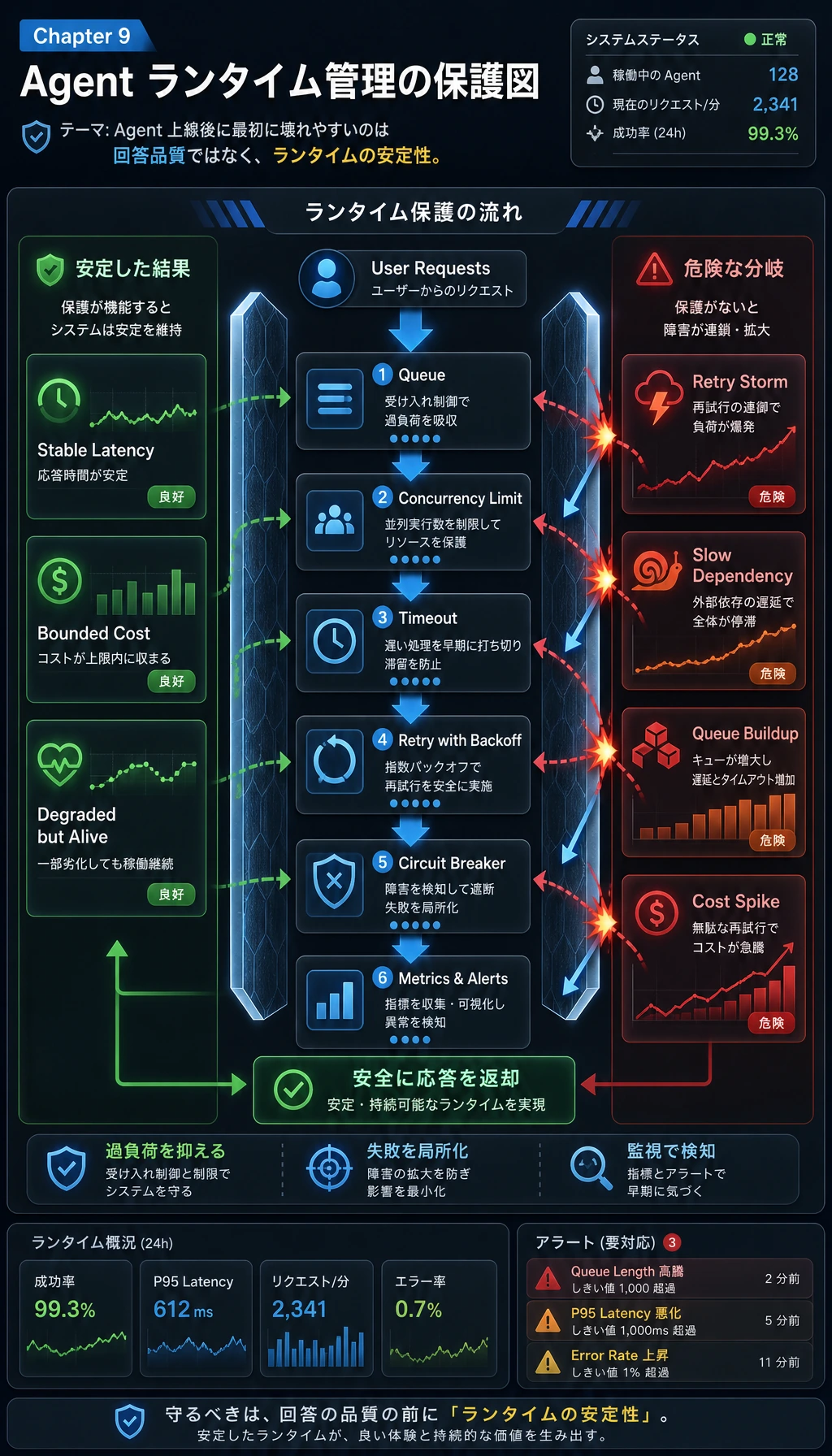
9.9.3 ランタイム管理
ローカルの demo は、「1回動けば成功」と考えてよいことが多いです。
でも、本番システムの要求はまったく違います。
- ピーク時でも動く
- 依存先が不安定でも安定する
- レイテンシとコストを抑えられる
これがランタイム管理で解決する問題です。
学習目標
- 並行、タイムアウト、リトライ、サーキットブレーカーがそれぞれ何を防ぐのかを理解する
- 最小構成のランタイムマネージャーを作れるようになる
- なぜ実行時の指標がモデル指標と同じくらい重要なのかを理解する
- 「1回の成功より、システムの安定性を優先する」というエンジニアリング意識を身につける
なぜ Agent はランタイム問題に特に遭遇しやすいのか?
1回のリクエストは、たいてい1回の呼び出しではない
Agent の一般的な流れには、次のようなものがあります。
- モデル推論
- ツール呼び出し
- 検索
- 再推論
つまり、1つのユーザーリクエストの中に、複数のサブ呼び出しが含まれることがあります。
流れが長くなるほど、ランタイムの揺れは増幅されやすくなります。
本番で最初に表面化するのは、たいてい「答えが間違う」ことではなく「安定して動かない」こと
典型的な症状は次のとおりです。
- 高並列時にタイムアウトが増える
- 上流が一時的に失敗したあとにリトライ嵐が起きる
- リクエストの待ち行列が長くなりすぎる
- 一部の遅いリクエストが全体のスループットを落とす
つまり、ランタイム管理は本質的にシステムの可用性を守るためのものです。
最も重要な4つのランタイム機構
並行制御
同時に実行するタスク数を制限し、リソースが一気に使い切られるのを防ぎます。
タイムアウト
各ステップに上限時間を設け、リクエストが無限にぶら下がるのを防ぎます。
リトライ
一時的なエラーだけに対して限定的にリトライし、すべてのエラーをやり直すことはしません。
サーキットブレーカー
ある依存先が連続して失敗したら、しばらくその呼び出しを止めて、障害の拡大を防ぎます。
まずは最小のランタイムマネージャーを動かしてみる
import asyncio
class AgentRuntime:
def __init__(self, max_concurrency=2, timeout_sec=0.8, max_retries=1, breaker_threshold=2):
self.semaphore = asyncio.Semaphore(max_concurrency)
self.timeout_sec = timeout_sec
self.max_retries = max_retries
self.breaker_threshold = breaker_threshold
self.breaker_open = False
self.failure_streak = 0
self.metrics = {
"total": 0,
"success": 0,
"timeout": 0,
"error": 0,
"retry": 0,
"rejected_by_breaker": 0,
"latency_ms_total": 0.0,
}
async def _upstream_call(self, task):
await asyncio.sleep(task["latency"])
if task.get("should_fail"):
raise RuntimeError("upstream_error")
return {"task_id": task["id"], "result": f"ok:{task['payload']}"}
async def handle(self, task):
self.metrics["total"] += 1
if self.breaker_open:
self.metrics["rejected_by_breaker"] += 1
return {"ok": False, "error": "circuit_open"}
last_error = None
for attempt in range(self.max_retries + 1):
if attempt > 0:
self.metrics["retry"] += 1
try:
async with self.semaphore:
result = await asyncio.wait_for(
self._upstream_call(task),
timeout=self.timeout_sec,
)
latency_ms = task["latency"] * 1000
self.metrics["success"] += 1
self.metrics["latency_ms_total"] += latency_ms
self.failure_streak = 0
return {"ok": True, "result": result, "attempts": attempt + 1}
except asyncio.TimeoutError:
last_error = "timeout"
if attempt == self.max_retries:
self.metrics["timeout"] += 1
self.failure_streak += 1
break
except Exception as e:
last_error = str(e)
if attempt == self.max_retries:
self.metrics["error"] += 1
self.failure_streak += 1
break
if self.failure_streak >= self.breaker_threshold:
self.breaker_open = True
return {"ok": False, "error": last_error}
def summary(self):
avg_latency = (
self.metrics["latency_ms_total"] / self.metrics["success"]
if self.metrics["success"] else 0.0
)
return {**self.metrics, "avg_latency_ms": round(avg_latency, 2)}
async def main():
runtime = AgentRuntime(max_concurrency=2, timeout_sec=0.7, max_retries=1, breaker_threshold=2)
tasks = [
{"id": "r1", "payload": "refund", "latency": 0.2},
{"id": "r2", "payload": "slow", "latency": 1.0},
{"id": "r3", "payload": "fail", "latency": 0.1, "should_fail": True},
{"id": "r4", "payload": "normal", "latency": 0.3},
{"id": "r5", "payload": "after_breaker", "latency": 0.1},
]
results = []
for task in tasks:
results.append(await runtime.handle(task))
print("results:")
for item in results:
print(item)
print("\nmetrics:")
print(runtime.summary())
print("breaker_open:", runtime.breaker_open)
asyncio.run(main())
実行結果の例:
results:
{'ok': True, 'result': {'task_id': 'r1', 'result': 'ok:refund'}, 'attempts': 1}
{'ok': False, 'error': 'timeout'}
{'ok': False, 'error': 'upstream_error'}
{'ok': False, 'error': 'circuit_open'}
{'ok': False, 'error': 'circuit_open'}
metrics:
{'total': 5, 'success': 1, 'timeout': 1, 'error': 1, 'retry': 2, 'rejected_by_breaker': 2, 'latency_ms_total': 200.0, 'avg_latency_ms': 200.0}
breaker_open: True
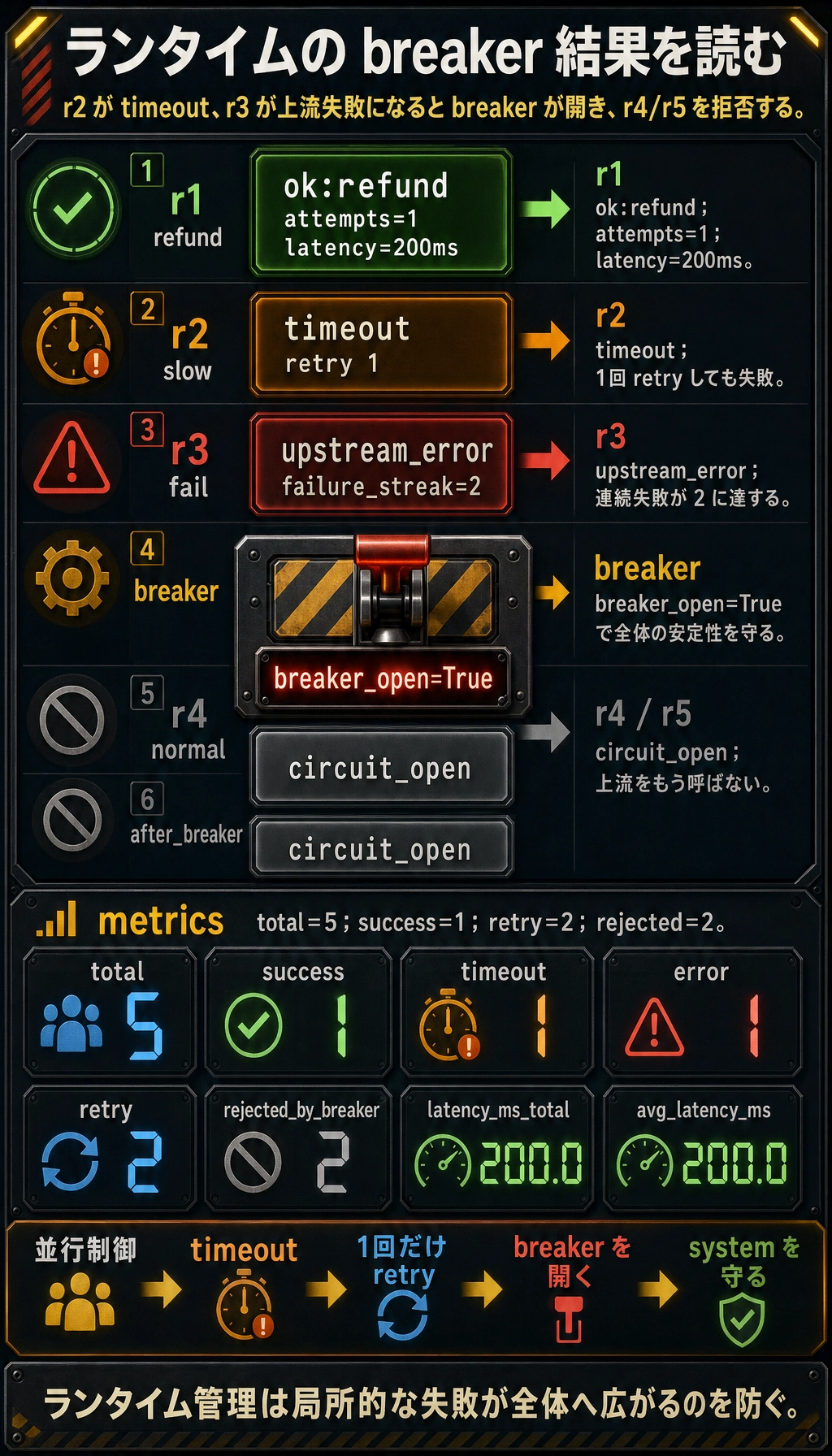
r1 から r5 まで順に読みます。最初の request は成功し、次の2つの失敗が1回分の retry を使って breaker を開き、最後の2つの request はシステム全体を守るために意図的に拒否されます。
このコードで特に見るべき箇所はどこか?
Semaphore:並行制御wait_for:タイムアウトattempt > 0:リトライ回数のカウントbreaker_open:サーキットブレーカー
なぜこれだけでもかなり実運用に近いのか?
次の3種類の本番でよくある状況をカバーしているからです。
- 正常に成功する
- 遅いリクエストがタイムアウトする
- 連続失敗で保護機構が働く
ランタイム指標はどう読むべきか?
まず見るべきなのは次の項目です。
success / total:成功率timeout / total:タイムアウト率retry / total:リトライ比率rejected_by_breaker:サーキットブレーカーによる拒否数avg_latency_ms:平均成功レイテンシ
タイムアウト率が高いなら、まず次を確認します。
- 上流が遅くなっていないか
- タイムアウト閾値が小さすぎないか
- 並行数が高すぎて待ち行列が発生していないか
リトライ比率が高いなら、まず次を確認します。
- 復旧不能なエラーまでリトライしていないか
- 上流が不安定になっていないか
ランタイム最適化でよくある方向性
レート制限とバックプレッシャー
システムがほぼ満杯になったときは、次のような対応を自動で行います。
- 優先度の低いリクエストを拒否する
- あるいは、待ち行列の上限を設ける
フォールバック
例えば次のようなものです。
- 高コストなツールチェーンを止める
- キャッシュ結果に切り替える
- より軽量な安全応答を返す
依存先ごとに個別のポリシーを設定する
異なるツールに、まったく同じ次の設定を使うべきではありません。
- タイムアウト
- リトライ
- サーキットブレーカーの閾値
なぜなら、安定性もコストも違うからです。
よくある誤解
誤解1:並行数は多いほどよい
並行数が多すぎると、システムと上流の両方を一気に圧迫してしまうことがあります。
誤解2:リトライは必ず成功率を上げる
エラーの種類を正しく分けていないと、リトライは障害を大きくするだけです。
誤解3:平均レイテンシだけを見ればよい
実際の体験をよりよく表すのは、高分位レイテンシやタイムアウト率であることが多いです。
まとめ
この節で最も大事なのは、次のような本番運用の視点を持つことです。
Agent のランタイム管理の核心は、各リクエストを「できるだけ成功するまで試す」ことではなく、並行、タイムアウト、リトライ、サーキットブレーカーでシステム全体の安定性を守ることです。
この層を整えてはじめて、システムは本当に本番投入できる土台を持ったと言えます。
練習
- 例の
max_concurrencyを1と3に変えて、結果の違いを比べてみましょう。 timeout_secを大きくして、タイムアウト率がどう変わるか観察しましょう。- 「リトライ回数」は、なぜ「エラーの種類」と切り離して設計できないのでしょうか?
- あるツールがとても高コストだとしたら、ランタイム層でどんな保護を入れますか?