9.10.3 プロジェクト:データ分析 Agent
データ分析 Agent の本当の価値は、次のように「平均値を計算すること」だけではありません。
- 平均値を計算してくれる
ではなく、
「データを読む -> 分析する -> 結論を説明する」を、検証できる一連の流れにできるかどうか。
そのため、この種のプロジェクトは、複数ステップのツール協調や中間状態を見せるのにとても向いています。
学習目標
- データ分析 Agent の最小プロジェクト範囲を定義できるようになる
- データ入力、統計計算、説明出力を一連の流れにつなげられるようになる
- 最小サンプルで「検証可能性」を示せるようになる
- この題材を1ページの強いポートフォリオプロジェクトとして見せられるようになる
まずは地図を作る
データ分析 Agent は、「データを読む -> 統計を計算する -> 解釈を作る -> 表示方法を提案する」という流れで理解するとよいです。
この節で本当に解決したいのは、次の点です。
- データ分析 Agent はなぜ「pandas を呼び出せる」だけではないのか
- なぜ、最終的なひとことの結論よりも、検証できる中間過程のほうが大事なのか
プロジェクトの題材をどう絞るか?
まずは、次のような形にするのがおすすめです。
- 小さな表を読み込む
- いくつかの主要な統計量を計算する
- 統計量にもとづいて洞察の要約を作る
最初から次のような大きなものにしないほうがよいです。
- 自動 BI プラットフォーム
- 完全自動のレポート工場
初心者向けの、よりわかりやすいたとえ
データ分析 Agent は、次のような分析アシスタントだと考えるとよいです。
- 先に計算し、それから説明し、さらにどう図にするかも提案してくれる
普通の電卓との違いは、次の点ではありません。
- 計算が速いこと
違いはむしろ、
- 数字を、意味のある結論として整理できること
です。
まずは最小のデータ分析ループを動かす
この例では、次のことを行います。
- 小さな売上表を読み込む
- 総売上とカテゴリごとの平均を計算する
- 簡単な分析結論を1つ出す
sales = [
{"category": "course", "amount": 299},
{"category": "course", "amount": 199},
{"category": "book", "amount": 59},
{"category": "book", "amount": 79},
{"category": "service", "amount": 499},
]
def summarize_sales(rows):
total = sum(row["amount"] for row in rows)
grouped = {}
for row in rows:
grouped.setdefault(row["category"], []).append(row["amount"])
per_category_avg = {
category: round(sum(values) / len(values), 2)
for category, values in grouped.items()
}
top_category = max(per_category_avg, key=per_category_avg.get)
return {
"total_amount": total,
"per_category_avg": per_category_avg,
"insight": f"{top_category} の客単価が最も高い。",
}
result = summarize_sales(sales)
print(result)
実行結果の例:
{'total_amount': 1135, 'per_category_avg': {'course': 249.0, 'book': 69.0, 'service': 499.0}, 'insight': 'service の客単価が最も高い。'}

print された辞書を証拠の流れとして読む。元データからカテゴリ平均を作り、最大平均が insight になり、同じフィールドからグラフ提案を決める。
この例がすでにプロジェクトらしい理由
これは「計算」だけをしているのではなく、
次のことも含んでいるからです。
- 入力データ
- 中間統計
- 結論の出力
これで、最小のデータ分析ワークフローになっています。
なぜ insight が特に重要なのか?
ユーザーは、たいてい生の数字を見たいのではなく、
次のようなものを求めています。
- 意味のある結論
ここが、データ分析 Agent と普通の電卓の違いです。
初心者が最初に覚えやすいプロジェクト確認表
| 項目 | 最初に確認すべきこと |
|---|---|
| 入力データ | フィールドの意味がはっきりしているか |
| 中間統計 | 計算の基準が一貫しているか |
| insight | 結論と数字が一致しているか |
| グラフ提案 | グラフの種類がデータの形に合っているか |
この表は初心者にとても向いています。
なぜなら、「データ分析 Agent」を、確認可能なワークフローとして見直せるからです。
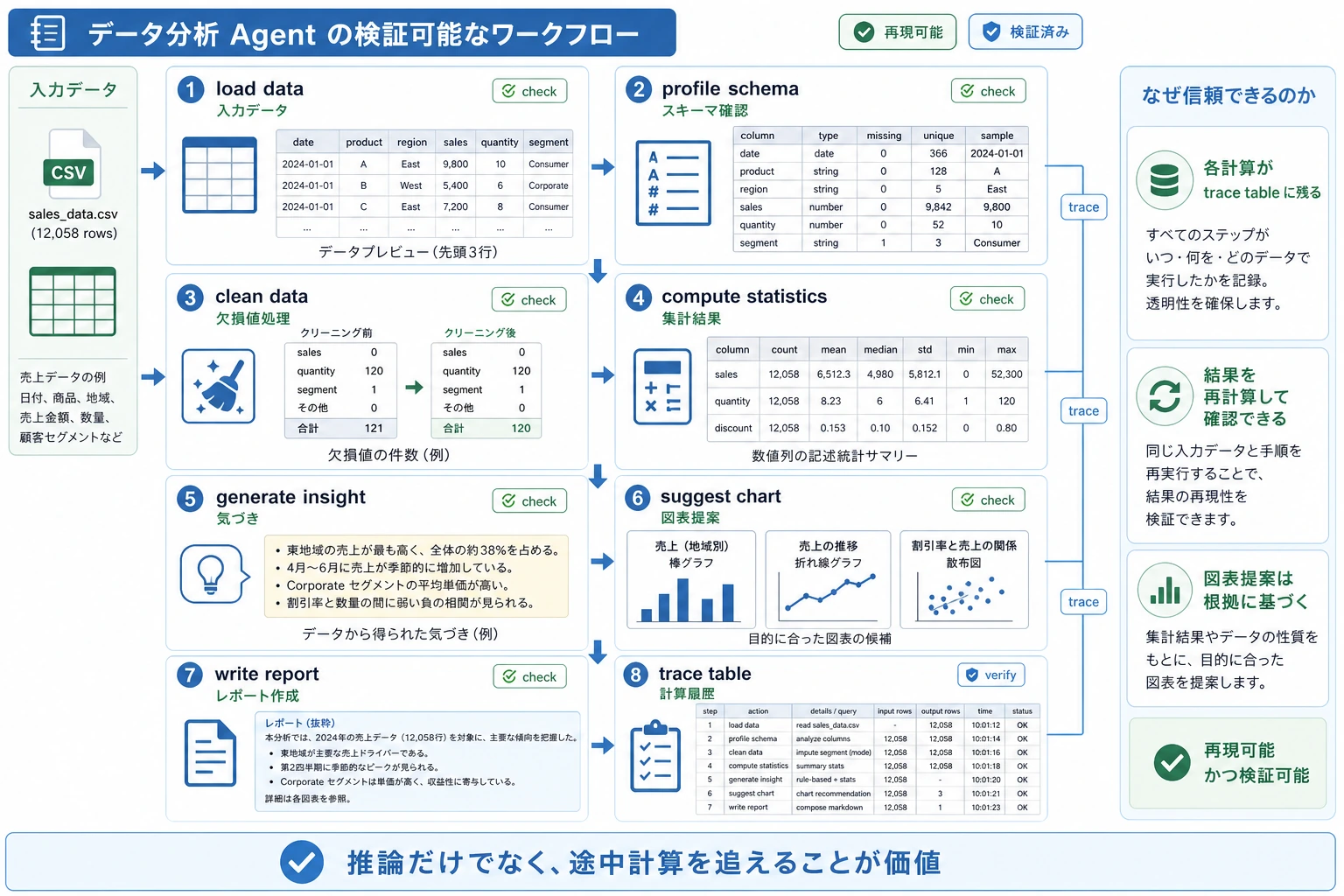
この図は notebook の考え方で読みます。load data、profile schema、compute statistics、generate insight、suggest chart、write report の順です。各結論は、中間計算結果に戻って確認できる必要があります。
作品レベルのデータ分析 Agent が見せるべきものは何か?
入力データはどんな形か
次の点をはっきりさせるのがよいです。
- フィールド
- サンプル数
- 欠損値の有無
中間計算結果
たとえば、次のようなものです。
- 集計統計
- グループ化の結果
- 傾向の判断
最終的な説明
たとえば、次のようなものです。
- どのカテゴリの商品が最も良いか
- どの期間の変動が最も大きいか
グラフ提案
実際にグラフを生成しなくても、次のように出力できます。
- 棒グラフにするべきか、折れ線グラフにするべきか
これで、プロジェクトは実際の分析アシスタントにより近づきます。
最小の「グラフ提案器」を追加する
def suggest_chart(columns):
if "date" in columns and "amount" in columns:
return "line_chart"
if "category" in columns and "amount" in columns:
return "bar_chart"
return "table"
print(suggest_chart(["category", "amount"]))
print(suggest_chart(["date", "amount"]))
実行結果の例:
bar_chart
line_chart
この小さなモジュールにはどんな価値があるか?
これは、このプロジェクトが単なる「計算」ではなく、
次の方向へ少しずつ進んでいることを示します。
- 分析
- 説明
- 可視化の提案
もう1つの最小「分析 trace」の例
同じファイルまたは同じ Python セッションで続けて実行してください。このブロックは sales と result を再利用します。
trace = {
"input_rows": len(sales),
"total_amount": result["total_amount"],
"per_category_avg": result["per_category_avg"],
"insight": result["insight"],
}
print(trace)
実行結果の例:
{'input_rows': 5, 'total_amount': 1135, 'per_category_avg': {'course': 249.0, 'book': 69.0, 'service': 499.0}, 'insight': 'service の客単価が最も高い。'}
この例は初心者にとても向いています。
なぜなら、次のことが見えやすくなるからです。
- データ分析 Agent プロジェクトの本当に価値のある部分
- 「過程を検証できるかどうか」が重要であること
いちばん起こりやすい落とし穴
フィールドの意味を間違える
これは、データ分析 Agent でよくある致命的な問題です。
フィールドの意味を取り違えると、その後の流れ全体がずれてしまいます。
結論だけを見せて、中間過程を見せない
これだと、プロジェクトがブラックボックスのように見えてしまい、信頼を得にくくなります。
happy path だけを作る
次のようなケースを見せないと、プロジェクトがあまり現実的に見えません。
- 欠損値
- 異常値
- 統計の基準の衝突
作品レベルのページに仕上げるには?
おすすめの構成
- 元データのサンプル
- 中間統計表
- 洞察の要約
- グラフ提案
- エラーケース
ぜひ追加したい見せ場
次の3つを、
- 元データ
- 中間計算
- 最終結論
1本の trace として見せるとよいです。
これは、結果だけを貼るよりずっと強い見せ方です。
初心者が最初に覚えやすい評価表
| 観点 | 最初に聞くべきこと |
|---|---|
| 正確性 | 数字は正しく計算できているか |
| 検証可能性 | 中間過程を見返せるか |
| 説明性 | 結論と統計が一致しているか |
| 見せ方 | グラフ提案と結論が自然につながっているか |
この表は初心者にとても向いています。
「Agent プロジェクトが良いかどうか」を、より具体的な項目に分けて判断できるからです。
まとめ
この節で最も大事なのは、作品レベルの判断軸を作ることです。
データ分析 Agent の本当の見どころは、pandas を呼び出せるかどうかではなく、入力データ、中間計算、最終的な洞察を、検証可能な分析ループとしてまとめられるかどうかです。
このループがはっきりしていれば、このプロジェクトは複数ツールを使う Agent の理解を示すのにとても向いています。
これをポートフォリオにするなら、何を見せるのが一番よいか
一番見せるべきなのは、たいてい次のようなものではありません。
- ひとことの分析結論
むしろ、次の 4 つです。
- 元データのサンプル
- 中間統計の結果
- insight がどう生まれたか
- なぜそのグラフを提案したのか
そうすると、見る人は次のことを理解しやすくなります。
- あなたが理解しているのは分析ループであること
- 単に Agent に文章を言わせただけではないこと
バージョン別の進め方のおすすめ
| バージョン | 目標 | 重点となる成果物 |
|---|---|---|
| ベーシック版 | 最小ループを動かす | 入力できる、処理できる、出力できる、さらにサンプルを1組残す |
| スタンダード版 | 見せられるプロジェクトにする | 設定、ログ、エラー処理、README、スクリーンショットを追加する |
| チャレンジ版 | ポートフォリオ品質に近づける | 評価、比較実験、失敗サンプル分析、次のロードマップを追加する |
まずはベーシック版を完成させることをおすすめします。最初から大きく作りすぎないようにしましょう。
1つバージョンを上げるたびに、「何が増えたのか、どう検証したのか、まだ何が課題か」を README に書きましょう。
練習
- サンプルデータに
dateフィールドを追加して、簡単な時系列分析に広げてみましょう。 - 「検証可能性」がデータ分析 Agent にとって特に重要なのはなぜか、考えてみましょう。
- 結論と数字が一致しないとき、このプロジェクトで最も問題が起きやすい層はどこでしょうか?
- ポートフォリオとして見せるなら、どの部分をいちばん目立つように設計しますか?