10.2.3 现代分类架构
做图像分类时,模型结构不是“越新越好”, 而是在不断围绕几个核心问题演化:
- 怎么让网络更深
- 怎么让训练更稳
- 怎么让算力利用更高
这一节不是给你背模型名字,而是帮你抓住它们演化背后的动机。
学习目标
- 理解几代主流图像分类架构在解决什么问题
- 理解残差连接为什么改变了深层网络训练
- 理解效率型架构为什么重要
- 建立架构选择时的基本判断
先建立一张地图
如果你刚学完数据增强,这一节最自然的续接就是:
- 前一节在解决“同样一张图可以怎样更稳地喂给模型”
- 这一节开始解决“模型骨架本身该怎么设计得更强、更稳、更省”
所以这一节不是在单独背架构名字,而是在补图像分类里的另一半:
- 数据怎么准备
- 网络怎么搭得合理
现代分类架构这节最适合新人的理解顺序不是“看一串名字”,而是先看清架构演进在回答什么问题:
所以这节真正想解决的是:
- 图像分类网络为什么会一路演进
- 不同架构到底在补哪类瓶颈
一个更适合新人的总类比
你可以把分类架构演进理解成:
- 工厂流水线一次次升级改造
每一代改造都不是为了“名字更新”, 而是为了回答一些很现实的问题:
- 线能不能拉得更长
- 机器会不会越跑越不稳
- 同样电费下能不能产出更多
一、为什么图像分类架构会不断演进?
因为“更深”不自动等于“更好”
早期网络一变深,常常会遇到:
- 梯度难传
- 优化困难
- 训练不稳定
所以后续演化本质上是在回答两个问题
- 如何更好训练深网络
- 如何在性能和效率之间平衡
一个类比
架构演进像不断改造流水线:
- 不是为了让机器变花哨
- 而是为了在更复杂生产规模下还能稳定工作
第一次学这节,最该先抓住什么?
最该先抓住的不是模型年份和排行榜,而是这句:
架构演进本质上是在解决“更深怎么训、更强怎么省、更现代怎么稳”。
一旦这句稳了,后面看到任何新架构时,你都会更自然地去问:
- 它主要在补什么瓶颈?
- 它解决的是深度、稳定性,还是效率问题?
二、几代架构在关注什么?
VGG:先把“堆更深”做出来
特点:
- 结构规则
- 全是小卷积
- 网络更深
它的意义在于:
- 证明更深网络可以明显提升能力
ResNet:让更深网络真正能训
残差连接的核心直觉是:
- 不要求每层都学一个全新变换
- 而是学“在原基础上的增量”
这让深层网络训练稳定性大幅提升。
为什么 ResNet 会成为图像分类里最重要的分水岭之一?
因为它第一次比较系统地解决了一个很关键的问题:
- 网络想变深
- 但深了以后又很难训练
ResNet 的意义,不只是“分数变高”,而是它把:
- 更深网络
- 可训练性
这两件事真正接上了。
EfficientNet:开始认真看算力效率
它不只问“能不能更强”, 还问:
- 同样预算下怎样更划算
ConvNeXt:重新审视卷积体系
在 Transformer 强势之后, 卷积路线也开始重新整理和现代化。
这说明:
- 架构演进并不是单线淘汰
一张更适合新人的架构对比表
| 架构 | 你最该先记住的特点 | 适合建立什么直觉 |
|---|---|---|
| VGG | 深、规则、好理解 | 更深网络为什么会更强 |
| ResNet | 残差连接 | 深网络怎么训得更稳 |
| EfficientNet | 性能和效率一起看 | 为什么不能只看精度 |
| ConvNeXt | 卷积也能继续现代化 | 架构不是新旧二元对立 |
第一次学架构演进,最容易学歪在哪里?
最容易学歪成:
- 一堆模型名
- 一堆层数
- 一堆排行榜结论
但真正更值钱的学习方式应该是:
- 先问它的动机
- 再问它的结构变化
- 最后问它在项目里值不值得作为 baseline
如果把它们放到“项目选择”里,该怎么理解?
一个更实用的记法是:
VGG:更像教学上的经典起点,适合建立“深度和结构感”ResNet:最稳的工程 baseline,很多项目第一反应还是先上它EfficientNet:当你开始在意“同等资源下更划算”时特别有价值ConvNeXt:当你想理解“卷积体系也能继续现代化”时再看会更合适
一个新人很适合先记的架构选择表
| 你的目标 | 更稳的第一反应 |
|---|---|
| 第一次做图像分类项目 | ResNet |
| 想理解深网络为什么能训稳 | ResNet |
| 想兼顾效果和效率 | EfficientNet |
| 想补视觉架构演进视角 | VGG -> ResNet -> ConvNeXt |
这个表很适合初学者,因为它会把“模型名”重新变成“什么时候我该先想到它”。
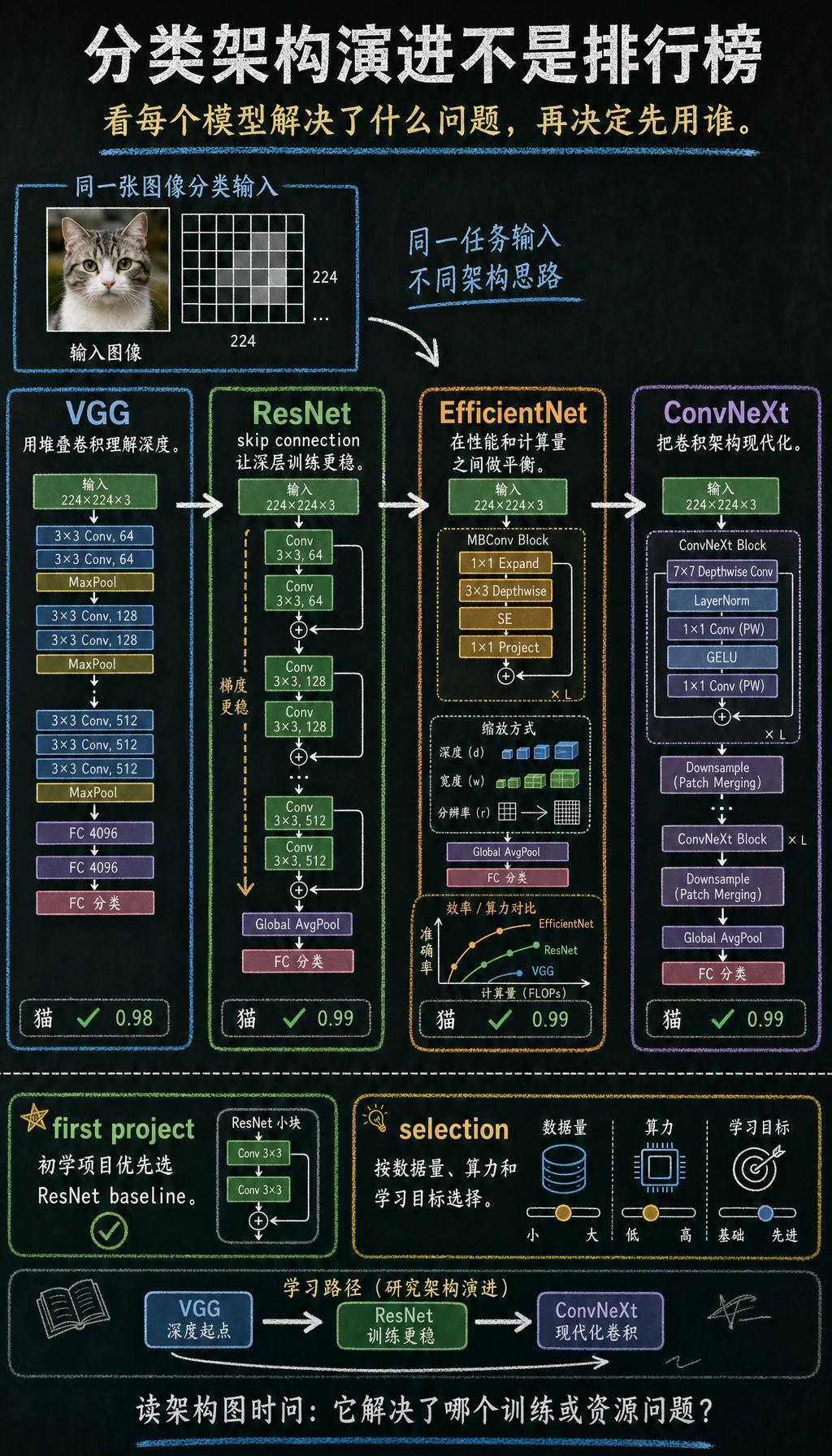
这张图不要当模型排行榜看,而要当“问题演进图”看:VGG 先证明深度有效,ResNet 解决深层可训练性,EfficientNet 关注效率,ConvNeXt 代表卷积路线的现代化整理。
三、先用一个最小残差示例建立直觉
def block_without_residual(x):
transformed = x * 0.6 + 0.2
return transformed
def block_with_residual(x):
transformed = x * 0.6 + 0.2
return x + transformed
x = 1.0
print("without residual:", block_without_residual(x))
print("with residual :", block_with_residual(x))
预期输出:
without residual: 0.8
with residual : 1.8
这个例子想表达什么?
残差连接的感觉可以先理解成:
- 不是把旧信息完全替换
- 而是在旧信息上叠加一个新修正
这对深层网络训练非常重要。
为什么这和“更深但更稳”有关?
因为当层数很深时, 完全重写表示比“逐层微调表示”更难学。
第一次看残差连接,最值得先记的不是公式,而是“保留原路”
可以先把残差块理解成:
- 新分支在学修正
- 原路在保留已有信息
这会让你更容易理解为什么它能帮助深层网络:
- 信息不必每一层都被强行重写
- 梯度也更容易传回去
新人第一次学这节,最该先记什么?
最值得先记住的是:
- 架构演进不是“新模型不断替代旧模型”
- 很多改进都在解决训练稳定性和效率问题
- ResNet 之所以重要,不只是因为它强,而是因为它把“更深还能训”这件事做成了
四、现代分类架构到底怎么选?
如果你是入门做 baseline
优先考虑:
- ResNet 一类经典强基线
如果你资源特别敏感
更应该关注:
- EfficientNet
- 更轻量卷积架构
如果你要做研究或强性能对比
那才更值得系统比较不同家族。
第一次做图像分类项目时,怎么选更稳?
一个够稳的顺序通常是:
- 先用 ResNet 做强 baseline
- 如果资源真的敏感,再看 EfficientNet 这类效率型路线
- 真要做更深入对比,再研究更多家族
这样会比一开始就追最时髦架构更容易把项目做扎实。
一个更适合新人的实际选择表
| 你的场景 | 更稳的第一选择 |
|---|---|
| 第一次做图像分类项目 | ResNet |
| 设备资源有限 | EfficientNet 或轻量卷积网络 |
| 想理解卷积体系演进 | VGG -> ResNet -> ConvNeXt |
| 想做更认真架构对比 | 再系统比较不同家族 |
第一次把架构放进项目里,最稳的默认顺序
更稳的顺序通常是:
- 先用 ResNet 立强 baseline
- 先看数据和训练流程是否已经稳定
- 如果资源真的敏感,再换效率型架构
- 最后再做架构家族对比
这样会比一开始就追“最先进 backbone”更容易看清收益来自哪里。
五、最常见误区
误区一:只记名字不记问题
更重要的是知道:
- 它到底在解决什么瓶颈
误区二:最新架构一定更适合当前项目
现实里经常还是成熟强基线更稳。
误区三:网络越深越一定更强
没有好的优化结构,深度很容易变成负担。
七、一个很实用的复盘问题
每学完一种架构,都可以问自己:
- 它主要想解决什么问题?
- 它是在换“表示能力”,还是在换“训练稳定性 / 效率”?
- 如果放进真实项目,我为什么会选它?
如果这三个问题都能答清楚,这节课就不再只是模型名列表了。
如果把它做成项目或笔记,最值得展示什么
最值得展示的通常不是:
- 一串模型排行榜
而是:
- 你为什么先选 ResNet 做 baseline
- 你为什么考虑换到更效率型架构
- 不同架构是在解决深度、稳定性,还是效率问题
这样别人会更容易看出:
- 你理解的是架构选择逻辑
- 不只是记住了名字
小结
这节最重要的是建立一个架构演进视角:
图像分类架构的发展,本质上是在不断解决“更深怎么训、更强怎么省、更现代怎么稳”这几个问题。
只要这个视角在,后面你看到新模型时就不会只剩名字。
这节最该带走什么
- 架构名字背后对应的是瓶颈和设计动机
- ResNet 是第一次学视觉分类架构时最值得真正看懂的一条线
- 做项目时,稳定 baseline 往往比盲目追新更重要
如果再压成一句话,那就是:
现代分类架构最重要的不是“谁更新”,而是谁更清楚地解决了训练深网络和提高效率这两个现实问题。
练习
- 用自己的话解释:为什么残差连接会让深层网络更容易训练?
- 为什么说 EfficientNet 更像“预算优化”思路?
- 如果你要做一个资源有限的移动端分类器,你会优先考虑哪类架构?
- 想一想:为什么架构选择不该只看排行榜?