9.10.2 プロジェクト:インテリジェント研究アシスタント
研究アシスタントのプロジェクトは、Agent の作品集としてとても向いています。
見た目が派手だからではなく、仕組みとして自然に次のことを同時にうまくやる必要があるからです。
- 検索
- 読解
- 要約
- 引用の追跡
このどれか1つでも弱いと、結果はすぐに「信頼できない」ものになります。
だからこそ、「信頼できる Agent」を練習する主軸としてぴったりです。
学習目標
- 研究アシスタントのプロジェクト範囲を明確に決められるようになる
- 「検索 -> 読解 -> 要約 -> 引用」をひとつの流れとしてつなげられるようになる
- このプロジェクトで最も重要な評価基準を定義できるようになる
- これを説得力のある作品集プロジェクトとして見せられるようになる
まずはプロジェクト範囲を絞る
練習用の研究アシスタントプロジェクトは、まず次の形から始めるのがおすすめです。
- テーマを与える
- 複数の文書を検索する
- 構造化された要約を出す
- 各要約に出典を付ける
最初から次のようなことをやろうとしないことが大切です。
- 論文を自動で書く
- レビュー論文を自動で作る
なぜでしょう?
研究アシスタントでは、「派手さ」より「信頼性」のほうがずっと重要だからです。
作品レベルの研究アシスタントの最小閉ループはどんな形?
- テーマや質問を入力する
- 候補資料を検索する
- 最も関連性の高い資料を選ぶ
- 構造化要約を生成する
- 各要約に出典を付ける
- エラー分析と回帰用データセットを作る
この6ステップがはっきりしていれば、このプロジェクトには作品集として十分な価値があります。
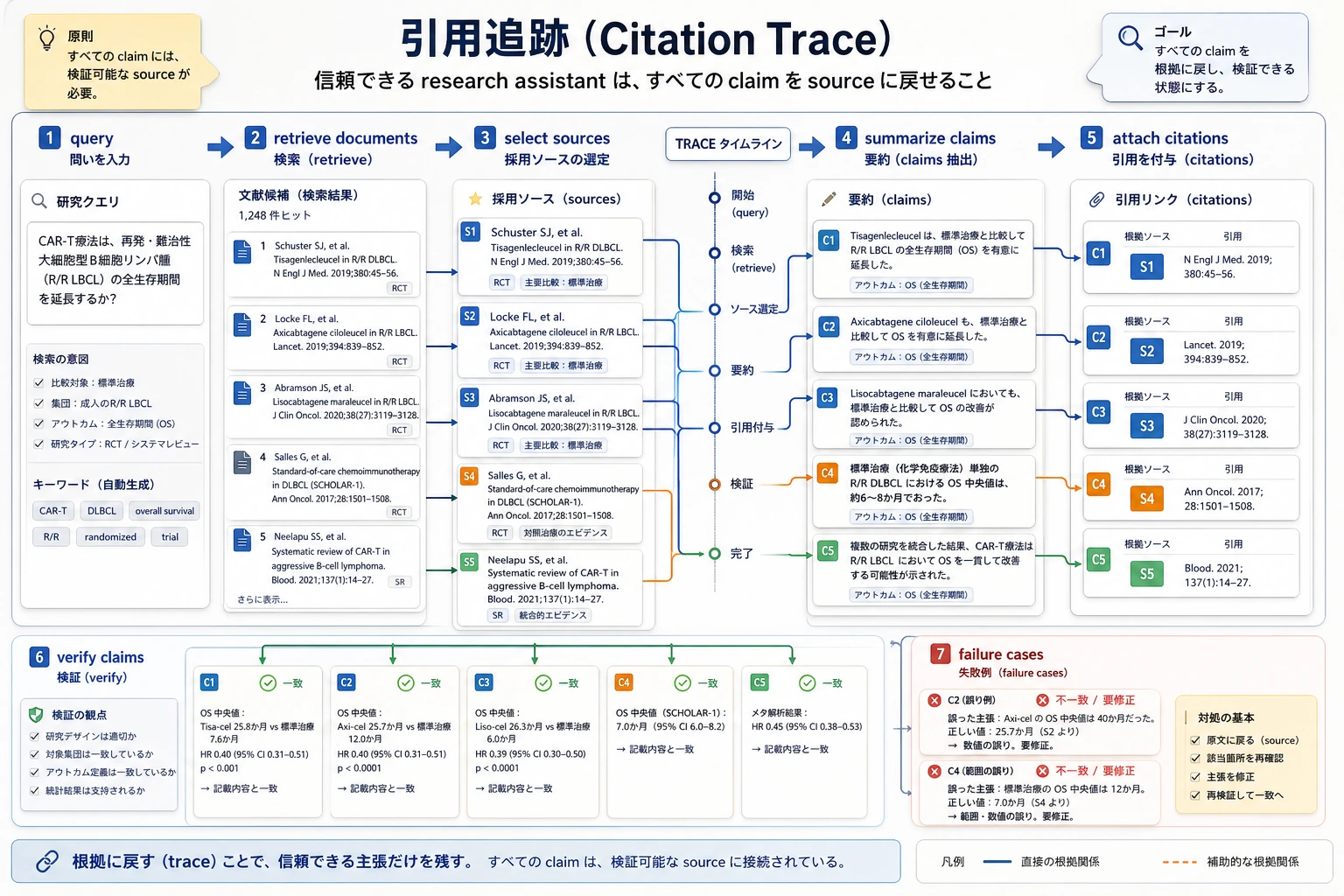
研究アシスタントで最も大切なのは「要約が滑らかであること」ではなく、claim が source に戻れることです。
図を見るときは、retrieve、select、summarize、cite、verify の流れに沿って、各結論に根拠があるかを確認しましょう。
おすすめの進め方
初心者には、次の順番が比較的安全です。
- まずテーマの範囲を狭くする
- その次に最もシンプルな検索 baseline を作る
- それから構造化要約を追加する
- 最後に引用チェックと失敗例の表示を追加する
こうすることで、「信頼できる研究アシスタント」をきちんとした閉ループとして作りやすくなります。
まずは最小の研究アシスタント例を見てみよう
以下の例では、3つのことを行います。
- キーワード一致を使って検索をまねる
- 構造化要約を作る
- 各要約に出典を付ける
docs = [
{
"id": "d1",
"title": "RAG improves factual grounding",
"text": "RAG can improve factual grounding by retrieving external evidence.",
"keywords": {"rag", "retrieval", "grounding", "evidence"},
},
{
"id": "d2",
"title": "Long context still struggles with precision",
"text": "Long context models may still miss key details without retrieval or re-ranking.",
"keywords": {"long", "context", "retrieval", "ranking"},
},
{
"id": "d3",
"title": "Citations increase user trust",
"text": "Users trust generated summaries more when each claim is tied to an explicit source.",
"keywords": {"citation", "trust", "summary", "source"},
},
]
def retrieve(query, top_k=2):
query_terms = set(query.lower().split())
scored = []
for doc in docs:
score = len(query_terms & doc["keywords"])
scored.append((score, doc))
scored.sort(key=lambda x: x[0], reverse=True)
return [doc for score, doc in scored[:top_k] if score > 0]
def summarize_with_citations(query):
hits = retrieve(query, top_k=2)
bullets = []
for doc in hits:
bullets.append(
{
"claim": doc["text"],
"source_id": doc["id"],
"source_title": doc["title"],
}
)
return bullets
query = "rag retrieval citation trust"
result = summarize_with_citations(query)
for item in result:
print(item)
実行結果の例:
{'claim': 'RAG can improve factual grounding by retrieving external evidence.', 'source_id': 'd1', 'source_title': 'RAG improves factual grounding'}
{'claim': 'Users trust generated summaries more when each claim is tied to an explicit source.', 'source_id': 'd3', 'source_title': 'Citations increase user trust'}
この例が「project skeleton の dataclass」より価値があるのはなぜ?
それは、研究アシスタントで最も重要な製品特性がすでに表れているからです。
- 結果が単なるブラックボックス要約ではない
- 各結論を元の情報源までたどれる
なぜ引用がこの種のプロジェクトの命綱なのか?
出典がなければ、ユーザーは次の区別がつきにくいからです。
- システムが本当に文書から読んだ内容なのか
- それともモデルが勝手に作った内容なのか
このプロジェクトで最も大事な評価は何?
検索品質
たとえば:
- ヒットした文書は本当に関連しているか
要約品質
たとえば:
- 重要ポイントをきちんと含んでいるか
- 過度にまとめすぎていないか
引用の正確性
これは研究アシスタントで特に重要な観点です。
- 各 claim が、本当に引用元で裏付けられているか
最小の評価データ構造
同じファイルまたは同じ Python セッションで続けて実行してください。このブロックは summarize_with_citations() を再利用します。
eval_cases = [
{
"query": "rag retrieval grounding",
"expected_source_ids": {"d1", "d2"},
},
{
"query": "citation trust summary",
"expected_source_ids": {"d3"},
},
]
for case in eval_cases:
hit_ids = sorted(item["source_id"] for item in summarize_with_citations(case["query"]))
overlap = sorted(set(hit_ids) & case["expected_source_ids"])
print({
"query": case["query"],
"hit_ids": hit_ids,
"overlap": overlap,
})
実行結果の例:
{'query': 'rag retrieval grounding', 'hit_ids': ['d1', 'd2'], 'overlap': ['d1', 'd2']}
{'query': 'citation trust summary', 'hit_ids': ['d3'], 'overlap': ['d3']}

いちばんハマりやすい落とし穴
検索は合っているのに、要約で重要点が抜ける
要約は自然に読めるのに、出典が合っていない
プロジェクトが「賢そうに見える答え」を1つ見せるだけになっている
研究アシスタントで本当に見せる価値があるのは、実は次の流れです。
- クエリ
- 検索結果
- 要約項目
- 引用元
この完全な trace です。
どうやって作品レベルに磨き上げる?
ページを4カラムで見せる
- Query
- Retrieved sources
- Structured summary
- Citations
5〜10個の固定評価問題を用意する
こうすると、次の比較を安定して見せられます。
- before / after
- 検索戦略の変更
- 要約戦略の改善
失敗例を別に載せる
たとえば:
- 関連性の低い文書を検索してしまう
- 正しい文書を取りこぼす
- 要約の claim と引用が一致しない
プロジェクト提出時に追加したい内容
- クエリから引用までの流れ図
- 検索結果と最終要約を並べた表示
- 引用不一致や要約の抜けがある失敗例
- 「信頼できる出力」をどう定義するかの説明
作品集レベルの Agent 提出基準
研究アシスタントを Agent の作品集として扱うなら、最終要約だけを見せるのではなく、「目標、ツール、実行、引用、評価、安全境界」の一連の流れを見せるのがおすすめです。
| 提出項目 | 最低要件 | 作品集レベルの要件 |
|---|---|---|
| 目標定義 | 研究テーマを入力できる | 適用範囲、資料ソース、未対応タスクを明確にする |
| ツール一覧 | 少なくとも検索または読取ツールがある | ツールの用途、パラメータ、戻り値、権限境界を明記する |
| 実行 trace | 検索と要約の過程を表示する | 各 step の action、arguments、observation、next_decision を保存する |
| 引用チェック | 各要約に出典が付く | 重要な claim ごとに具体的な根拠箇所まで戻れる |
| 失敗時の回復 | ツール失敗時にエラーを返す | 空結果、タイムアウト、引用不一致、要約の抜けを区別する |
| 評価記録 | 少数のテスト問題を用意する | 固定評価集、baseline、失敗サンプル、改善記録がある |
| 安全境界 | 高リスク操作を自動実行しない | 読み取り専用ツール、人間の確認、最大 step 数、コスト制限を明示する |
この表があると、プロジェクトは「資料を要約できる」段階から、「信頼できる・追跡できる・振り返れる Agent システム」へとレベルアップします。
おすすめの README 構成
研究アシスタントの README は、次の順番で書くとわかりやすいです。
# Research Assistant Agent
## 1. プロジェクト目標
どんな研究シーンを解決するのか、何を解決しないのかを説明する。
## 2. システムフロー
query -> retrieval -> reading -> summary -> citation -> evaluation を示す。
## 3. ツール一覧
search_docs、read_source、summarize、check_citation などのツールを列挙する。
## 4. 実行方法
依存関係のインストール、データ準備、実行例、評価コマンドを示す。
## 5. 実行 trace の例
最終回答だけでなく、完全な実行過程を見せる。
## 6. 評価結果
検索ヒット率、引用正確性、失敗サンプル、改善記録を示す。
## 7. 安全性と制約
資料ソースの制限、引用リスク、最大 step 数、人間確認の境界を説明する。
README は、ソースコードを読まなくても「何をしているシステムか」「どう検証したか」「どこがまだ不完全か」がわかるようにするのが理想です。
最小の Agent Trace 例
goal: RAG と長いコンテキストモデルの違いを要約する
step 1: action=retrieve, arguments={query: "rag long context retrieval"}
observation: d1, d2 にヒット
step 2: action=read_sources, arguments={source_ids: ["d1", "d2"]}
observation: grounding、precision、ranking に関する内容を読み取る
step 3: action=summarize_with_citations
observation: 各 source_id 付きで 3 件の要約を生成
step 4: action=check_citations
observation: 2 件は通過、1 件は引用根拠が不足
final: 信頼できる 2 件の要約を返し、1 件は人手確認が必要としてマークする
この trace の価値は、最終結果に問題があったとき、どの step で失敗したのかをたどれることです。
最終回答だけを見て原因を推測する必要がなくなります。
失敗サンプル集
研究アシスタントでよくある失敗は、「まったく答えられない」ことではなく、「もっともらしいのに信頼できない」ことです。
少なくとも次の種類は記録しておくとよいです。
| 失敗タイプ | 現象 | 可能な原因 | 改善の方向 |
|---|---|---|---|
| 検索の取りこぼし | 重要資料が候補に入らない | query が狭すぎる、キーワード不一致、top-k が小さすぎる | query rewrite、ハイブリッド検索、候補拡大後の rerank |
| 読解不足 | ヒットした文書は正しいが、重要段落を落とす | chunk が小さすぎる、context packing が不適切 | parent-child retrieval、コンテキストの組み立て調整 |
| 要約の過度な一般化 | 要約はそれっぽいが、制約条件が消える | prompt で条件保持を要求していない | claim、condition、source の3点セットで出力させる |
| 引用不一致 | claim と source が一致しない | モデルの自由生成、引用のつなぎ方のミス | citation check、claim ごとの検証 |
| ループ呼び出し | Agent が検索を止められない | 停止条件がない | 最大 step 数、追加情報がない場合は停止 |
こうした失敗サンプルをプロジェクトに入れると、成功例だけを見せるよりもずっと工程力が伝わります。
まとめ
この節でいちばん大事なのは、作品レベルの判断基準を持つことです。
研究アシスタントプロジェクトの本当の強みは、「要約できること」ではなく、「検索、要約、引用を組み立てて、信頼できて追跡できて検証できる出力にすること」です。
この点を押さえられれば、このプロジェクトは成熟した Agent の作品として見えるようになります。
バージョン設計のおすすめ
| バージョン | 目標 | 提出の重点 |
|---|---|---|
| 基礎版 | 最小閉ループを動かす | 入力できる、処理できる、出力できる、そしてサンプルを残せる |
| 標準版 | 見せられるプロジェクトにする | 設定、ログ、エラー処理、README、スクリーンショットを追加する |
| 挑戦版 | 作品集の質に近づける | 評価、比較実験、失敗サンプル分析、次の改善案を追加する |
まずは基礎版を完成させることをおすすめします。最初から大きく作りすぎないことが大切です。
どのバージョンでも、新しく追加した機能、どう検証したか、まだ残っている問題は何かを README に書きましょう。
練習問題
- サンプルに文書を1つ追加して、ある query で「関連文書の競合」が起きるようにしてみよう。
- 考えてみよう:研究アシスタントでは、なぜ「引用の正確性」が普通の Q&A より重要なのか?
- ある要約が見た目は良くても、出典が一致していなければ成功といえるでしょうか? なぜ?
- このプロジェクトを作品集にするなら、トップページで最も見せるべき4つのブロックは何でしょうか?