特征选择
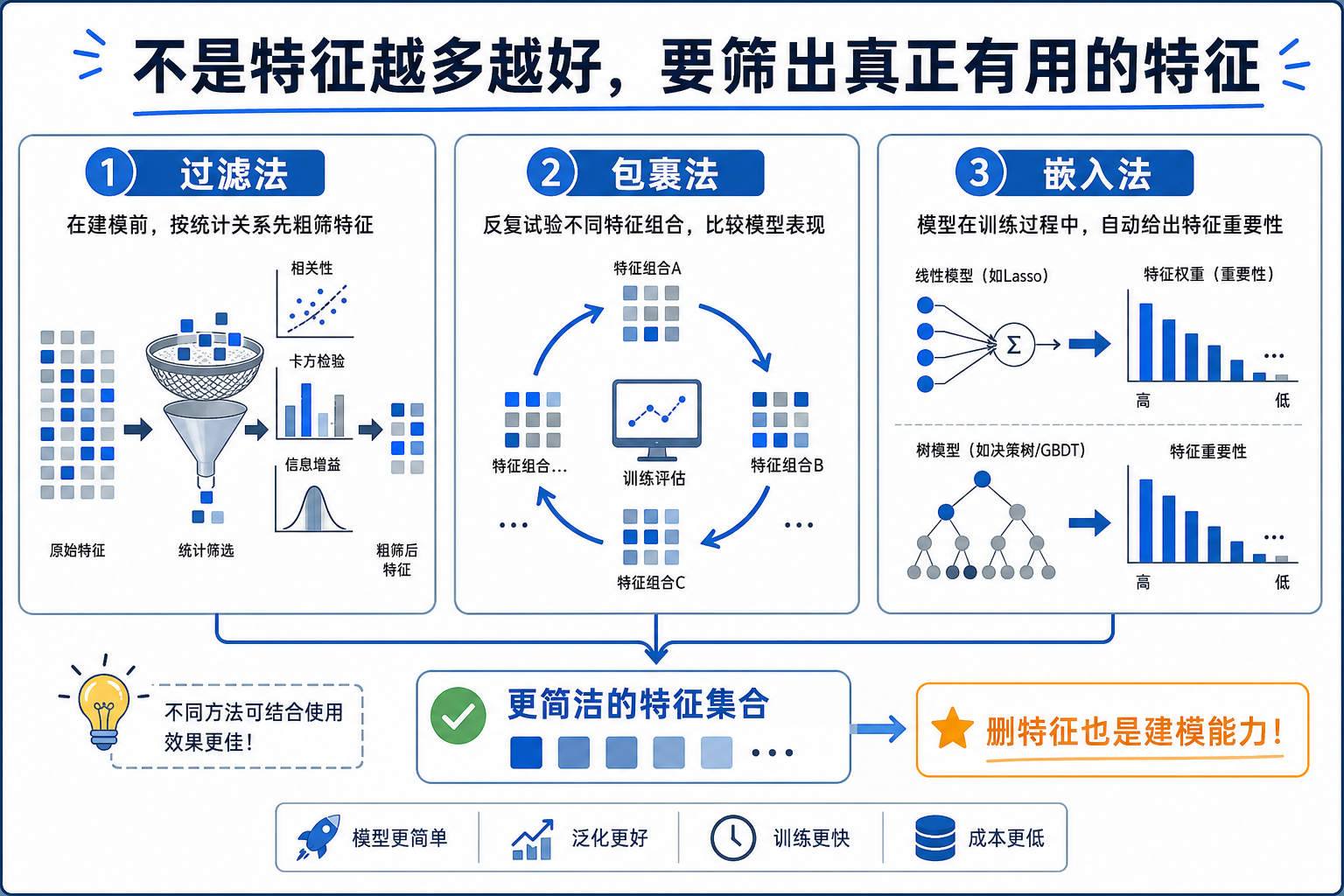
特征选择不是为了把特征删得越少越好,而是为了在效果、稳定性、解释性和成本之间取得平衡。真正的目标是留下对任务有用、上线时可获得、不会泄漏的特征。
学习目标
- 理解为什么特征不是越多越好
- 掌握过滤法、包裹法、嵌入法三类基本思路
- 能用验证集判断特征选择是否真的有效
- 知道特征选择和业务可解释性、上线成本的关系
为什么需要特征选择
特征太多会带来几个问题:噪声增加,训练变慢,模型更容易过拟合,解释成本上升,上线时数据依赖变复杂。尤其在真实业务里,一个特征可能意味着一个额外数据源、一个接口、一个权限或一段维护逻辑。
一、先删掉不该进模型的特征
第一步不是高级算法,而是人工排查。通常应该优先移除:唯一 ID、目标结果之后才出现的字段、缺失率极高且无业务意义的字段、训练和线上不可稳定获得的字段、明显重复的字段。
cols_to_drop = ["user_id", "order_id"]
X = df.drop(columns=cols_to_drop + ["target"])
y = df["target"]
ID 并不总是无用,但初学阶段要谨慎。很多 ID 会让模型记住训练样本,而不是学到可泛化规律。
二、过滤法:先看单个特征的统计关系
过滤法不依赖具体模型,先用统计指标筛选特征。例如数值特征可以看相关系数,类别特征可以看卡方检验,文本或高维特征可以看方差。
from sklearn.feature_selection import SelectKBest, f_classif
selector = SelectKBest(score_func=f_classif, k=10)
X_selected = selector.fit_transform(X_train, y_train)
selected_cols = X_train.columns[selector.get_support()]
print(selected_cols)
过滤法速度快,适合初筛;缺点是容易忽略特征之间的组合效果。
三、包裹法:用模型效果反复试
包裹法把模型训练效果作为选择标准,例如递归特征消除 RFE。它更贴近最终目标,但计算成本更高。
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
estimator = LogisticRegression(max_iter=1000)
selector = RFE(estimator, n_features_to_select=8)
selector.fit(X_train_scaled, y_train)
print(selector.support_)
包裹法适合特征数量不太大、你愿意花计算成本换更贴近模型效果的场景。
四、嵌入法:让模型自己给出重要性
一些模型在训练过程中就能给出特征重要性,例如 L1 正则的线性模型、随机森林、GBDT、XGBoost、LightGBM。
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
importance = model.feature_importances_
注意,特征重要性不是绝对真理。不同模型、不同随机种子、不同数据切分都可能影响排名。最好结合验证集效果和业务理解一起判断。
五、用验证集确认是否真的变好
特征选择最容易犯的错是只看“选出来的特征看起来合理”,却不验证模型是否更稳。正确做法是比较 baseline 和选择后的模型。
from sklearn.metrics import roc_auc_score
baseline_model.fit(X_train, y_train)
baseline_auc = roc_auc_score(y_val, baseline_model.predict_proba(X_val)[:, 1])
selected_model.fit(X_train_selected, y_train)
selected_auc = roc_auc_score(y_val, selected_model.predict_proba(X_val_selected)[:, 1])
print("baseline", baseline_auc)
print("selected", selected_auc)
如果特征变少后效果差不多,但训练更快、解释更清楚、上线依赖更少,那也可能是更好的方案。
六、真实项目里的选择标准
真实项目中,特征选择不只看分数,还要看是否稳定、是否能解释、是否能上线、是否有合规风险、是否会引入额外成本。一个 AUC 提升 0.001 但需要接入昂贵外部数据源的特征,未必值得上线。
常见误区
第一个误区是在全量数据上做特征选择,再切分训练测试集,这会泄漏。第二个误区是盲目相信特征重要性排名。第三个误区是只追求最少特征,导致模型欠拟合。第四个误区是忽略上线可获得性,训练时能用的字段不代表线上实时能拿到。
练习
- 在一个分类数据集上,用 SelectKBest 选择前 10 个特征,并和 baseline 比较。
- 用随机森林输出特征重要性,观察排名是否符合直觉。
- 手动列出 3 个“训练时可能有、上线时不一定有”的特征。
- 解释为什么特征选择必须放在交叉验证流程内部。
过关标准
学完本节后,你应该能解释三类特征选择方法的差异,能用验证集判断选择是否有效,能识别数据泄漏风险,并能从效果、解释性、成本和上线可获得性四个角度决定是否保留某个特征。