9.9.5 コスト最適化
Agent システムのコストは、単に「1回呼び出すといくらか」だけではありません。
実際に請求額へ大きく影響するのは、たいてい処理全体です。
- 複数回のモデル呼び出し
- ツール呼び出し
- 検索
- リトライ
- 長いコンテキスト
そのため、コスト最適化で大事なのは、モデル単価だけを見ることではなく、
タスク全体の流れの中で、どこにお金がかかっているのかを見極めることです。
学習目標
- Agent コストの主な内訳を理解する
- 最小例を使って、1つのタスク処理経路のコストを見積もる方法を学ぶ
- キャッシュ、ルーティング、切り詰め、リトライ制御がなぜ大きな節約につながるのかを理解する
- 「コスト最適化は単発の工夫ではなく、全体戦略である」という意識を身につける
Agent のお金は普通どこにかかるのか?
モデルの token コスト
もっとも直接的な層は次の2つです。
- 入力 token
- 出力 token
コンテキストが長くなるほど、また手順が増えるほど、コストは高くなります。
ツールと外部依存のコスト
たとえば:
- 検索 API
- ベクトル検索
- 第三者 API
- コード実行環境
これらは token 課金ではないこともありますが、どれも実際のコストです。
リトライと失敗のコスト
失敗は「結果が出なかった」だけではありません。
同時に次のことも意味します。
- すでに1回分の呼び出し料金が発生している
- さらにリトライが走って、追加で料金がかかることがある
そのため、実行時の制御とコスト最適化は、最初から強く結びついています。
なぜ Agent は普通のチャットより「請求額が見えにくい」のか?
1回のユーザーリクエストの裏で、内部呼び出しがたくさん分かれることがあるから
たとえば、ユーザーが次のように1文だけ質問したとします。
- 「この注文は返金できますか?」
システムの内部では、次のような処理が行われるかもしれません。
- ツール選択の推論を1回
- 注文ステータスの照会を1回
- ポリシー検索を1回
- 金額計算を1回
- 最終回答の生成を1回
さらにリトライが入れば、コストはもっと増えます。
だから、コスト計算は「単発呼び出し」ではなく「タスク全体」で見るべき
この視点はとても重要です。
- ユーザーからは1回のリクエストに見える
- システム内部では5〜10回のアクションが走っている
コスト最適化は、必ずこの「全体の流れ」に向き合う必要があります。
まずは最小のコスト見積もりツールを動かしてみる
この例では、1つの Agent タスクを次の3つに分けてコストを計算します。
- モデル token コスト
- ツール呼び出しコスト
- リトライによる追加コスト
PRICES = {
"small_model": {"input_per_1k": 0.001, "output_per_1k": 0.002},
"large_model": {"input_per_1k": 0.01, "output_per_1k": 0.03},
}
TOOL_PRICES = {
"search_api": 0.002,
"vector_retrieval": 0.0005,
"sql_query": 0.0002,
}
def llm_cost(model_name, input_tokens, output_tokens):
price = PRICES[model_name]
return (
input_tokens / 1000 * price["input_per_1k"]
+ output_tokens / 1000 * price["output_per_1k"]
)
def task_cost(task):
total = 0.0
for call in task["llm_calls"]:
total += llm_cost(call["model"], call["input_tokens"], call["output_tokens"])
for tool in task["tool_calls"]:
total += TOOL_PRICES[tool]
return round(total, 6)
baseline_task = {
"llm_calls": [
{"model": "large_model", "input_tokens": 1800, "output_tokens": 300},
{"model": "large_model", "input_tokens": 1400, "output_tokens": 220},
],
"tool_calls": ["search_api", "vector_retrieval"],
}
optimized_task = {
"llm_calls": [
{"model": "small_model", "input_tokens": 700, "output_tokens": 120},
{"model": "large_model", "input_tokens": 900, "output_tokens": 180},
],
"tool_calls": ["vector_retrieval"],
}
print("baseline_cost =", task_cost(baseline_task))
print("optimized_cost =", task_cost(optimized_task))
実行結果の例:
baseline_cost = 0.0501
optimized_cost = 0.01584
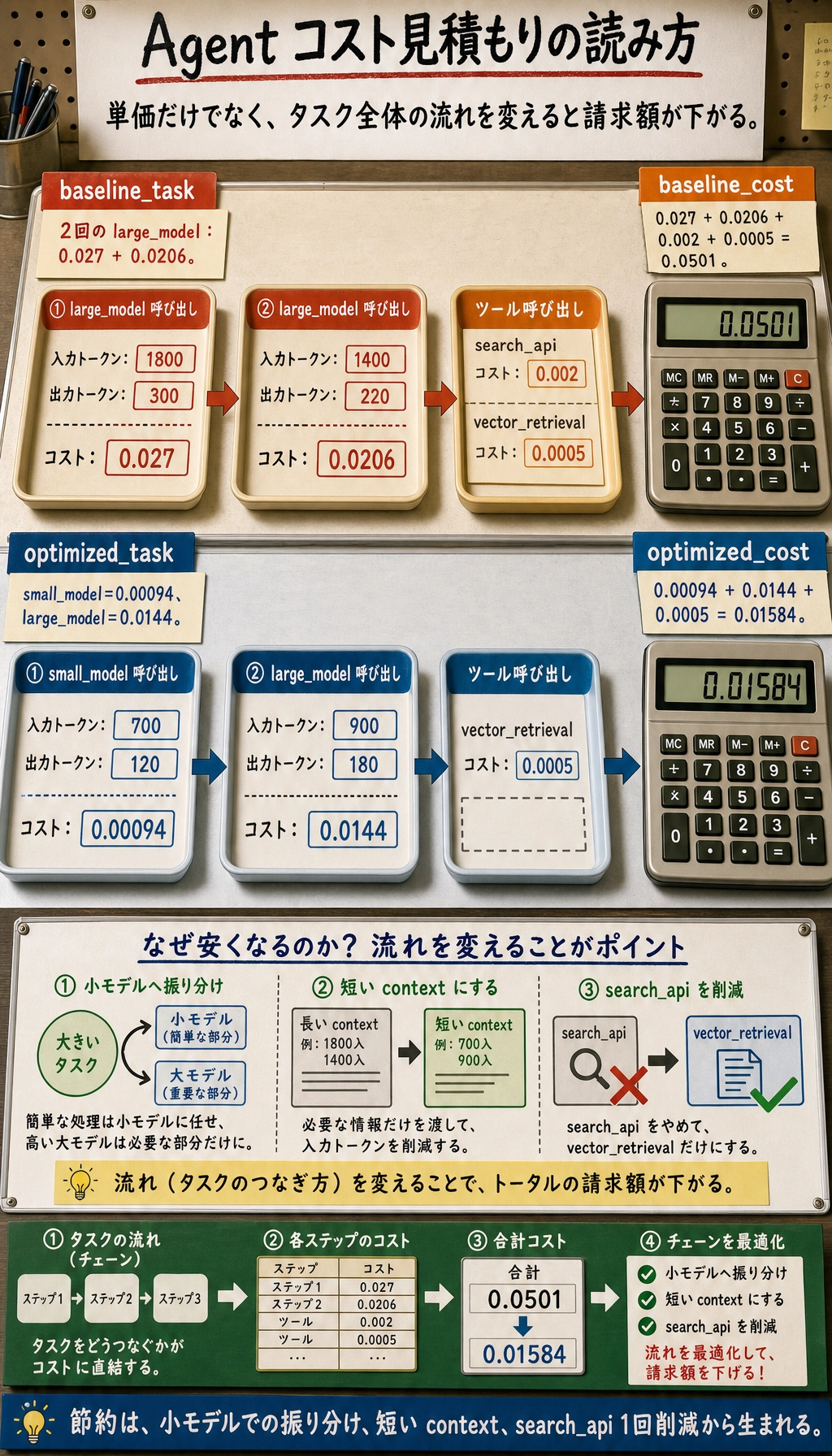
このコードでまず見てほしいポイント
特定の価格そのものではなく、
コストがどのように積み上がるかです。
- どのモデル呼び出しが高いのか
- どのツール呼び出しも積み重なると高くなるのか
- 最適化後に、なぜコストがはっきり下がるのか
なぜ「先に小モデルでふるい分けて、最後に大モデルで精答」するのがよく効くのか?
多くのリクエストは、最初から最も高価なモデルをずっと使う必要がありません。
典型的なやり方は次の通りです。
- 小モデルでルーティング / ふるい分け
- 大モデルは本当に難しい部分だけを担当
なぜ search_api を1回減らすだけでも大きいのか?
外部 API は、単価が低くないことがあります。
それに加えて、遅延やリトライのリスクも増えます。

この図は、コストを「1回のモデル呼び出し」から「タスク全体の請求」に広げて見ています。モデルルーティング、コンテキスト長、ツール呼び出し、キャッシュヒット、失敗時のリトライ、予算上限のすべてが、最終的なコストに影響します。
コスト最適化でよく使う5つの方向
コンテキストを短くする
もっとも直接的な方法は、たいてい次のようなものです。
- 無関係な履歴を削る
- 長いコンテキストを圧縮する
- 先に要約する
モデルを段階的にルーティングする
よくあるパターンは次の通りです。
- 簡単なリクエスト -> 小モデル
- 難しいリクエスト -> 大モデル
キャッシュを使う
特に向いているのは次のようなものです。
- 頻繁に繰り返される質問
- 読み取り専用のツール結果
- 固定されたポリシー系の内容
ツール呼び出しの重複をなくす
多くの Agent では、実際には「呼ぶべきツール」にお金がかかっているのではなく、
次のようなことにお金がかかっています。
- 同じ内容を何度も確認すること
失敗とリトライを制御する
失敗やリトライが多すぎると、
請求額はすぐに想定より大きくなります。
キャッシュでどれだけ節約できるかの実用例
cache = {}
def cached_lookup(query, raw_cost=0.002):
if query in cache:
return {"source": "cache", "cost": 0.0}
cache[query] = True
return {"source": "api", "cost": raw_cost}
queries = ["返金ポリシー", "返金ポリシー", "証明書ルール", "返金ポリシー"]
total_cost = 0.0
for query in queries:
result = cached_lookup(query)
total_cost += result["cost"]
print(query, "->", result)
print("total_cost =", total_cost)
実行結果の例:
返金ポリシー -> {'source': 'api', 'cost': 0.002}
返金ポリシー -> {'source': 'cache', 'cost': 0.0}
証明書ルール -> {'source': 'api', 'cost': 0.002}
返金ポリシー -> {'source': 'cache', 'cost': 0.0}
total_cost = 0.004

このコードはとてもシンプルですが、実際の開発で大事なことをよく表しています。
- 頻繁に繰り返されるリクエストをキャッシュしないと、ずっとお金を使い続ける
コスト最適化でよくある落とし穴
罠1:より安いモデルに変えれば最適化完了だと思う
もし処理経路の設計が変わらず、ツール呼び出しが相変わらず多く、リトライも暴走したままなら、
モデル単価が下がっても、全体の請求額はあまり下がらないことがあります。
罠2:とにかく最小コストだけを追う
節約のために次のようなことが起きると、それは本当の最適化ではありません。
- 正解率が大きく下がる
- かえって遅くなる
- 難しいリクエストに答えられない
罠3:単発リクエストのコスト分析をしない
次のことが分からないと、
- どの種類のリクエストが一番高いのか
- どの段階でお金がかかっているのか
その後の改善は、ほぼ勘に頼ることになります。
まとめ
この節で最も大事なのは、全体の流れでコストを見ることです。
Agent のコスト最適化は、「モデルを少し安くする」だけではありません。コンテキスト長、モデルルーティング、ツール呼び出し、キャッシュヒット、失敗時のリトライをまとめて最適化することです。
コストを単一のモデル呼び出しではなくタスク全体で分解して見始めると、はじめて本当の改善ができます。
練習
- この例に「リトライによって追加のモデル呼び出しが発生する」コストを加えて、合計金額がどう変わるか見てみましょう。
- どのようなリクエストならキャッシュに向いていて、どのようなリクエストは毎回リアルタイムで計算すべきか考えてみましょう。
- なぜモデルを段階的にルーティングする方が、「常に大モデルを使う」より本番システムに向いているのでしょうか?
- ある処理経路の正解率は高いのに、コストだけが異常に高い場合、まずどの段階を確認しますか?