E.A.4 推論エンジン
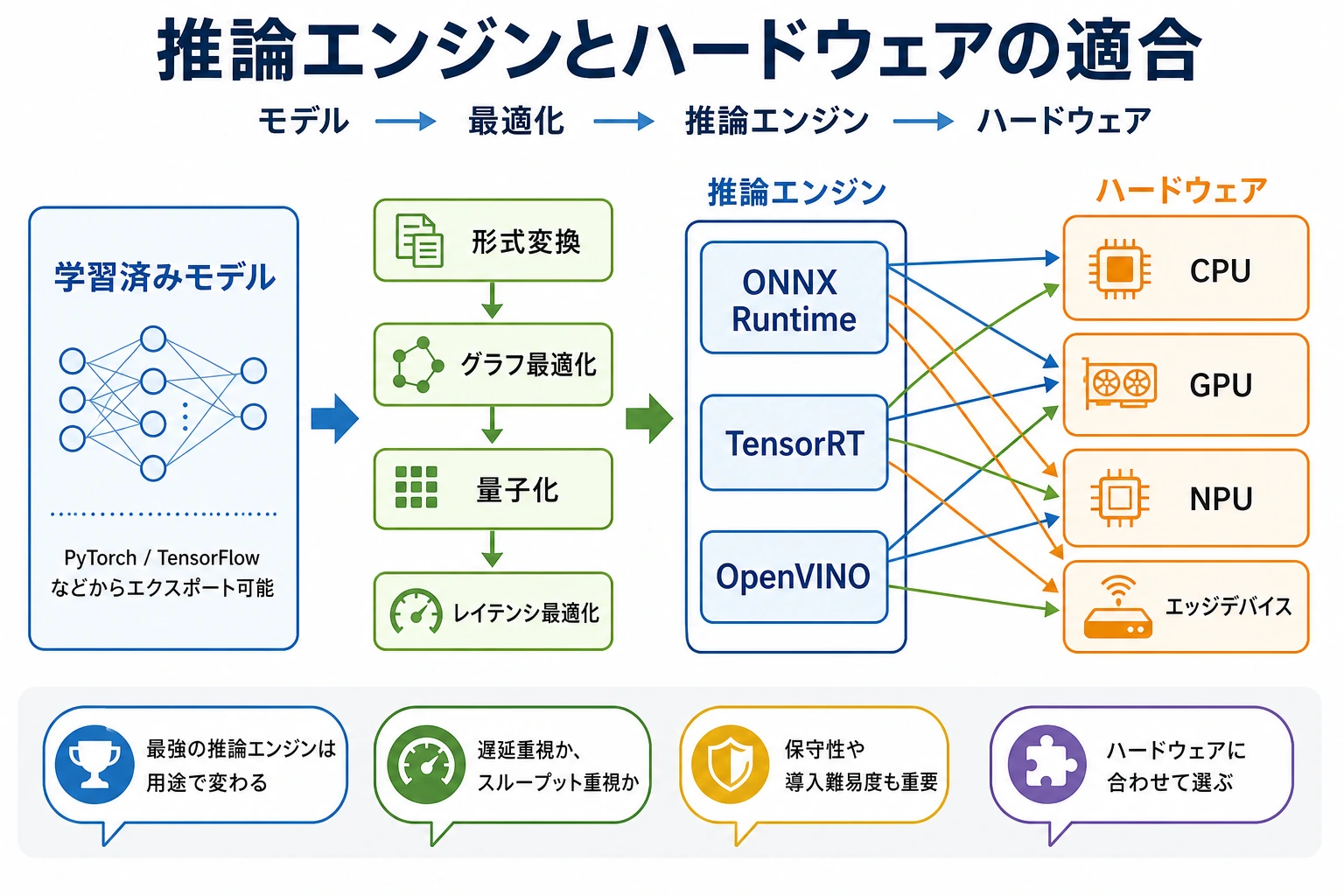
推論エンジンは、学習済みモデルと実際のハードウェアの間にある実行レイヤーです。モデルは「何を計算するか」を表し、エンジンは CPU、GPU、NPU、エッジ機器で「どう効率よく実行するか」を決めます。
この節では、まず小さな選定練習をします。どれか一つのエンジンを常に最良だと覚えるのではなく、デプロイの制約に合わせて選びます。
準備するもの
- Python 3.10+
- 外部パッケージ不要
- 5分ほどで実行して編集できるスコアリングスクリプト
重要用語
- Latency(レイテンシ):1つのリクエストが結果を受け取るまでの待ち時間。
- Throughput(スループット):システムが1秒あたりに処理できるリクエスト数。
- Backend(バックエンド):CPU、CUDA、TensorRT、OpenVINO など、特定ハードウェア向けの実行経路。
- ONNX:よく使われるモデル交換形式。
- Operator(演算子):行列積、畳み込み、正規化など、モデルグラフ内の一つの操作。
エンジン選定器を動かす
engine_selector.py を作成します。
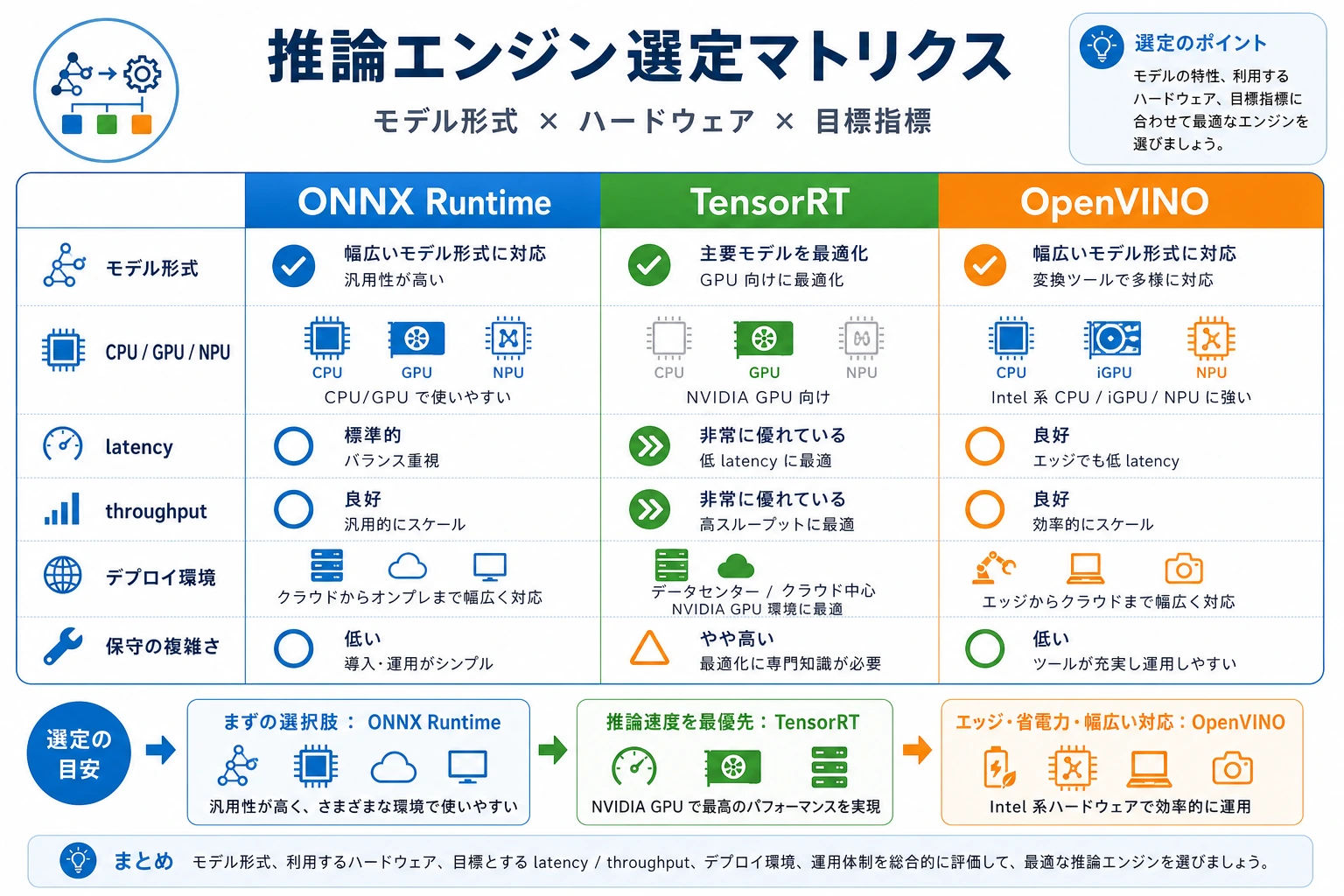
engines = [
{
"name": "ONNX Runtime",
"hardware": ["cpu", "nvidia"],
"formats": ["onnx"],
"latency": "medium",
"ops": "easy",
},
{
"name": "TensorRT",
"hardware": ["nvidia"],
"formats": ["onnx", "engine"],
"latency": "low",
"ops": "hard",
},
{
"name": "OpenVINO",
"hardware": ["cpu", "intel"],
"formats": ["onnx", "ir"],
"latency": "low",
"ops": "medium",
},
]
need = {"hardware": "nvidia", "format": "onnx", "latency": "low"}
for engine in engines:
score = 0
score += 2 if need["hardware"] in engine["hardware"] else -3
score += 2 if need["format"] in engine["formats"] else -2
score += 1 if need["latency"] == engine["latency"] else 0
score -= 1 if engine["ops"] == "hard" else 0
engine["score"] = score
best = max(engines, key=lambda item: item["score"])
for engine in engines:
print(engine["name"], engine["score"])
print("selected:", best["name"])
実行します。
python engine_selector.py
期待される出力:
ONNX Runtime 4
TensorRT 4
OpenVINO 0
selected: ONNX Runtime
ここでは ONNX Runtime と TensorRT が同点で、スクリプトは先に出てきたものを選びます。これは意図的です。実運用では、より高速な経路が構築や保守の負担を増やすなら、最初のリリースでは単純な経路のほうがよいことがあります。
制約を一つ変える
次を:
need = {"hardware": "nvidia", "format": "onnx", "latency": "low"}
print(need)
1つ目のスニペットの期待される出力:
{'hardware': 'nvidia', 'format': 'onnx', 'latency': 'low'}
次のように変更します。
need = {"hardware": "intel", "format": "onnx", "latency": "low"}
print(need)
2つ目のスニペットの期待される出力:
{'hardware': 'intel', 'format': 'onnx', 'latency': 'low'}
もう一度実行します。期待される結果:
ONNX Runtime -1
TensorRT -2
OpenVINO 5
selected: OpenVINO
要点は単純です。ハードウェアが変わると、エンジンの選択も変わります。
実用的な選定順序
高度なチューニングを始める前に、まずこの順序で確認します。
- 対象ハードウェアを確認する。
- エンジンが読み込めるモデル形式を確認する。
- 未対応の演算子がないか確認する。
- 同じ入力サイズでレイテンシとスループットを比べる。
- 目標を満たす中で、最も保守しやすいエンジンを選ぶ。
よくある間違い
- TensorRT が速いという理由だけで、engine のビルド手順を保守できるかを考えない。
- 小さすぎる入力でテストし、本番入力になってから遅さに気づく。
- リリース直前に未対応の演算子を発見する。
練習
各エンジンに memory フィールドを追加し、デバイスのメモリを超えたら 1 点減点してください。その後、CPU-only、NVIDIA GPU、Intel デバイスの3つの場面で選び直します。