E.B.2 迭代器与生成器进阶
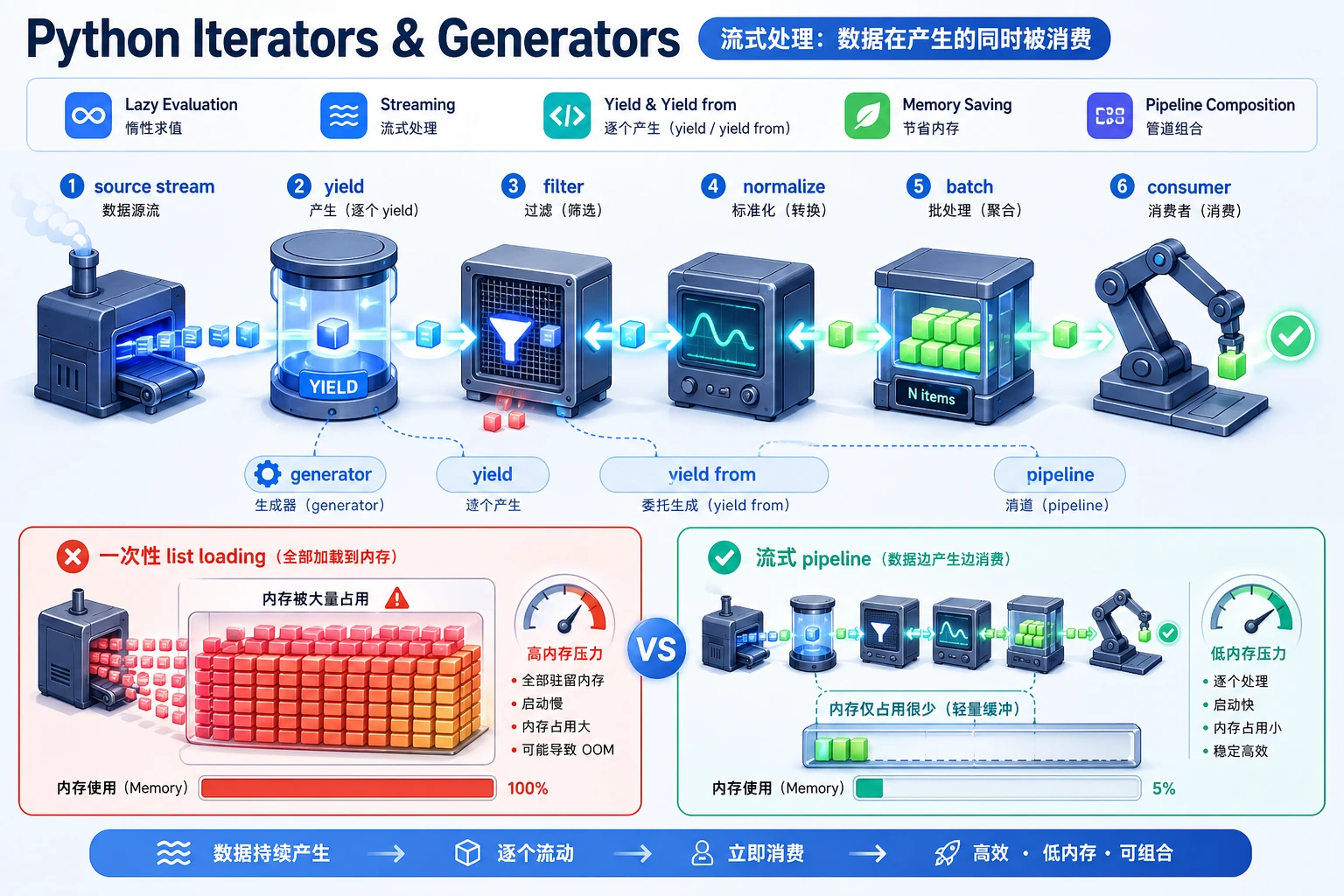
当数据像流一样到来时,生成器很有用:日志、文件、API 分页、样本批次、检索结果或模型输出。它一次只产出一个值,可以避免创建不必要的中间列表。
准备内容
- Python 3.10+
- 不需要第三方包
- 理解
for循环
关键术语
- Iterator(迭代器):能不断产出下一个值的对象。
- Generator(生成器):使用
yield惰性产出值的函数。 - Lazy evaluation(惰性求值):需要下一个值时才计算。
- Pipeline(管线):多个小处理步骤串起来。
yield from:把另一个可迭代对象里的值继续向外产出。
运行流式处理管线
创建 generator_pipeline.py:
def read_events():
events = [
"INFO request ok",
"ERROR db timeout",
"INFO cache hit",
"ERROR auth failed",
"ERROR model busy",
]
for event in events:
yield event
def filter_errors(events):
for event in events:
if event.startswith("ERROR"):
yield event
def normalize(events):
for event in events:
yield event.lower()
def batch(items, size):
group = []
for item in items:
group.append(item)
if len(group) == size:
yield group
group = []
if group:
yield group
pipeline = batch(normalize(filter_errors(read_events())), size=2)
for group in pipeline:
print(group)
运行:
python generator_pipeline.py
预期输出:
['error db timeout', 'error auth failed']
['error model busy']
这条管线完成读取、过滤、标准化和分批,但没有在每一步都生成完整列表。
使用 yield from
运行这个独立小示例:
def flatten(groups):
for group in groups:
yield from group
pipeline = [
["error db timeout", "error auth failed"],
["error model busy"],
]
for item in flatten(pipeline):
print(item)
预期输出:
error db timeout
error auth failed
error model busy
这比嵌套循环更清楚地表达了“把每个分组里的元素继续向外产出”。
什么时候生成器有帮助
适合:
- 输入可能很大。
- 记录是一条一条处理的。
- 想把读取、过滤、转换、分批串起来。
- 不需要随机访问全部元素。
如果数据很小,而且反复访问列表会让代码更简单,就直接用列表。
常见错误
- 以为生成器消费完后还能复用。
- 以为生成器永远更快;它的主要价值常常是省内存和组织流程。
- 很简单的列表转换也强行写成
yield,反而降低可读性。
练习
修改 batch,让它同时打印 batch_id。然后改变输入事件,确认后续步骤不改也能继续工作。