9.2.3 链式推理策略
如果把上一节总结成一句话,就是:
- 推理问题依赖中间状态
那这一节要回答的就是:
我们怎样让模型更愿意、更稳定地把中间状态显式写出来?
链式推理策略,也就是 CoT,最核心的想法就是:
- 不直接要答案
- 先让模型拆步骤,再出结论
学习目标
- 理解链式推理策略为什么会提升多步任务表现
- 理解 CoT 适合什么任务,不适合什么任务
- 通过可运行示例理解“直接答”和“分步答”的差别
- 理解生产环境里怎样使用结构化推理,而不是无节制长文本
为什么“先想步骤”会有帮助?
因为很多问题不是一跳到终点
例如这道题:
- 商品原价 80 元,打 8 折后再减 5 元,最后多少钱?
如果模型直接生成答案, 它可能会犯很典型的错误:
- 把“8 折”当成减 8 元
- 漏掉最后的减 5 元
- 步骤顺序搞错
而如果它先把过程拆开:
80 * 0.8 = 6464 - 5 = 59
最终答案通常会更稳定。
CoT 的核心不是“写很多字”,而是“暴露中间结构”
这一点特别重要。 链式推理真正有用的地方不是:
- 输出更长
而是:
- 把局部事实
- 中间变量
- 步骤依赖
显式写出来。
一个类比:草稿纸不是为了显得认真
学生做题时写草稿纸,不是为了让答案更长, 而是为了:
- 防止脑中状态丢失
- 把复杂问题拆小
- 方便检查
CoT 对模型的作用很像这一层。
先看一个“直接答”和“链式答”的对比
下面这个例子不会调用 LLM, 但它会非常清楚地演示:
- 为什么“直接做一个粗糙映射”容易错
- 为什么“先拆步骤再算”更稳
import re
problem = "商品原价80元,先优惠20%,再减5元,最后多少钱?"
def bad_direct_answer(text):
numbers = list(map(int, re.findall(r"\d+", text)))
original, discount, minus = numbers
# 常见错误:把“优惠 20%”误当成“减 20 元”
return original - discount - minus
def chain_reason_answer(text):
original, discount, minus = map(int, re.findall(r"\d+", text))
steps = []
discounted_price = original * (1 - discount / 100)
steps.append(f"先算折扣价:{original} * (1 - {discount}/100) = {discounted_price}")
final_price = discounted_price - minus
steps.append(f"再减额外的 {minus} 元:{discounted_price} - {minus} = {final_price}")
return final_price, steps
print("problem:", problem)
print("bad direct answer:", bad_direct_answer(problem))
answer, steps = chain_reason_answer(problem)
print("\nchain reasoning steps:")
for step in steps:
print("-", step)
print("final answer:", answer)
预期输出:
problem: 商品原价80元,先优惠20%,再减5元,最后多少钱?
bad direct answer: 55
chain reasoning steps:
- 先算折扣价:80 * (1 - 20/100) = 64.0
- 再减额外的 5 元:64.0 - 5 = 59.0
final answer: 59.0
这段代码最能说明什么?
它说明:
- 直接映射很容易误解题意
- 显式拆步骤后,错误更容易被暴露
例如这里:
- “8 折”到底是
-8还是*0.8
只要你把这一步写出来, 错误就不容易藏起来。
为什么 CoT 常常对数学、逻辑、规划类任务特别有用?
因为这些任务通常都具备:
- 明确中间变量
- 明确步骤顺序
- 明确局部依赖
这和链式推理天然契合。
为什么 CoT 不是所有任务都该开?
因为不是所有问题都需要分步。 例如:
- “法国首都是哪里?”
这种问题更像检索,不需要拉长推理链。
所以 CoT 不是默认越多越好, 而是:
- 在多步问题上更值钱
CoT 在 Agent 里通常怎么用?
先分解,再调用工具
很多 Agent 任务里,CoT 不一定直接用来算数, 而是用来回答:
- 先做什么
- 后做什么
- 哪一步需要工具
例如:
- 识别问题类型
- 决定先查政策还是先查库存
- 拿到观察后再组织结论
也可以变成更结构化的“推理槽位”
在生产环境里,不一定非要让模型输出一大段自然语言思维过程。 很多系统会改成更短、更结构化的格式,例如:
factssubtasksdecisionnext_action
这类结构往往更容易:
- 校验
- 记录
- 调试
CoT 也常和自检结合
一种很常见的增强方式是:
- 先推导
- 再检查关键步骤
- 最后输出答案
这样可以降低部分粗心错误。
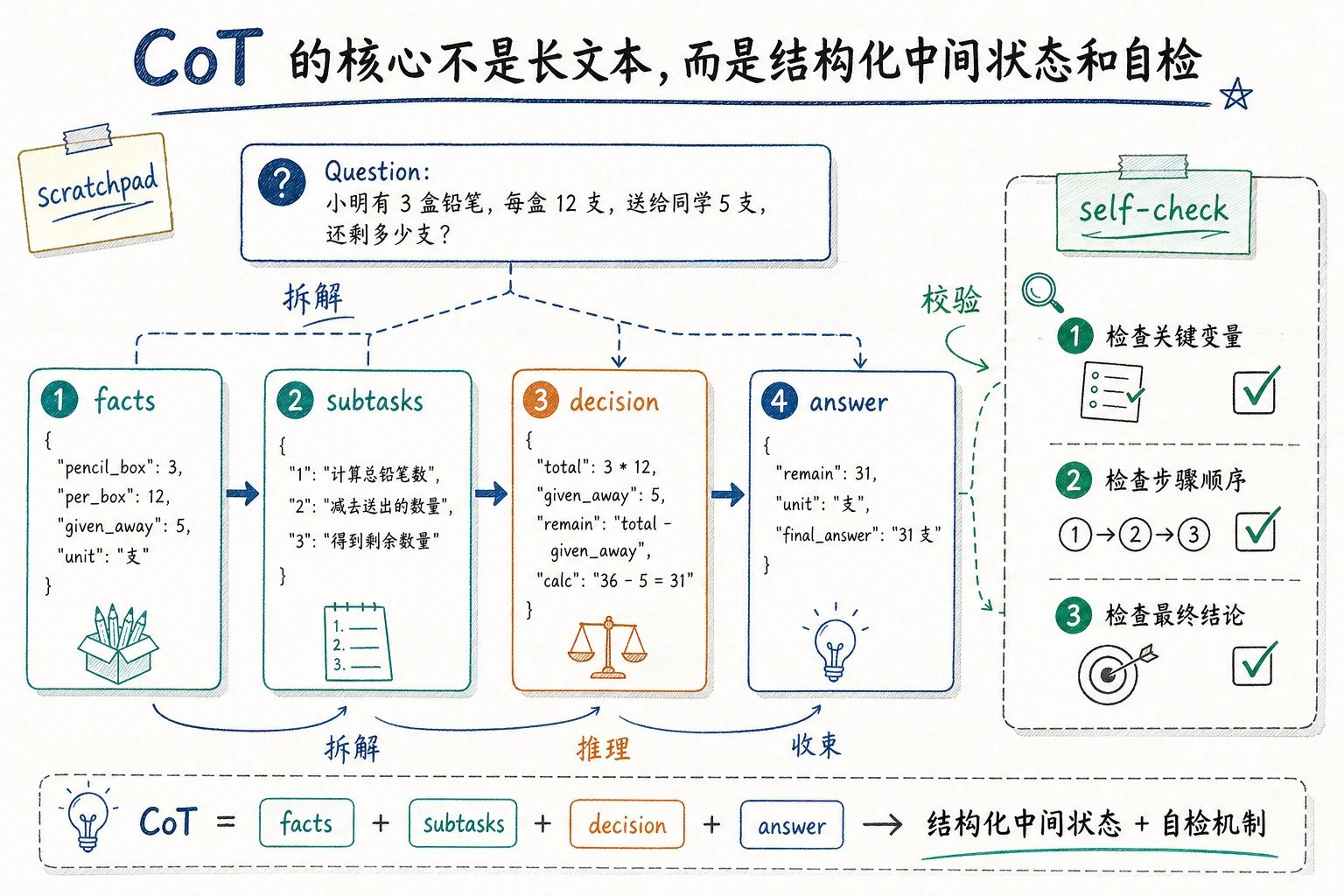
这张图强调的是“结构化中间状态”,不是让模型无限输出长篇思考。生产环境更常把推理压成 facts、subtasks、decision 和 next_action 这类可校验槽位。
什么时候 CoT 最有帮助?
需要拆步骤的问题
例如:
- 多步计算
- 条件筛选
- 组合决策
- 复杂规则判断
需要解释过程的问题
例如:
- 为什么推荐这个方案
- 为什么不能执行这个请求
- 为什么这个回答符合规则
当系统不仅要给结论,还要给理由时, 显式中间过程很有价值。
错误代价较高的问题
如果问题一旦算错或判断错, 后果比较严重, 那显式步骤通常更值得。
什么时候 CoT 反而可能拖后腿?
简单检索题
如果问题本身不需要分步, 硬让模型输出长过程,通常只是:
- 更慢
- 更长
- 更贵
推理链太长,可能自己把自己绕晕
链太长时,模型可能会出现:
- 早期步骤对,后面漂移
- 重复解释
- 中间状态前后不一致
也就是说,CoT 不是无限拉长就更好。
对外展示时可能不适合原样暴露
在很多产品里,更合理的做法是:
- 内部有推理结构
- 对用户只展示精炼解释
因为用户真正需要的往往是:
- 清晰结论
- 必要理由
而不是冗长草稿。
一个更实用的结构化 CoT 写法
下面这个示例展示一种更适合 Agent 的写法:
- 不输出一大段自由文本
- 而是分成固定槽位
ticket = {
"question": "订单未发货,原价80元先优惠20%后又减5元,退款金额是多少?",
"policy": "未发货订单可原路退款。",
}
def structured_reasoning(ticket):
facts = [
"订单未发货,可走原路退款",
"商品原价 80 元,先优惠 20% 后再减 5 元",
]
calculation = ["80 * 0.8 = 64", "64 - 5 = 59"]
decision = "退款金额应为 59 元,且原路退回。"
return {
"facts": facts,
"calculation": calculation,
"decision": decision,
}
result = structured_reasoning(ticket)
print(result)
预期输出:
{'facts': ['订单未发货,可走原路退款', '商品原价 80 元,先优惠 20% 后再减 5 元'], 'calculation': ['80 * 0.8 = 64', '64 - 5 = 59'], 'decision': '退款金额应为 59 元,且原路退回。'}
这种格式的优点是:
- 更容易读
- 更容易测
- 更容易做后处理
常见误区
误区一:CoT 就是让模型啰嗦一点
不是。 核心是:
- 把中间结构显式化
误区二:所有任务都该默认用 CoT
不对。 是否启用,要看问题是否真的多步。
误区三:有了 CoT,答案就一定可靠
也不对。 链式推理会提升稳定性, 但不会自动消灭所有错误。
小结
这节最重要的,不是记住 Chain-of-Thought 这个英文名,
而是建立一个实用判断:
当问题依赖多步中间状态时,让模型先显式拆步骤,往往能提升稳定性;但 CoT 的价值在于结构化中间过程,不在于无限拉长输出。
只要这层理解清楚了, 你后面再看:
- ReAct
- Plan-and-Execute
- 自检与评估
都会更容易明白它们是在 CoT 之上继续做组织化。
练习
- 把示例中的折扣题换成你自己的多步题,比较
bad_direct_answer和chain_reason_answer。 - 为什么说 CoT 的核心价值在“显式中间结构”而不是“输出更长”?
- 想一个不适合 CoT 的简单问题,解释原因。
- 如果你要把 CoT 用在产品里,你会更倾向自由文本还是结构化槽位?为什么?