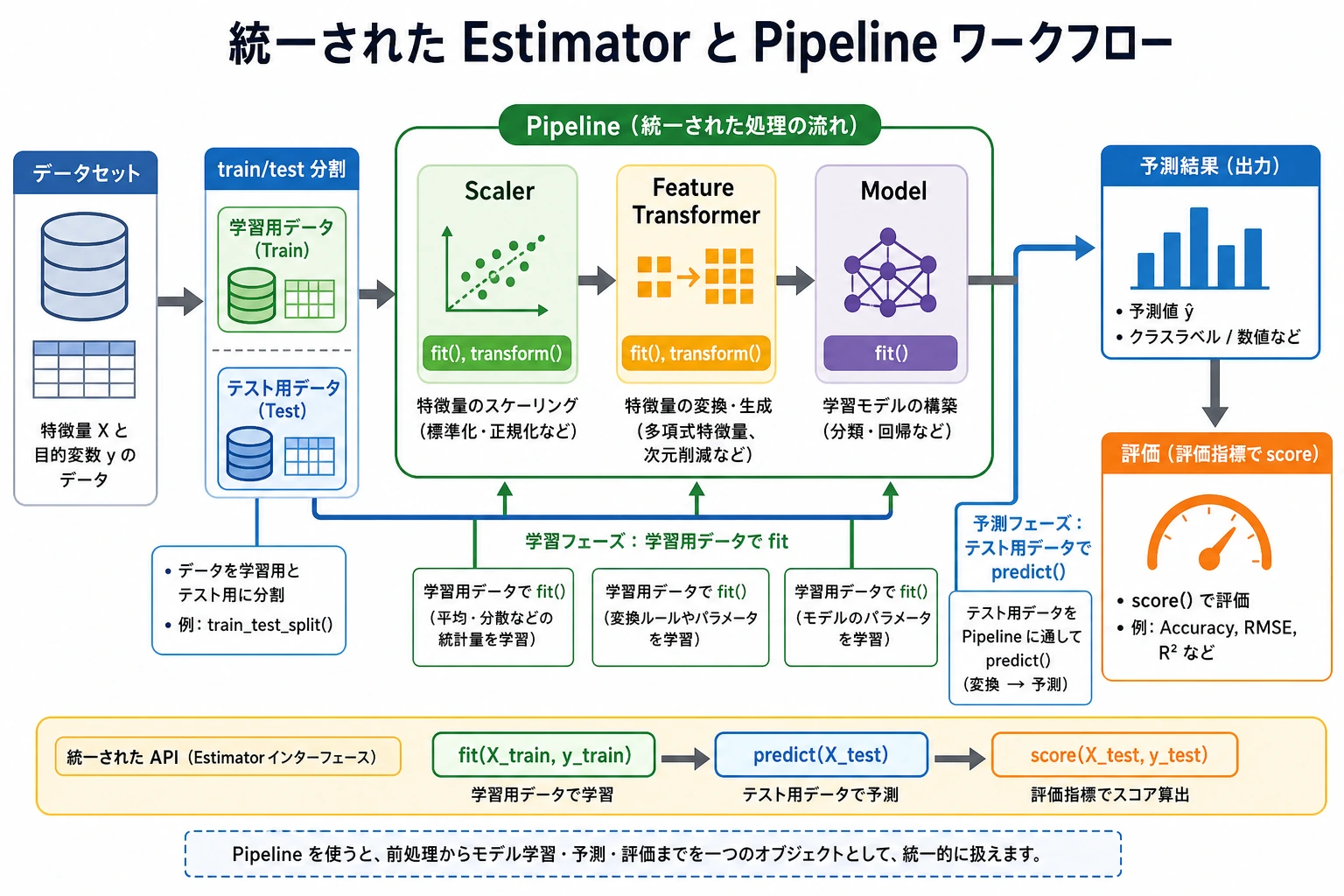
Scikit-learn は古典的な機械学習でよく使われる Python ライブラリです。このページは短くします。先に流れを見て、次に完全なスクリプトを動かします。
まずワークフローを見る
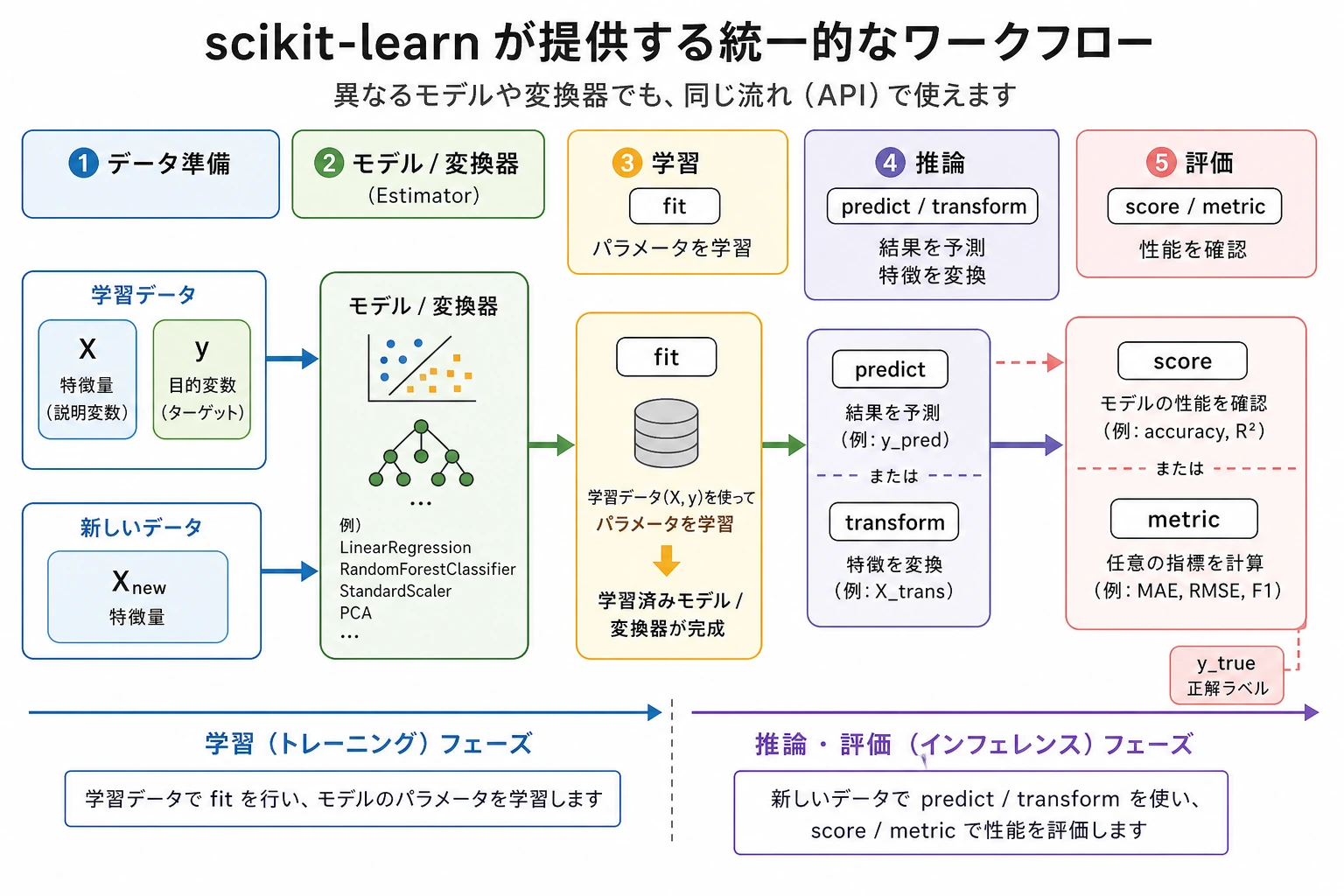
sklearn の多くの作業はこのループです。
データ読み込み -> train/test 分割 -> train で fit -> test で predict -> score -> 証拠を保存
まず 4 つの動詞を覚えます。
| 動詞 | 意味 | よく使う対象 |
|---|---|---|
fit | 学習データからパラメータを学ぶ | estimator または transformer |
transform | 学んだ前処理を適用する | transformer |
predict | ラベルや数値を出す | estimator |
score | 簡単な指標を返す | estimator または pipeline |
三つの役割
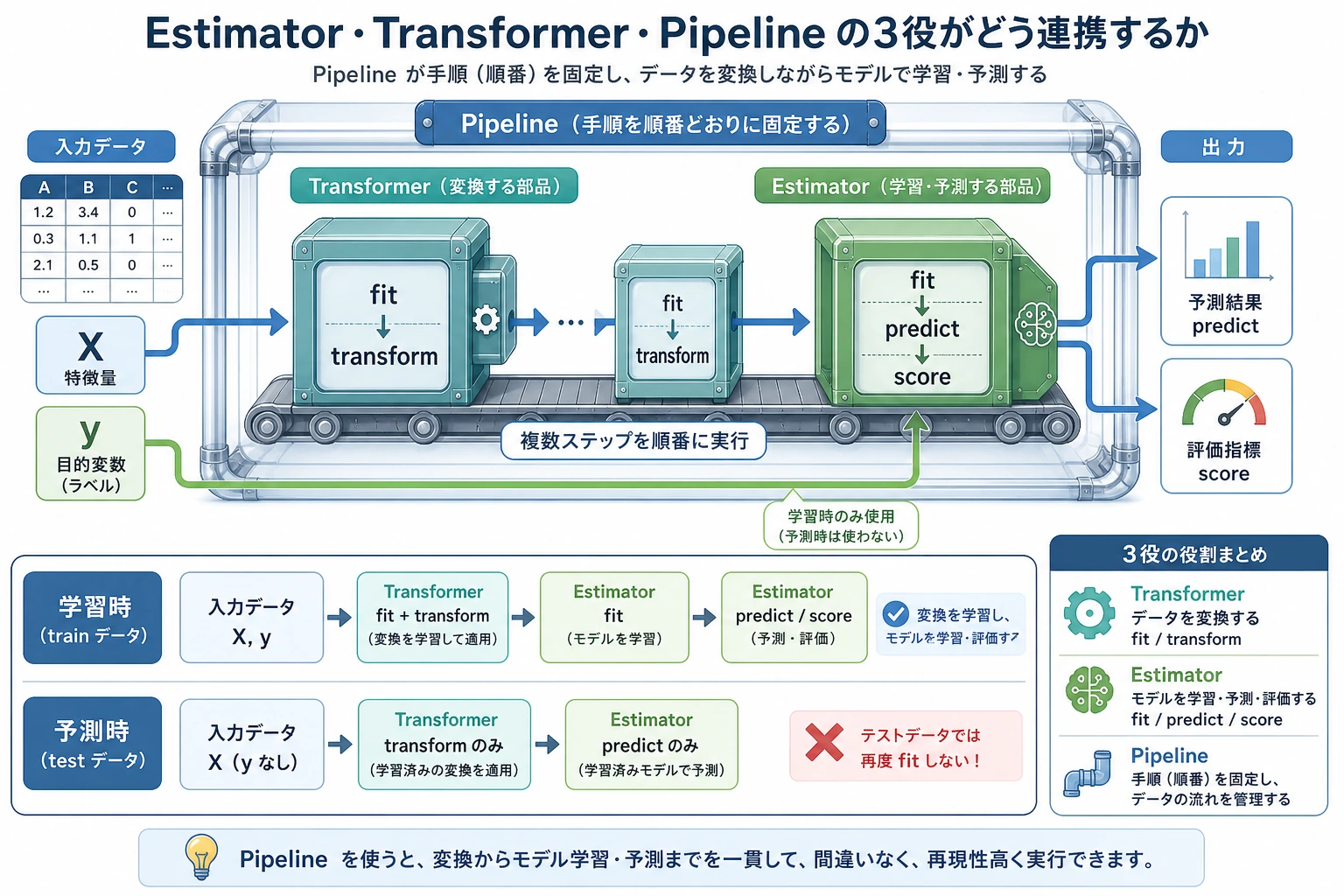
| 役割 | 仕事 | 例 |
|---|---|---|
| Estimator | 学習して予測する | LogisticRegression、DecisionTreeClassifier |
| Transformer | データの形、尺度、表現を変える | StandardScaler、OneHotEncoder、PCA |
| Pipeline | 前処理とモデルを再利用できる流れにする | scaler -> classifier |
初心者ルール:前処理の fit は学習データだけで行う。Pipeline はこの順序を守りやすくしてくれます。
インストールと確認
python -m pip install --upgrade scikit-learn joblib
python - <<'PY'
import sklearn
print(sklearn.__version__)
PY
期待される出力は、たとえば次のようなバージョン番号です。
1.8.0
scikit-learn はインストール名、sklearn は Python で import する名前です。
完全な流れを動かす
ch05_sklearn_workflow.py を作成します。
from pathlib import Path
from joblib import dump, load
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data,
iris.target,
test_size=0.25,
random_state=42,
stratify=iris.target,
)
models = {
"logistic": Pipeline([
("scale", StandardScaler()),
("model", LogisticRegression(max_iter=1000, random_state=42)),
]),
"tree": Pipeline([
("model", DecisionTreeClassifier(max_depth=3, random_state=42)),
]),
"knn": Pipeline([
("scale", StandardScaler()),
("model", KNeighborsClassifier(n_neighbors=5)),
]),
}
scores = {}
for name, pipe in models.items():
pipe.fit(X_train, y_train)
pred = pipe.predict(X_test)
scores[name] = accuracy_score(y_test, pred)
print(f"{name:<8} accuracy={scores[name]:.3f}")
best_name = max(scores, key=scores.get)
best_model = models[best_name]
print(f"best={best_name}")
print("first_prediction=", iris.target_names[best_model.predict(X_test[:1])][0])
print("report_for_best:")
print(classification_report(
y_test,
best_model.predict(X_test),
target_names=iris.target_names,
zero_division=0,
))
output_path = Path("iris_pipeline.joblib")
dump(best_model, output_path)
reloaded = load(output_path)
print("reloaded_prediction=", iris.target_names[reloaded.predict(X_test[:1])][0])
実行します。
python ch05_sklearn_workflow.py
期待される出力:
logistic accuracy=0.921
tree accuracy=0.895
knn accuracy=0.921
best=logistic
first_prediction= setosa
report_for_best:
precision recall f1-score support
setosa 1.00 1.00 1.00 12
versicolor 0.86 0.92 0.89 13
virginica 0.92 0.85 0.88 13
accuracy 0.92 38
macro avg 0.92 0.92 0.92 38
weighted avg 0.92 0.92 0.92 38
reloaded_prediction= setosa
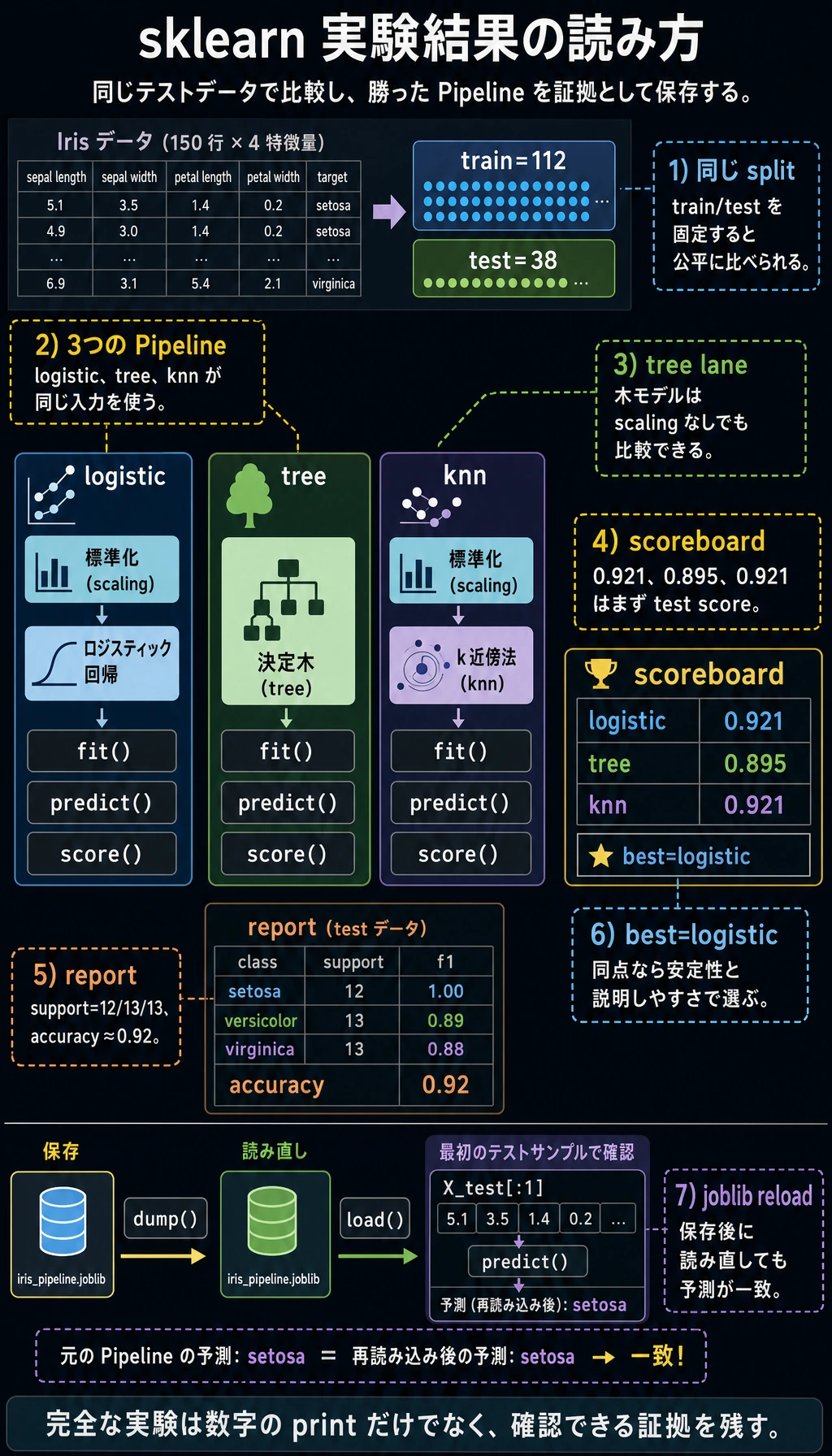
sklearn のバージョンによって、同点のときに選ばれる best model が変わることがあります。それでも問題ありません。重要な証拠は、各モデルが fit、predict、score でき、保存した Pipeline が再読み込み後も予測できることです。
Pipeline がよくある失敗を防ぐ理由
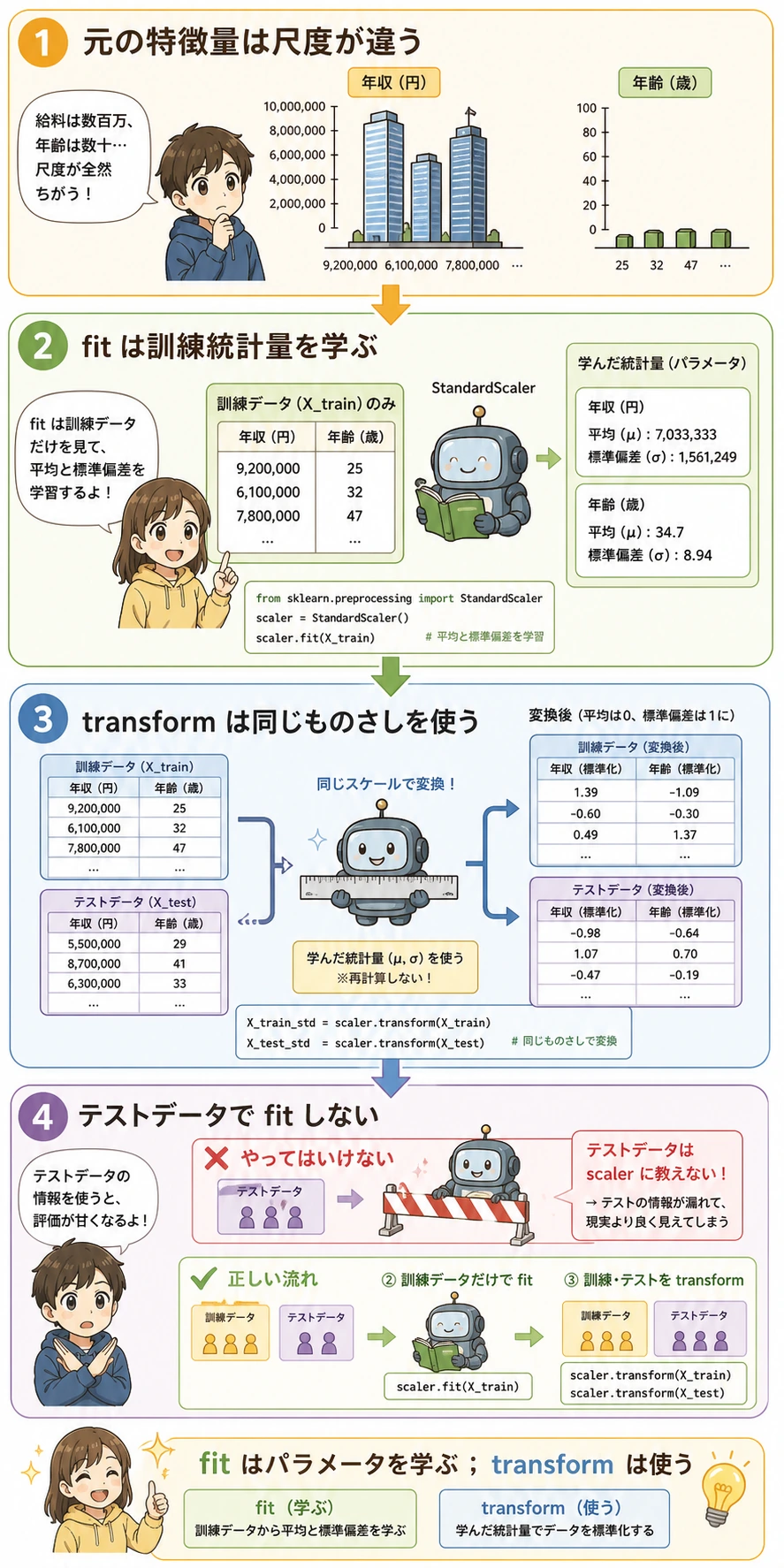
間違った流れ:
全データで scaler を fit -> 分割 -> 評価
なぜ間違いか:テストデータが前処理に影響してしまい、スコアが甘くなります。
正しい流れ:
先に分割 -> 学習データだけで scaler を fit -> test を transform -> 評価
Pipeline([("scale", StandardScaler()), ("model", ...)]) を使うと、学習時も予測時も同じ安全な流れになります。
よくある失敗
| 症状 | 最初に確認 | よくある修正 |
|---|---|---|
ModuleNotFoundError: sklearn | 有効な Python 環境 | python -m pip install scikit-learn で入れる |
| 毎回スコアが変わる | random_state がない | 分割と対応モデルに random_state=42 を入れる |
| テストスコアは良いが実運用で悪い | データリーク | Pipeline を使い、分割してから前処理を fit する |
| モデルを保存/読込できない | joblib 不足またはパス違い | joblib を入れ、Path.cwd() を表示する |
| モデル比較が不公平 | 前処理の流れが違う | 各モデルを比較可能な Pipeline に入れる |
練習
test_sizeを0.25から0.2に変えて、スコア差を記録する。KNeighborsClassifier(n_neighbors=5)をn_neighbors=3に変える。- 同じ Pipeline パターンで
SVCなどのモデルを一つ追加する。 - 端末出力と
iris_pipeline.joblibを証拠として保存する。
通過チェック
次を説明できれば、次のレッスンへ進めます。
fit、transform、predict、scoreがそれぞれ何をするか。- 前処理が学習データだけから学ぶべき理由。
Pipelineが手作業の前処理より安全な理由。- 同じ train/test split で二つのモデルを比較する方法。
- 最終モデルを保存し、再読み込みする方法。