5.5.5 特征选择
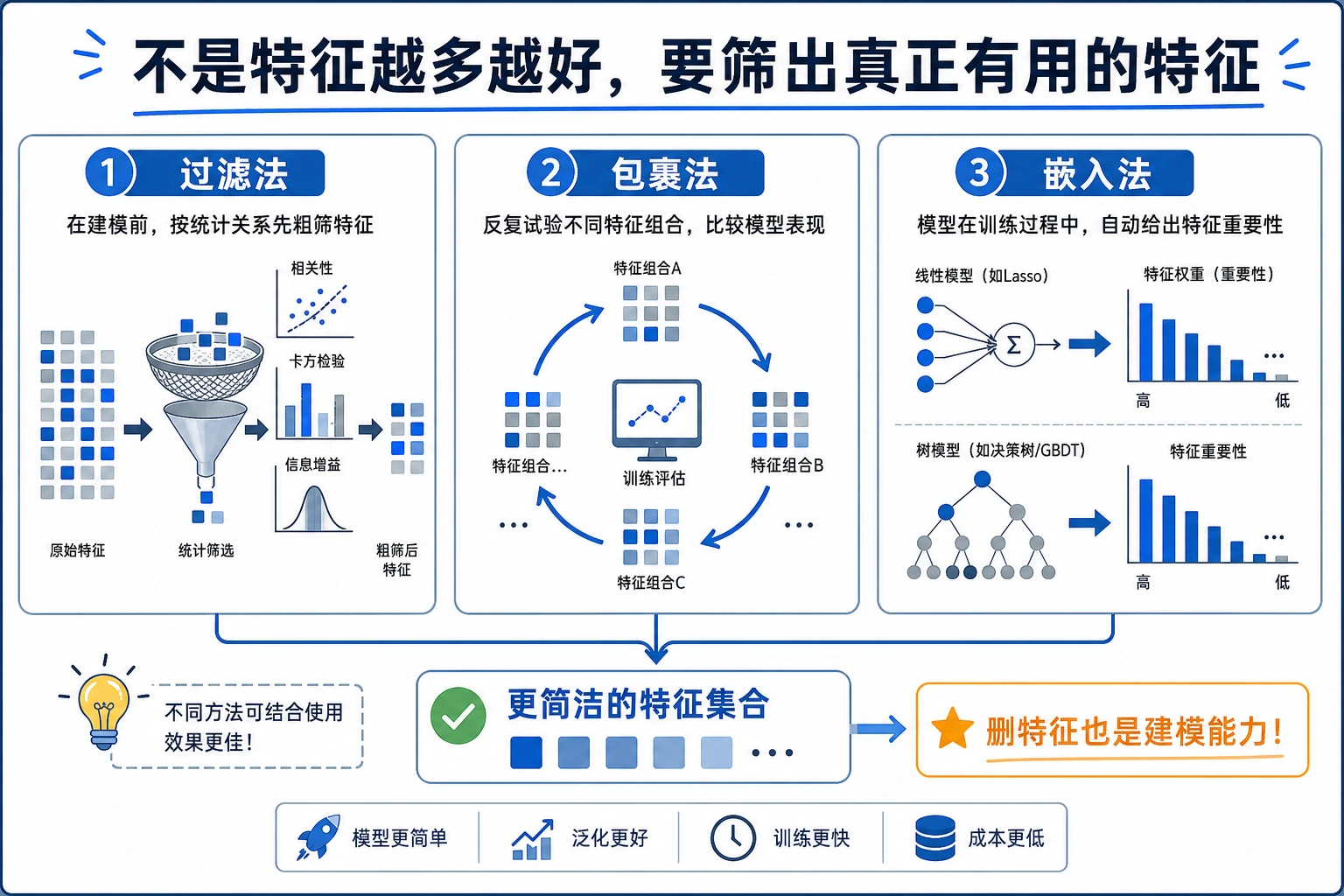
特征选择不是尽可能删掉更多特征,而是在效果、稳定性、解释性和成本之间做平衡。真正目标是保留对任务有用、上线时能获得、并且没有数据泄漏风险的特征。
学习目标
- 理解为什么特征不是越多越好
- 掌握三类基本方法:过滤法、包装法和嵌入法
- 用验证集和交叉验证判断特征选择是否真的有效
- 理解特征选择和业务解释性、上线成本之间的关系
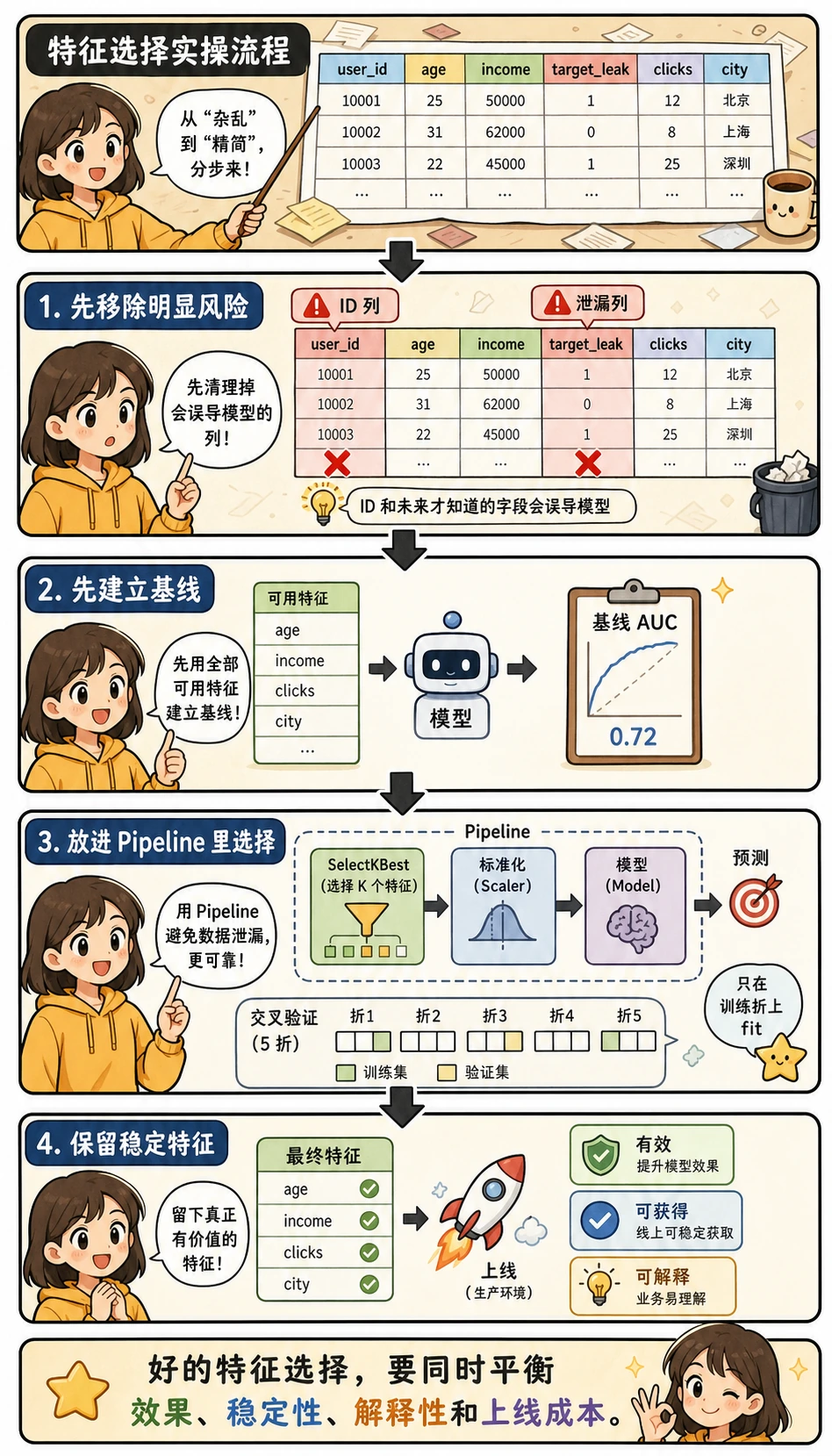
先看这张图,再看代码:特征选择不是“把表格删到很小”。更可靠的实操流程是先移除明显风险,再建立基线,把选择器放进 Pipeline,最后只保留真正有效、可获得、可解释的特征。
为什么需要特征选择
特征太多会带来几个问题:噪声更多、训练更慢、更容易过拟合、解释成本更高、生产依赖更复杂。在真实业务里,一个特征可能意味着一个额外数据源、一个 API、一套权限或一段维护逻辑。
写代码前先理解这些关键词
| 术语 | 新人友好解释 | 为什么这里重要 |
|---|---|---|
| ID | 标识符,例如 user_id 或 order_id | 可能让模型记住样本,而不是学习可泛化规律 |
| 目标泄漏 | 某个特征包含了答案发生之后才知道的信息 | 会让验证分数虚高 |
| 基线 | 第一个简单模型,用来作为比较起点 | 没有基线,就不知道特征选择是否真的有帮助 |
| AUC | ROC 曲线下面积,是分类中的排序指标 | 当模型输出概率时,适合比较不同特征集 |
| 过滤法 | 用统计分数先筛选特征 | 快,适合第一轮粗筛 |
| RFE | 递归特征消除,会不断移除较弱特征 | 更贴近模型表现,但更慢 |
| 嵌入法 | 模型训练时顺便完成特征选择 | 适合能输出系数或特征重要性的模型 |
fit | 从训练数据中学习规则 | 不能从验证集或测试集中学习 |
transform | 把学到的规则应用到数据上 | 保证验证集和测试集处理方式一致 |
Pipeline | 把预处理、特征选择和模型训练串成一个流程 | 交叉验证时可以防止数据泄漏 |
本节可复用代码准备
下面的例子会使用同一个数据集,因此你可以从上到下连续运行。本节使用乳腺癌数据集,因为它有很多数值特征、一个二分类目标,非常适合演示特征选择。
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import StratifiedKFold, cross_val_score, train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
cancer = load_breast_cancer(as_frame=True)
X = cancer.data
y = cancer.target
X_train, X_val, y_train, y_val = train_test_split(
X, y, test_size=0.25, random_state=42, stratify=y
)
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
print("Dataset shape:", X.shape)
print("Target names:", cancer.target_names.tolist())
print("First 5 columns:", X.columns[:5].tolist())
预期输出节选:
Dataset shape: (569, 30)
Target names: ['malignant', 'benign']
First 5 columns: ['mean radius', 'mean texture', 'mean perimeter', 'mean area', 'mean smoothness']
先移除不该进入模型的特征
第一步不是高级算法,而是人工检查。通常应该优先移除:
- 唯一 ID,例如
user_id、order_id、transaction_id - 目标结果发生之后才出现的字段
- 缺失率极高且没有业务意义的字段
- 训练时有、上线预测时不一定能稳定拿到的字段
- 明显重复的字段
乳腺癌数据集比较干净,没有 ID 或泄漏字段。但真实业务数据经常有这类字段。对新人来说,一个安全习惯是:建模前先写出明确的“不要使用”列表。
# 真实项目中的写法示例。
# 这个数据集没有这些列,这里展示的是可复用习惯。
risky_columns = ["user_id", "order_id", "target_leak"]
available_risky_columns = [col for col in risky_columns if col in X_train.columns]
X_train_safe = X_train.drop(columns=available_risky_columns)
X_val_safe = X_val.drop(columns=available_risky_columns)
print("Removed risky columns:", available_risky_columns)
print("Remaining feature count:", X_train_safe.shape[1])
ID 不一定永远没用,但新人一定要谨慎。很多 ID 会让模型记住训练样本,而不是学习能迁移到新样本的规律。
选择特征前先建立基线
在删除或筛选更多特征之前,先用所有安全特征训练一个模型。这个分数就是后面所有改动的比较起点。
baseline_model = Pipeline([
("scaler", StandardScaler()),
("clf", LogisticRegression(max_iter=5000, random_state=42)),
])
baseline_model.fit(X_train_safe, y_train)
baseline_auc = roc_auc_score(
y_val, baseline_model.predict_proba(X_val_safe)[:, 1]
)
print(f"Baseline validation AUC: {baseline_auc:.4f}")
如果后面的特征选择用更少特征得到相近的 AUC,它依然可能是有价值的,因为模型更简单、更快,也更容易解释。
过滤法:先看每个特征和目标的统计关系
过滤法不依赖最终模型。它先用统计指标筛选特征。例如,数值特征可以用 ANOVA F 检验,类别特征可以用卡方检验,高维稀疏特征可以用方差过滤。
from sklearn.feature_selection import SelectKBest, f_classif
filter_model = Pipeline([
("selector", SelectKBest(score_func=f_classif, k=10)),
("scaler", StandardScaler()),
("clf", LogisticRegression(max_iter=5000, random_state=42)),
])
filter_model.fit(X_train_safe, y_train)
filter_auc = roc_auc_score(
y_val, filter_model.predict_proba(X_val_safe)[:, 1]
)
selected_filter_cols = X_train_safe.columns[
filter_model.named_steps["selector"].get_support()
].tolist()
print(f"Filter method validation AUC: {filter_auc:.4f}")
print("Selected features:", selected_filter_cols)
如果想公平评估特征选择,不要先在全量数据上 fit 选择器。应该把它放进交叉验证流程或 Pipeline,这样每一折只会基于自己的训练部分选择特征。
过滤法速度快,适合初筛。缺点是容易漏掉特征之间的交互:某个特征单独看可能很弱,但和另一个特征组合起来可能很有用。
包装法:用模型表现反复测试
包装法用模型训练表现作为选择依据。常见方法是 RFE,也就是递归特征消除。RFE 会训练模型、移除较弱特征,然后重复这个过程,直到剩下指定数量的特征。
from sklearn.feature_selection import RFE
rfe_model = Pipeline([
("scaler", StandardScaler()),
("selector", RFE(
estimator=LogisticRegression(max_iter=5000, solver="liblinear", random_state=42),
n_features_to_select=10,
)),
("clf", LogisticRegression(max_iter=5000, random_state=42)),
])
rfe_model.fit(X_train_safe, y_train)
rfe_auc = roc_auc_score(
y_val, rfe_model.predict_proba(X_val_safe)[:, 1]
)
selected_rfe_cols = X_train_safe.columns[
rfe_model.named_steps["selector"].get_support()
].tolist()
print(f"RFE validation AUC: {rfe_auc:.4f}")
print("Selected features:", selected_rfe_cols)
当特征数量不是特别大,并且你愿意花更多计算成本来得到更贴近模型表现的结果时,包装法很适合。
嵌入法:让模型在训练中决定重要性
嵌入法是在模型训练过程中完成选择。带 L1 正则的线性模型、Random Forest、GBDT、XGBoost、LightGBM 都可以体现这种思路。
from sklearn.feature_selection import SelectFromModel
l1_model = Pipeline([
("scaler", StandardScaler()),
("selector", SelectFromModel(
LogisticRegression(
solver="liblinear",
l1_ratio=1,
C=0.1,
max_iter=5000,
random_state=42,
)
)),
("clf", LogisticRegression(max_iter=5000, random_state=42)),
])
l1_model.fit(X_train_safe, y_train)
l1_auc = roc_auc_score(
y_val, l1_model.predict_proba(X_val_safe)[:, 1]
)
selected_l1_cols = X_train_safe.columns[
l1_model.named_steps["selector"].get_support()
].tolist()
print(f"L1 embedded selection validation AUC: {l1_auc:.4f}")
print(f"Selected feature count: {len(selected_l1_cols)}")
print("Selected features:", selected_l1_cols)
在当前 sklearn 版本中,l1_ratio=1 表示纯 L1 正则。C 控制正则强度,C 越小正则越强,L1 模型越可能把一些系数压到 0,从而移除对应特征。
特征重要性不是绝对真理。不同模型、随机种子和数据切分都会影响排序。最好结合验证表现和业务理解一起判断。
用交叉验证确认是否真的变好
特征选择最容易犯的错误,是只看选出来的特征“好像合理”,却没有验证模型是否真的更稳定。正确做法是把基线模型和特征选择后的模型放在一起比较。
experiments = {
"all_features": baseline_model,
"filter_top_10": filter_model,
"rfe_top_10": rfe_model,
"l1_embedded": l1_model,
}
rows = []
for name, pipe in experiments.items():
scores = cross_val_score(pipe, X_train_safe, y_train, cv=cv, scoring="roc_auc")
rows.append({
"experiment": name,
"mean_auc": scores.mean(),
"std_auc": scores.std(),
})
results = pd.DataFrame(rows).sort_values("mean_auc", ascending=False)
print(results)
如果更少的特征能得到接近的表现,同时训练更快、解释更清楚、生产依赖更少,那它可能就是更好的方案。
如何决定最终保留什么
真实项目中的特征选择不能只看分数。还要考虑是否稳定、可解释、可上线、合规、成本是否划算。一个特征如果只让 AUC 提升 0.001,却需要接入昂贵的外部数据源,可能并不值得上线。
| 问题 | 适合保留的条件 |
|---|---|
| 效果 | 能提升主指标,或用更少特征保持分数稳定 |
| 稳定性 | 在不同折或不同时间段中都比较稳定 |
| 可获得性 | 预测时确实能拿到这个字段 |
| 可解释性 | 能解释它为什么应该有帮助 |
| 成本 | 数据源和维护成本值得承担 |
新人可直接套用的判断规则
第一次做项目时,可以使用这个保守规则:
- 先手动移除明显风险列
- 保留全特征基线
- 先尝试一个简单选择方法,例如
SelectKBest - 用交叉验证比较,不要只看一次切分
- 只有在分数相近或更好,并且特征有意义时,才保留更小的特征集
常见错误
第一个错误是在全量数据上做特征选择,然后再切分训练集和测试集,这会造成泄漏。第二个错误是盲目信任特征重要性排序。第三个错误是追求特征越少越好,导致欠拟合。第四个错误是忽略生产可获得性:训练时能用的字段,线上实时预测时不一定能用。
练习
- 在一个分类数据集上使用
SelectKBest选择前 10 个特征,并和基线模型比较。 - 使用 RFE 分别选择 8、10、15 个特征,比较 AUC 和被选中特征名称。
- 使用 L1 逻辑回归,分别设置
C=0.01、C=0.1、C=1.0,观察保留特征数量如何变化。 - 手动列出 3 个训练时可能存在、但生产预测时不一定稳定可获得的字段。
- 解释为什么特征选择必须放在交叉验证流程内部。
掌握标准
学完本节后,你应该能够解释过滤法、包装法和嵌入法的区别;能用验证集和交叉验证判断特征选择是否有效;能识别数据泄漏风险;并能从效果、解释性、成本和生产可获得性几个角度决定是否保留某个特征。