1.3.3 Jupyter Notebook
この節の位置づけ
この節では、データ分析と AI 実験で最もよく使う対話型環境を紹介します。Notebook は探索・実験・発表に向いており、.py ファイルは正式なプロジェクトコードに向いていることを理解し、Cell の作成、コードの実行、Markdown の記述、図の作成を学びます。
学習目標
- Jupyter Notebook とは何か、何に向いているかを理解する
- Jupyter Notebook をインストールして起動する
- Cell の種類と基本操作を身につける
- よく使うショートカットキーに慣れる
- マジックコマンドの使い方を学ぶ
- Notebook と
.pyファイルの違いを理解する
Jupyter Notebook とは?
Jupyter Notebook は対話型のプログラミング環境です。コードを書いてすぐ実行し、結果を確認してから次のコードを書く、という流れができます。コード、出力、図、文章の説明をすべて 1 つのファイルにまとめられます。
どんな見た目?
ノートブックを紙のノートだと考えてみましょう。1 ページ(Cell と呼びます)は次のような内容にできます。
- 実行できるコード
- Markdown の文章(見出し、説明、数式)
- コード実行後の出力(数字、表、図)
これらが順番に並び、「実行できる文書」になります。
どんな場面で Jupyter が向いている?
| 場面 | Jupyter を使う | .py ファイルを使う |
|---|---|---|
| 探索的データ分析(EDA) | ✅ 最適 | ❌ |
| 図の作成と可視化 | ✅ 図がその下に直接表示される | ❌ ポップアップが必要 |
| 学習と実験 | ✅ 少しずつ実行しながら試せる | ❌ |
| 成果の見せ方(上司に見せるなど) | ✅ コード + 図 + 文章を一体化できる | ❌ |
| 正式なプロジェクトコード | ❌ | ✅ より保守しやすい |
| 複雑なプログラムのデバッグ | ❌ | ✅ |
| チーム開発 | ❌ マージ衝突が多い | ✅ |
一言でいうと、学習と実験は Jupyter、正式なコードは .py ファイルです。このコースの前半では Jupyter をたくさん使います。
インストールと起動
インストール
正しい conda 環境にいることを確認してください。
conda activate ai-course
# Jupyter Notebook をインストール
pip install jupyter
# (オプション)JupyterLab をインストール — Jupyter の強化版で、より現代的な画面です
pip install jupyterlab
起動
# Jupyter Notebook を起動(クラシック版)
jupyter notebook
# または JupyterLab を起動(推奨)
jupyter lab
実行すると、ターミナルには次のような情報が表示されます。
[I 10:00:00 NotebookApp] Serving notebooks from local directory: /Users/zhangsan
[I 10:00:00 NotebookApp] http://localhost:8888/?token=abc123...
ブラウザが自動で開き、Jupyter の画面が表示されます。
VS Code の Jupyter 拡張機能をインストールしていれば、ブラウザ版を起動しなくても VS Code で .ipynb ファイルを作成して実行できます。新しく .ipynb ファイルを作るだけで OK です。今後のコースでは、どちらの方法でも使えます。
新しい Notebook を作成する
Jupyter の画面で:
- 右上の New → Python 3 をクリックする(クラシック版)
- または左側の + をクリックして Python 3 Notebook を選ぶ(JupyterLab)
これで新しい空の Notebook が作成されます。
Cell(セル)の基本
Notebook は 1 つ 1 つの Cell で構成されています。Cell には 2 種類あります。
Code Cell(コードセル)
Python コードを書いて実行するために使います。
# Cell 1: 変数を定義する
name = "AI フルスタック学習"
year = 2026
Shift + Enter で実行します。
# Cell 2: 上で定義した変数を使う
print(f"{name} コースへようこそ!今は {year} 年です。")
出力:
AI フルスタック学習チュートリアルへようこそ!今は 2026 年です。
重要な特徴: Cell 同士で変数を共有します。Cell 1 で定義した name を、Cell 2 でそのまま使えます。
Markdown Cell(文字セル)
文章の説明、見出し、リスト、数式などを書くために使います。切り替え方法:
- Cell を選択して
Mを押すと Markdown に切り替わる Yを押すと Code に戻る
Markdown Cell には次のように書けます。
## ステップ 1: データを読み込む
**Iris データセット** を使って探索的分析を行います。
- サンプル数は 150
- 特徴量は 4 つ
- クラスは 3 つ
数式: $y = wx + b$
実行すると、きれいに整形された文章として表示されます。
例: 典型的なデータ分析 Notebook の構成
[Markdown] # Iris データセットの探索的分析
[Markdown] ## 1. ライブラリをインポート
[Code] import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
[Markdown] ## 2. データを読み込む
[Code] from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = iris.target
df.head()
[Output] (表を表示)
[Markdown] ## 3. データの概要を見る
[Code] df.describe()
[Output] (統計要約の表を表示)
[Markdown] ## 4. 可視化
[Code] plt.figure(figsize=(10, 6))
plt.scatter(df.iloc[:, 0], df.iloc[:, 1], c=df['species'])
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.title('Iris Dataset')
plt.show()
[Output] (散布図を直接表示)
[Markdown] ## 5. 結論
花びらの長さと花びらの幅は、3 つの品種を見分けるのに最も有効な特徴です。
コード、図、文章の説明を 1 つのファイルにまとめられます。これが Jupyter の魅力です。
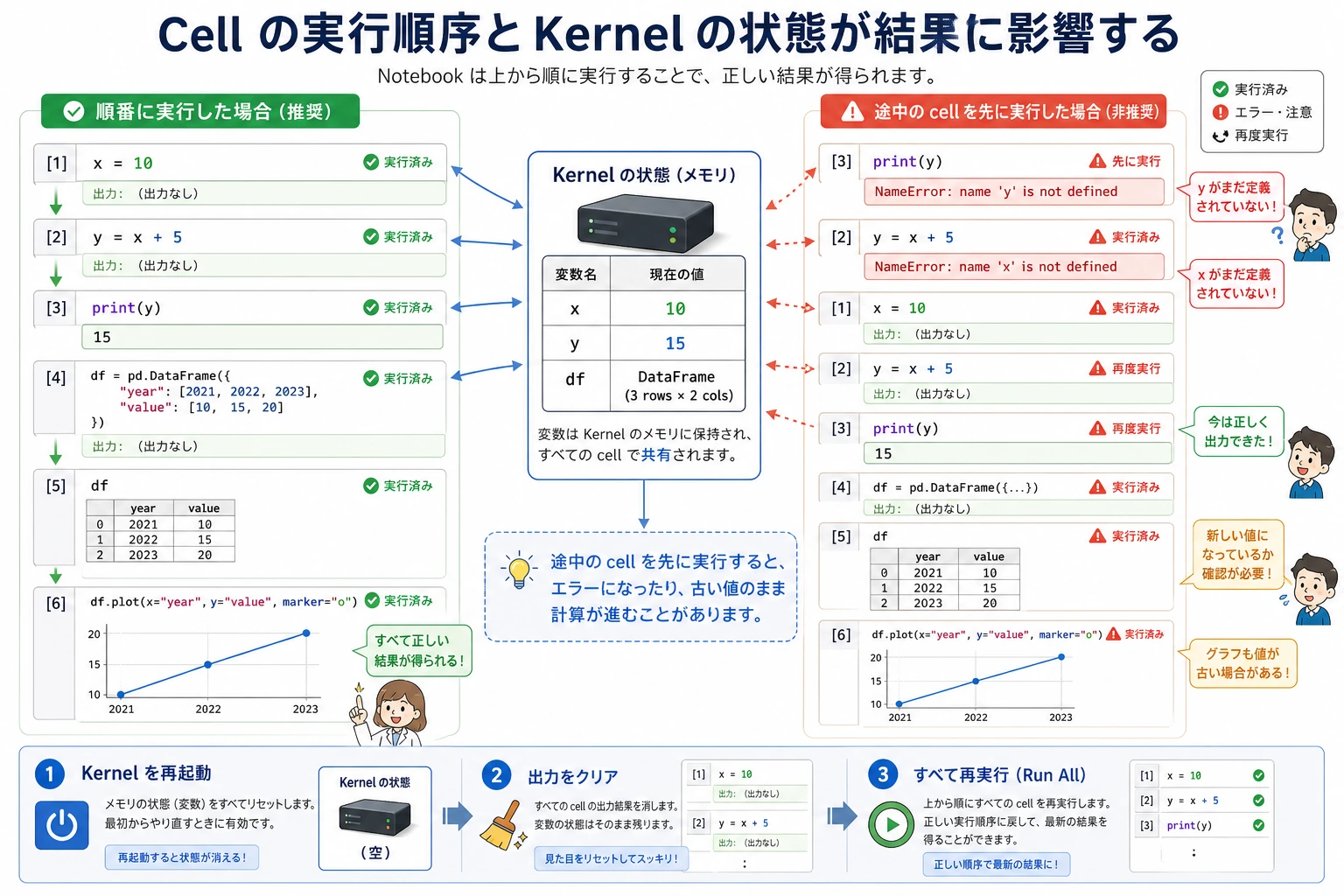
Kernel の状態:Notebook バグの隠れた原因
Notebook は文書のように見えますが、動き方は小さなプログラムに近いです。Kernel は Notebook の裏側で動いている Python プロセスで、前に作った変数を覚えています。たとえ、その Cell を移動したり削除したり、今画面に見えていなかったりしてもです。
これは便利ですが、初心者がつまずきやすい点でもあります。Notebook が動いた理由は、ファイルが上から下まで完全だからではなく、たまたま特別な順番で Cell を実行したからかもしれません。
信頼できる Notebook のルール
Notebook を信じる前、人に共有する前、教材として整理する前に、次の確認をします。
- ファイルを保存する。
- Restart Kernel and Run All Cells を選ぶ。
- 途中で失敗したら、最初の Cell から最後の Cell まで自動で実行できるように直す。
import、設定、データ読み込みは上の方に置き、実験や図はその後に置きます。これは Notebook 版の「プロジェクトがまだ最後までビルドできるか確認する」作業だと考えてください。
ショートカットキー
Jupyter には 2 つのモードがあります。
- コマンドモード(Cell の枠が青色):
Escで入る。Cell の管理に使う - 編集モード(Cell の枠が緑色):
Enterで入る。内容の編集に使う
コマンドモードのショートカット(Esc の後に使う)
| ショートカット | 操作 |
|---|---|
Shift + Enter | 現在の Cell を実行して次へ移動する(いちばんよく使う) |
Ctrl + Enter | 現在の Cell を実行するが移動しない |
A | 上に新しい Cell を挿入する |
B | 下に新しい Cell を挿入する |
DD(D を 2 回連続で押す) | 現在の Cell を削除する |
M | 現在の Cell を Markdown に変更する |
Y | 現在の Cell を Code に変更する |
Z | Cell の削除を取り消す |
↑ / ↓ | 選択中の Cell を上下に移動する |
編集モードのショートカット(Enter の後に使う)
| ショートカット | 操作 |
|---|---|
Shift + Enter | 実行して次へ移動する |
Tab | コード補完 |
Shift + Tab | 関数のドキュメントを表示する |
Ctrl + / | コメント/コメント解除 |
Ctrl + Z | 元に戻す |
実践: ショートカットを練習する
新しい Notebook を作って、次のように試してみましょう。
- 最初の Cell に
print("Cell 1")と入力し、Shift + Enterで実行する Bを押して下に新しい Cell を作るprint("Cell 2")と入力し、Ctrl + Enterで実行する(カーソルが移動しない点に注意)Escを押してコマンドモードに戻るAを押して上に Cell を挿入するMで Markdown に切り替え、# 私のタイトルと入力してShift + Enterで表示する- 不要な Cell を選んで
DDで削除する
何回か繰り返すと、すぐに体が覚えてきます。
マジックコマンド
Jupyter には、% や ! で始まる特別なコマンドがあります。これを「マジックコマンド」と呼びます。普通の Python コードではできないことができます。
! コマンド: Cell 内でターミナルコマンドを実行する
# パッケージをインストールする(ターミナルに切り替えなくてよい)
!pip install seaborn
# 現在のディレクトリを表示する
!ls
# Python のバージョンを表示する
!python --version
# ファイルをダウンロードする
!wget https://example.com/data.csv
%timeit: コードの実行時間を測る
import numpy as np
# 1 行のコードの実行時間を測る
%timeit np.random.rand(1000, 1000)
# 出力: 5.23 ms ± 128 µs per loop
%%timeit
# Cell 全体の実行時間を測る(%% である点に注意)
data = np.random.rand(1000, 1000)
result = np.dot(data, data.T)
# 出力: 15.6 ms ± 1.2 ms per loop
%matplotlib inline: 図を Notebook 内に表示する
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0, 10, 100)
plt.plot(x, np.sin(x))
plt.title("正弦関数")
plt.show()
# 図が Cell の下に直接表示される
新しい Jupyter では、%matplotlib inline は通常デフォルト動作なので、省略できることが多いです。ただし、書いても問題ありません。
%who: 現在定義されている変数を確認する
name = "張三"
age = 25
scores = [90, 85, 92]
%who
# 出力: age name scores
%whos
# 変数の詳細情報(型、値)を表示する
よく使うマジックコマンド一覧
| コマンド | 用途 |
|---|---|
!コマンド | ターミナルコマンドを実行する |
%timeit | 1 行のコードの実行時間を測る |
%%timeit | Cell 全体の実行時間を測る |
%matplotlib inline | 図をインライン表示する |
%who / %whos | 現在の変数を確認する |
%reset | すべての変数を消去する(やり直し) |
%pwd | 現在のディレクトリを表示する |
%history | 入力履歴を表示する |
Notebook と .py ファイルの違い
いつ Notebook を使う?
- データ分析、EDA
- 新しいライブラリの学習、実験
- 図の作成と可視化
- 他の人に見せる用(例: Kaggle Notebook)
- 教材の作成
いつ .py ファイルを使う?
- 正式なプロジェクトコード(モデル定義、学習スクリプト、API サービス)
- 他のファイルから import されるモジュール
- コマンドライン引数付きで実行するスクリプト
- チーム開発のコード
典型的な AI プロジェクトでは、両方を組み合わせる
my-ai-project/
├── notebooks/
│ ├── 01_eda.ipynb # データを探索する(Notebook)
│ ├── 02_experiment.ipynb # いろいろなモデルを試す(Notebook)
│ └── 03_analysis.ipynb # 結果を分析する(Notebook)
├── src/
│ ├── model.py # モデル定義(.py)
│ ├── train.py # 学習スクリプト(.py)
│ ├── evaluate.py # 評価スクリプト(.py)
│ └── utils.py # ユーティリティ関数(.py)
├── data/
├── models/
├── requirements.txt
└── README.md
まず Notebook で実験し、方針が決まったらコードを .py ファイルに整理する。これが AI エンジニアの標準的なワークフローです。
Notebook から .py ファイルのコードを呼び出す
# Notebook から自作モジュールを import する
import sys
sys.path.append('../src') # src ディレクトリをパスに追加する
from model import SimpleCNN
from utils import accuracy
model = SimpleCNN()
print(f"モデルのパラメータ数: {sum(p.numel() for p in model.parameters())}")
実践練習
Notebook を作成して、次の練習を行ってください。
Cell 1(Markdown):
# 私の最初の Jupyter Notebook
今日の日付: 2026 年 X 月 X 日
Cell 2(Code):
# 基本計算
import math
print(f"円周率: {math.pi:.10f}")
print(f"自然対数の底: {math.e:.10f}")
print(f"10! = {math.factorial(10)}")
Cell 3(Code):
# リスト操作
fruits = ["りんご", "バナナ", "オレンジ", "ぶどう", "スイカ"]
for i, fruit in enumerate(fruits, 1):
print(f"{i} 番目の果物: {fruit}")
Cell 4(Code):
# 簡単な可視化
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0, 2 * np.pi, 100)
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
axes[0].plot(x, np.sin(x), color='blue')
axes[0].set_title('sin(x)')
axes[1].plot(x, np.cos(x), color='red')
axes[1].set_title('cos(x)')
plt.tight_layout()
plt.show()
Cell 5(Code):
# 性能を測る
%timeit sum(range(100000))
%timeit np.sum(np.arange(100000))
# Python 標準の sum と NumPy の sum の速度差を比べる
Cell 6(Markdown):
## まとめ
- Cell の作成と実行を学んだ
- Notebook で図を描く方法を学んだ
- NumPy が標準の Python よりかなり速いことがわかった(だから 3 データ分析と可視化で NumPy を学ぶのです!)
1 開発者ツール基礎のセルフチェック
おめでとうございます。これで 1 開発者ツール基礎をすべて終えました。学んだ内容を振り返ってみましょう。
- ターミナル: コマンドラインで移動し、ファイルを操作し、パイプとリダイレクトを使える
- Git: リポジトリを作成し、コードをコミットし、GitHub に push し、ブランチを使える
- Python 環境: Miniconda で仮想環境を作成・管理できる
- VS Code: VS Code でコードを書き、デバッグし、ショートカットを使える
- Jupyter: Notebook を作成し、コードを実行し、図を描き、文書を書ける
あなたはすでに、プロ向けの AI 開発環境を手に入れています。これらのツールは、これからの学習全体を支えてくれます。次は、いよいよ Python プログラミングの学習を始めましょう!