10.1.2 数字图像基础
![]()
学习目标
完成本节后,你将能够:
- 理解图像的像素表示和颜色通道
- 分清灰度图和彩色图的存储方式
- 理解 RGB 与 HSV 的区别
- 知道常见图像格式适合什么场景
这节和第 6 站 CNN 主线是怎么接上的
如果你刚学完卷积网络,可以先把这节理解成:
- CNN 告诉你网络为什么适合看图
- 这节开始把“图”这个输入对象本身拆开给你看
所以这节不是在偏离模型主线,而是在补最关键的一层输入直觉:
- 图像在计算机里到底是什么
- 为什么通道、颜色空间、尺寸这些概念后面会反复出现
一、计算机眼中的图片到底是什么?
人看到一张猫的照片,会想到“这是一只猫”。 计算机看到的其实不是“猫”,而是一大堆数字。
最简单的理解:
图像 = 一个按位置排好的数字矩阵
你可以把它想成一个“灯光棋盘”:
- 每个格子就是一个像素(pixel)
- 每个像素里存着亮度或颜色数值
- 所有像素排在一起,就组成了整张图
第一次学视觉,最该先抓住什么?
最该先抓住的不是“这张图是什么内容”,而是:
对计算机来说,图像首先是一块按空间排列好的数字网格。
只要这句稳了,后面很多操作都会顺很多:
- 卷积为什么按局部窗口滑动
- 通道为什么能拆开处理
- 检测和分割为什么还离不开像素空间
二、像素:图像的最小单位
灰度图
灰度图里,每个像素只需要一个数字表示亮度:
0表示纯黑255表示纯白- 中间值表示不同程度的灰
import numpy as np
# 一个 5x5 的灰度图
gray = np.array([
[0, 50, 100, 150, 200],
[30, 80, 130, 180, 230],
[60, 110, 160, 210, 255],
[20, 70, 120, 170, 220],
[10, 40, 90, 140, 190]
], dtype=np.uint8)
print("灰度图 shape:", gray.shape)
print(gray)
预期输出:
灰度图 shape: (5, 5)
[[ 0 50 100 150 200]
[ 30 80 130 180 230]
[ 60 110 160 210 255]
[ 20 70 120 170 220]
[ 10 40 90 140 190]]
这里的 shape 是 (5, 5),表示:
- 高度 5
- 宽度 5
也就是说,这张图只有 25 个像素。
彩色图
彩色图一般使用 RGB 表示颜色:
R= 红色强度G= 绿色强度B= 蓝色强度
每个像素不再是一个数,而是三个数。
import numpy as np
# 一个 2x2 的 RGB 图像
rgb = np.array([
[[255, 0, 0], [ 0, 255, 0]],
[[ 0, 0, 255], [255, 255, 0]]
], dtype=np.uint8)
print("RGB 图 shape:", rgb.shape)
print(rgb)
预期输出:
RGB 图 shape: (2, 2, 3)
[[[255 0 0]
[ 0 255 0]]
[[ 0 0 255]
[255 255 0]]]
这里 shape = (2, 2, 3),表示:
- 高 2
- 宽 2
- 每个像素 3 个通道
这一节最值得先养成的习惯
看到图像数组时,先顺手问这三个问题:
- 它的 shape 是多少?
- 每一维分别代表什么?
- 通道是在最后一维,还是前一维?
这个习惯会直接帮你少掉很多视觉代码里的 shape 混乱。
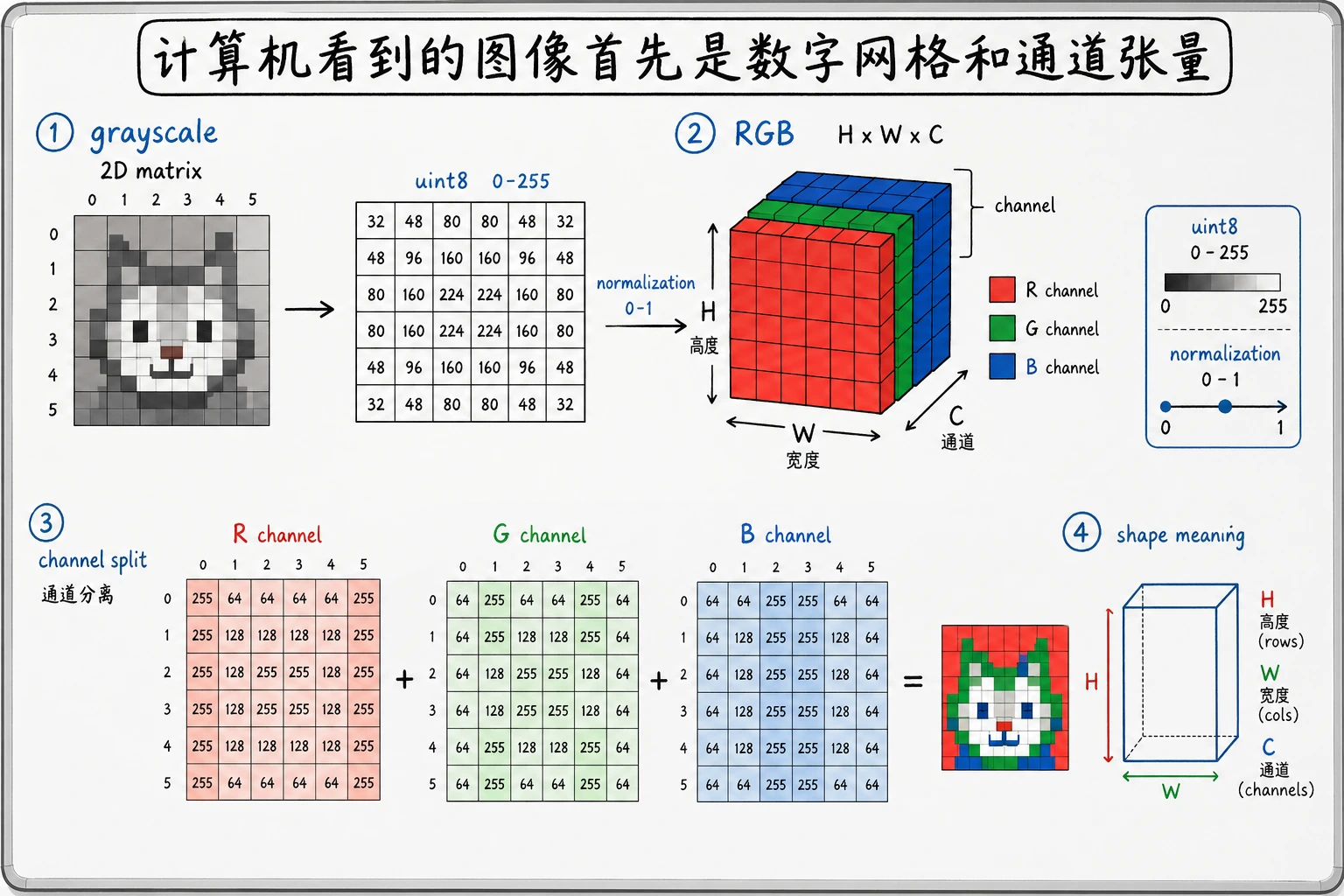
这张图按 height -> width -> channel 读:灰度图通常是二维网格,RGB 图像多出颜色通道,模型训练前还会把 uint8 的 0-255 转成更稳定的浮点范围。
三、通道是什么?
通道(channel)可以理解成“同一张图的不同颜色层”。
类比一下:
一张 RGB 图片,就像三张半透明薄膜叠在一起:一张红膜、一张绿膜、一张蓝膜。
import numpy as np
rgb = np.array([
[[255, 0, 0], [ 0, 255, 0]],
[[ 0, 0, 255], [255, 255, 0]]
], dtype=np.uint8)
red_channel = rgb[:, :, 0]
green_channel = rgb[:, :, 1]
blue_channel = rgb[:, :, 2]
print("R 通道:\n", red_channel)
print("G 通道:\n", green_channel)
print("B 通道:\n", blue_channel)
预期输出:
R 通道:
[[255 0]
[ 0 255]]
G 通道:
[[ 0 255]
[ 0 255]]
B 通道:
[[ 0 0]
[255 0]]
在计算机视觉里,“拆通道”是非常常见的操作。
比如:
- 只分析亮度
- 只增强某种颜色
- 先转灰度再做边缘检测
通道最值得先记的,不是定义,而是“它能单独处理”
也就是说:
- 彩色图不是一个整体黑箱
- 它其实是多张“颜色层”叠起来
这件事很关键,因为后面很多视觉处理本质上都在做:
- 拆通道
- 重组通道
- 在某个通道上单独操作
四、图像为什么常用 uint8?
大多数图片像素值范围是 0~255,所以常用 uint8 存储:
u= unsigned,无符号int8= 8 位整数- 能表示
0~255
import numpy as np
pixel = np.array([128, 200, 30], dtype=np.uint8)
print(pixel, pixel.dtype)
预期输出:
[128 200 30] uint8
但在模型训练里,我们常常会把图像归一化到 0~1:
import numpy as np
pixel = np.array([128, 200, 30], dtype=np.float32)
pixel_normalized = pixel / 255.0
print(pixel_normalized)
预期输出:
[0.5019608 0.78431374 0.11764706]
为什么要归一化?
因为神经网络更喜欢数值尺度稳定的数据。 就像做饭时每种调料都得有合理量级,不能一个用“克”、另一个用“桶”。
为什么这一点和第 6 站训练主线直接相关?
因为你在第 6 站已经见过:
- 模型训练对输入尺度很敏感
- 优化器和梯度会受数值范围影响
所以图像归一化不是视觉里的小技巧,而是:
- 视觉数据进入训练流程前的标准准备动作
五、RGB 和 HSV 有什么区别?
RGB:按“混多少红绿蓝”描述颜色
RGB 很适合存图、显示图。 但它不太符合人类描述颜色的方式。
比如人更习惯说:
- 这个颜色偏红
- 饱和度高
- 更亮一点
这时 HSV 往往更直观:
H= Hue,色相S= Saturation,饱和度V= Value,明度
一个直接可运行的小例子
import colorsys
# 红色像素,先把 0~255 映射到 0~1
r, g, b = 255 / 255, 80 / 255, 80 / 255
h, s, v = colorsys.rgb_to_hsv(r, g, b)
print("HSV:")
print("H =", round(h, 3))
print("S =", round(s, 3))
print("V =", round(v, 3))
预期输出:
HSV:
H = 0.0
S = 0.686
V = 1.0
RGB 和 HSV 适合什么场景?
| 颜色空间 | 更适合什么 |
|---|---|
| RGB | 存储、显示、神经网络输入 |
| HSV | 颜色筛选、颜色分割、按“色调/亮度”处理图像 |
比如你要“找出画面里偏红的区域”,HSV 往往比 RGB 更方便。
六、把彩色图转成灰度图
灰度图并不是简单地把三个通道平均一下。 通常会按人眼对不同颜色敏感度加权。
常见公式:
gray = 0.299*R + 0.587*G + 0.114*B
import numpy as np
rgb = np.array([
[[255, 0, 0], [ 0, 255, 0]],
[[ 0, 0, 255], [255, 255, 255]]
], dtype=np.float32)
gray = (
0.299 * rgb[:, :, 0] +
0.587 * rgb[:, :, 1] +
0.114 * rgb[:, :, 2]
)
print(gray.astype(np.uint8))
预期输出:
[[ 76 149]
[ 29 255]]
七、图像格式怎么选?
这是非常工程化但很实用的知识。
| 格式 | 特点 | 常见用途 |
|---|---|---|
| JPG / JPEG | 有损压缩,体积小 | 照片、网页展示 |
| PNG | 无损压缩,支持透明 | 图标、截图、UI 素材 |
| WebP | 压缩效率高 | 现代网页图像 |
| BMP | 基本不压缩,体积大 | 教学、底层处理 |
一个非常实用的直觉
- 照片:优先
JPG - 需要透明背景:优先
PNG - 想兼顾质量和体积:考虑
WebP
八、为什么视觉任务总在说“分辨率”?
分辨率就是图像大小,比如:
224 x 224640 x 4801920 x 1080
分辨率越高:
- 细节越多
- 计算量也越大
这就像你看地图:
- 放大后更清楚
- 但要处理的信息也更多
所以很多深度学习模型会先把图像缩放到固定大小。
九、一个小实验:统计图像亮度
下面这个例子可以帮你快速建立“图像就是数值矩阵”的感觉。
import numpy as np
gray = np.array([
[10, 20, 30],
[100, 120, 140],
[200, 220, 240]
], dtype=np.uint8)
print("最暗像素:", gray.min())
print("最亮像素:", gray.max())
print("平均亮度:", gray.mean())
预期输出:
最暗像素: 10
最亮像素: 240
平均亮度: 120.0
这在视觉任务里很常见,比如:
- 判断一张图是不是整体过暗
- 做亮度归一化
- 估计曝光情况
十、初学者常见误区
以为图像是“对象”,不是“数组”
对人来说是对象,对计算机来说先是数组。 先接受这一点,后面所有视觉算法都会顺很多。
混淆图像 shape
不同库可能约定不同:
- NumPy / OpenCV 常见
H x W x C - PyTorch 常见
C x H x W
这是后面写模型时必须特别小心的点。
以为 RGB 和 HSV 只是换个名字
不是。 它们是不同的颜色表示方式,适合的处理任务也不同。
小结
学完这节,你要建立一个关键直觉:
图像并不神秘,本质上就是带空间结构的数字矩阵。
后面无论是 OpenCV 处理、卷积神经网络,还是目标检测,本质上都在处理这些有结构的数字。
练习
- 自己创建一个
3x3的灰度图矩阵,统计它的最大值、最小值和平均值。 - 自己创建一个
2x2x3的 RGB 图像,打印每个通道。 - 把一组 RGB 像素手工转成
0~1浮点数,理解归一化的作用。