9.2.6 高级规划策略【选修】
上一节的 Plan-and-Execute 已经把长任务拆成了顺序步骤。 但真实复杂任务往往不是一条直线,而更像一张图:
- 有些步骤必须先做
- 有些步骤可以并行
- 有些步骤失败后要回滚或重规划
所以这节会再往前走一步:
高级规划不是把清单写得更长,而是把任务关系建成图。
学习目标
- 理解为什么复杂任务需要依赖图,而不只是线性步骤
- 理解并行、关键路径、资源限制在规划中的作用
- 通过可运行示例看懂一个最小 DAG 调度器
- 理解高级规划和普通 Plan-and-Execute 的差别
为什么线性计划有时不够?
因为现实任务里很多步骤并不是“先 A 再 B 再 C”
例如做一份调研报告时, 你可能需要:
- 收集产品资料
- 收集用户反馈
- 读取历史数据
这些步骤并不一定要严格串行。 如果硬写成直线, 计划会显得:
- 冗长
- 低效
- 难以表达真实依赖
高级规划最核心的问题
不是“列多少步骤”, 而是:
- 哪些步骤依赖哪些前置条件
- 哪些可以并行
- 哪些是关键路径
也就是说,高级规划的对象更像:
- 任务图
一个类比:施工图而不是办事清单
普通计划像待办清单。 高级规划更像施工图:
- 哪些工序能同时开工
- 哪些工序必须等验收
- 哪些工序拖慢会影响全局
高级规划里最常见的三个概念
依赖关系
如果任务 B 必须等待任务 A 产出结果, 那就有:
A -> B
例如:
- 先抓取数据,再清洗数据
- 先完成统计,再写报告
并行性
如果两个任务互不依赖, 它们理论上可以同时做。
这意味着:
- 总耗时可能缩短
- 但调度会更复杂
关键路径
关键路径指的是:
- 决定总耗时的那条最长依赖链
很多任务不是所有步骤都同样重要。 真正拖慢整体进度的,往往是关键路径上的节点。
先跑一个真正的 DAG 调度示例
下面这段代码会做一件很有代表性的事:
- 给定任务依赖和持续时间
- 在 2 个 worker 限制下做调度
- 输出每个时间点在跑什么
这会帮助你建立高级规划最重要的直觉:
- 计划不只是顺序,还是资源和依赖的组合
tasks = {
"collect_policy_docs": {"deps": [], "duration": 2},
"collect_user_cases": {"deps": [], "duration": 3},
"summarize_policy": {"deps": ["collect_policy_docs"], "duration": 2},
"analyze_cases": {"deps": ["collect_user_cases"], "duration": 2},
"draft_report": {"deps": ["summarize_policy", "analyze_cases"], "duration": 2},
}
def schedule(task_graph, workers=2):
completed = set()
running = []
timeline = []
time = 0
while len(completed) < len(task_graph):
# 先完成这一时刻结束的任务
just_finished = [task for task, end_time in running if end_time == time]
if just_finished:
for task in just_finished:
completed.add(task)
running = [(task, end_time) for task, end_time in running if end_time != time]
# 找出当前可执行任务
available = []
for task, meta in task_graph.items():
if task in completed:
continue
if any(task == running_task for running_task, _ in running):
continue
if all(dep in completed for dep in meta["deps"]):
available.append(task)
# 分配空闲 worker
free_slots = workers - len(running)
for task in available[:free_slots]:
end_time = time + task_graph[task]["duration"]
running.append((task, end_time))
timeline.append(
{
"time": time,
"running": [task for task, _ in running],
"completed": sorted(completed),
}
)
if len(completed) == len(task_graph):
break
time += 1
return timeline
timeline = schedule(tasks, workers=2)
for item in timeline:
print(item)
预期输出:
{'time': 0, 'running': ['collect_policy_docs', 'collect_user_cases'], 'completed': []}
{'time': 1, 'running': ['collect_policy_docs', 'collect_user_cases'], 'completed': []}
{'time': 2, 'running': ['collect_user_cases', 'summarize_policy'], 'completed': ['collect_policy_docs']}
{'time': 3, 'running': ['summarize_policy', 'analyze_cases'], 'completed': ['collect_policy_docs', 'collect_user_cases']}
{'time': 4, 'running': ['analyze_cases'], 'completed': ['collect_policy_docs', 'collect_user_cases', 'summarize_policy']}
{'time': 5, 'running': ['draft_report'], 'completed': ['analyze_cases', 'collect_policy_docs', 'collect_user_cases', 'summarize_policy']}
{'time': 6, 'running': ['draft_report'], 'completed': ['analyze_cases', 'collect_policy_docs', 'collect_user_cases', 'summarize_policy']}
{'time': 7, 'running': [], 'completed': ['analyze_cases', 'collect_policy_docs', 'collect_user_cases', 'draft_report', 'summarize_policy']}
这段代码最该看什么?
重点不是细节语法, 而是这三件事:
- 任务不是线性列表,而是
deps图 - 只有依赖满足的任务才能进入
available - worker 数量会限制并发度
这三件事合在一起, 就是高级规划最核心的现实约束。
为什么 draft_report 一定要最后?
因为它依赖:
summarize_policyanalyze_cases
所以哪怕你有更多 worker, 在前置结果没出来之前,它也不能开始。
这说明高级规划不是“任务越多越能并行”, 而要看依赖图本身。
如果 worker 从 2 改成 1,会发生什么?
你会看到计划明显更长。 这能帮助你理解:
- 规划不只是逻辑问题
- 也是资源问题
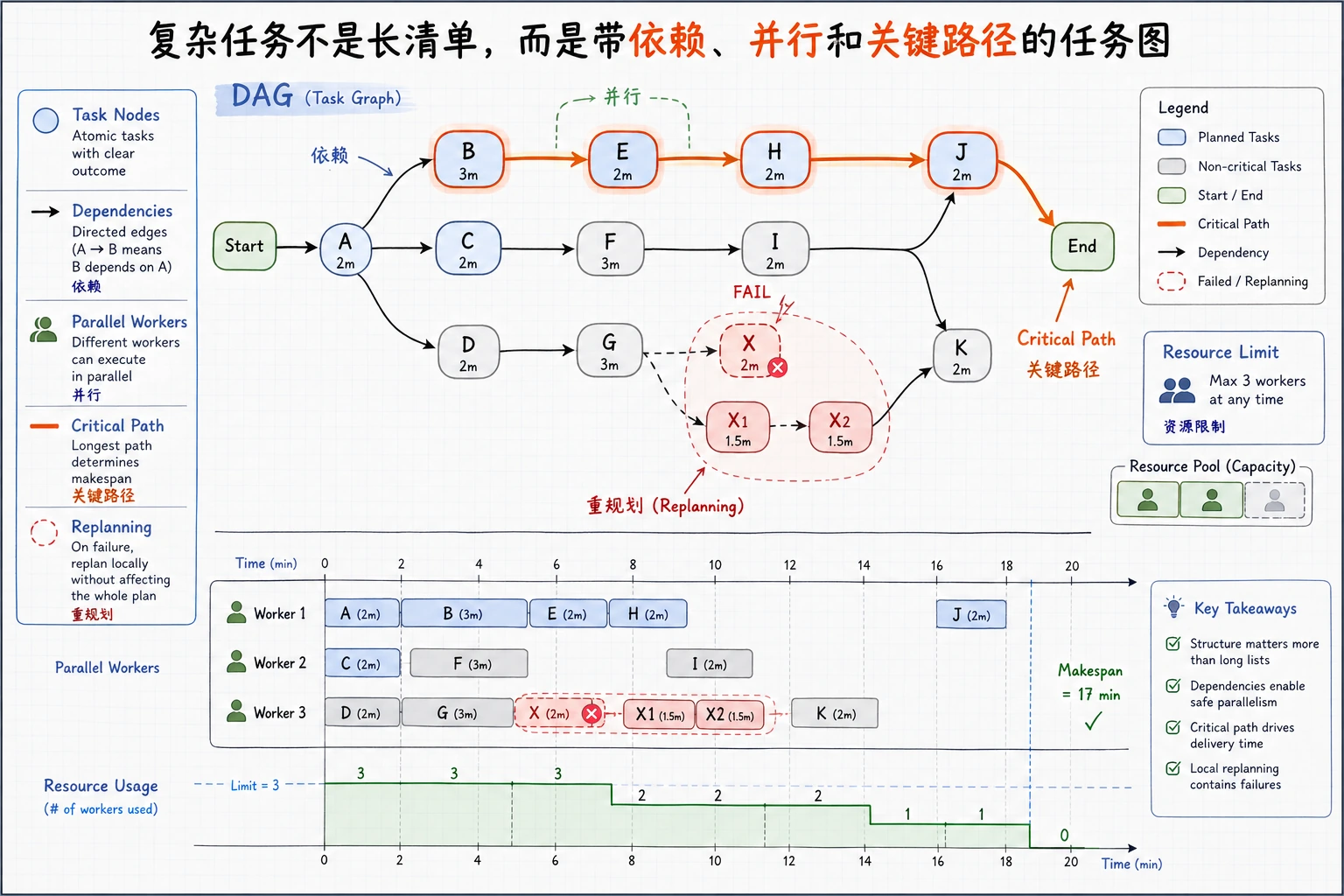
这张图把“任务清单”升级成“任务图”:节点表示步骤,箭头表示依赖,粗线表示关键路径。新人可以先问自己:哪些能并行,哪些必须等前置结果完成?
什么时候需要高级规划,而不是普通计划?
当任务天然是图结构
例如:
- 调研报告
- 多源数据汇总
- 复杂代码改造
- 多步骤业务审批
当并行能明显带来收益
如果任务里有很多独立前置步骤, 高级规划能帮你看清:
- 哪些任务该并行
- 哪些等待是不可避免的
当失败恢复和重规划变得重要
复杂任务里经常会出现:
- 某个节点失败
- 新观察推翻原计划
- 某些前置条件不再成立
这时系统不仅要“有计划”, 还要能:
- 局部重算
- 局部回滚
- 局部重规划
为什么说高级规划更像“图搜索”而不是“列清单”?
因为路径不一定唯一
很多复杂任务并没有唯一解法。 你可能有:
- 多种任务拆法
- 多种资源分配方式
- 多种执行顺序
因为要考虑代价函数
有时你要优化的是:
- 总耗时
- 总成本
- 风险最小
不同目标会选出不同的计划。
因为“最佳计划”会随着环境变化
如果某个工具慢了、某个资源不可用了, 原先最优的图可能就不再最优。
这也是为什么高级规划常常离不开:
- 动态调度
- 在线重规划
工程上最容易踩的坑
误区一:依赖图画出来就万事大吉
图只是开始。 你还得定义:
- 节点输入输出
- 失败处理
- 节点重试策略
误区二:并行越多越好
并行会带来:
- 调度复杂度
- 资源竞争
- 状态同步问题
并不是无限开并发就更优。
误区三:高级规划一定比简单计划更高级
如果任务本身很短、很固定, 上高级规划反而会显得过度设计。
小结
这节最重要的,不是记住 DAG 这个词,
而是建立一个更现实的判断:
当任务涉及依赖、并行和资源限制时,规划的核心就不再是写一个长清单,而是把任务组织成图,并围绕图做调度。
这层理解一旦建立, 你后面再看:
- 多 Agent 协同
- 工作流编排
- 调度器设计
都会更自然。
练习
- 把示例中的 worker 数改成
1和3,比较时间线差异。 - 给任务图再加一个
review_report节点,挂在draft_report后面,观察调度变化。 - 为什么说“能并行”不等于“应该并行到极致”?
- 想一个你熟悉的复杂任务,把它尝试画成一个依赖图。