9.7.2 マルチ Agent のアーキテクチャパターン
多くの人が初めてマルチ Agent を作るとき、いちばんやりがちなミスは次のようなものです。
「1つの Agent では足りないなら、もっとたくさん動かせばいい」
でも、本当に大事なのは「数」ではなく、次の点です。
これらの Agent をどう分担させ、どう組織化し、どう協力させるか。
これこそが、マルチ Agent のアーキテクチャパターンが解決したい核心です。
学習目標
- いつ本当にマルチ Agent が必要なのかを理解する
- よく使われるマルチ Agent のアーキテクチャパターンを整理する
- supervisor、pipeline、reviewer などの長所と短所を理解する
- 小さな例を通して、異なるパターンの組織のしかたを体感する
なぜすべてのタスクにマルチ Agent が必要ではないのか?
マルチ Agent はデフォルトの拡張先ではない
もともと単一 Agent で安定して完了できるタスクなら、マルチ Agent にするとむしろ次のものが増えがちです。
- 通信コスト
- デバッグの難しさ
- 失敗の経路
そのため、より安全な考え方はたいてい次の通りです。
まず単一 Agent をしっかり作り、そのあとで本当に分割が必要かを考える。
では、どんなときにマルチ Agent を使う価値があるのか?
一般的には、次のような場合です。
- タスクを明確に分けられる
- サブタスクの種類の違いが大きい
- 1つの Agent が全部の責任を持つと複雑すぎる
- 独立した計画、実行、レビューの役割が必要
このときはじめて、マルチ Agent に意味が出てきます。
まずはよく使われるいくつかのパターンを見る
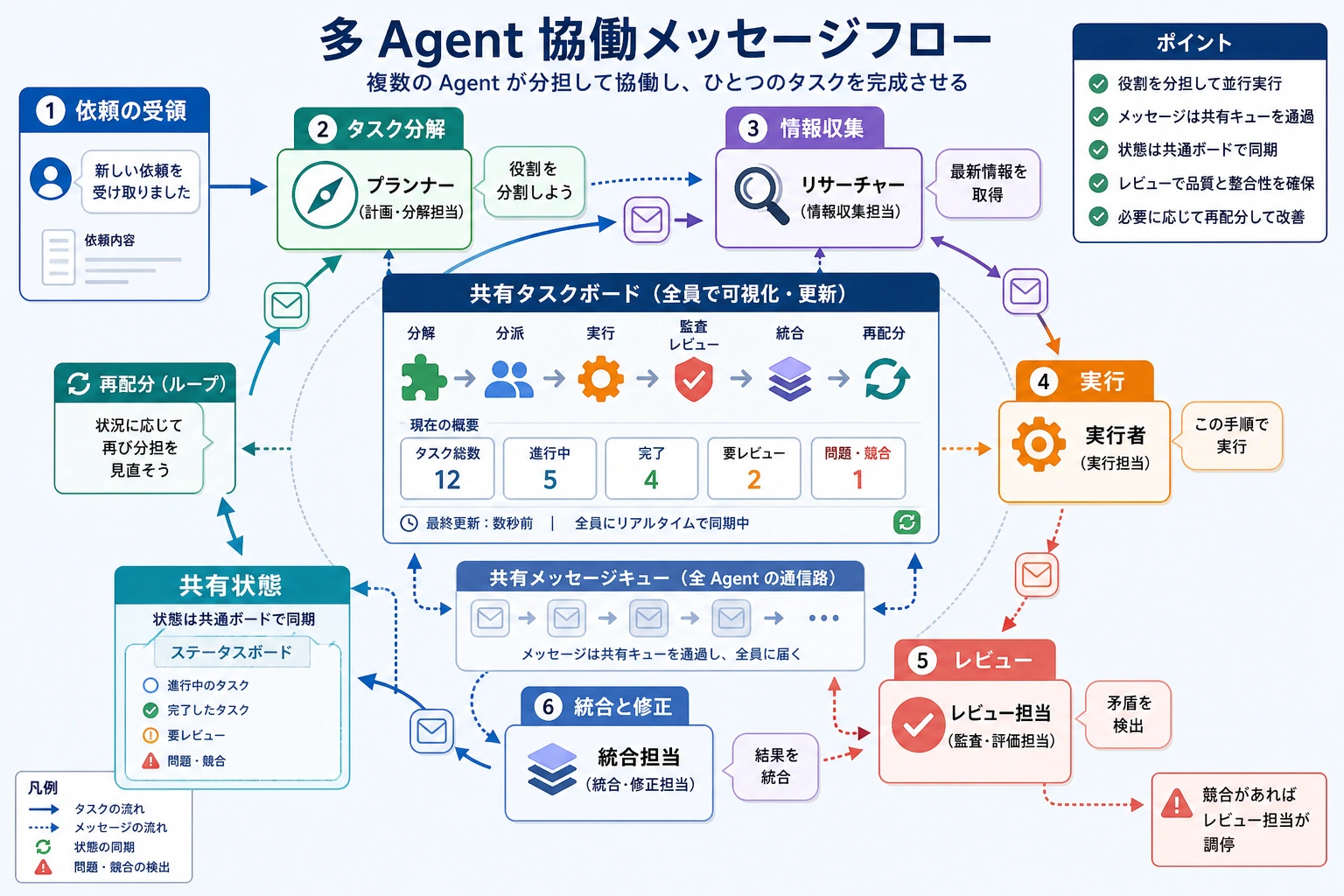
Supervisor-Worker パターン
1つの監督者(supervisor)が次を担当します。
- タスクを分解する
- タスクを割り当てる
- 結果をまとめる
他の worker は具体的な実行を担当します。
これは最もよく使われ、理解しやすいパターンの1つです。
Pipeline パターン
各 Agent は固定された段階だけを担当します。
- 検索
- 分析
- 執筆
これは、工場のラインに近い考え方です。
Reviewer パターン
1つの Agent が生成を担当し、別の Agent が専用でチェックやレビューを行います。
これはコード、ドキュメント、レポート生成で特によく使われます。
Group / Peer パターン
複数の Agent が比較的対等な立場で話し合います。
このパターンは柔軟ですが、そのぶん制御は難しくなります。
Supervisor-Worker:まず学ぶ価値が高いパターン
なぜよく使われるのか?
多くの現実のチーム構造にとても近いからです。
- プロジェクトマネージャー / リーダーがタスクを分解する
- 実行担当が具体的な作業をする
最小の実行可能な例
tasks = ["資料を検索する", "要点を整理する", "要約を書く"]
workers = {
"researcher": "資料を探す担当",
"analyst": "情報を整理する担当",
"writer": "最終テキストを生成する担当"
}
assignment = {
"資料を検索する": "researcher",
"要点を整理する": "analyst",
"要約を書く": "writer"
}
for task in tasks:
worker = assignment[task]
print(f"{worker} <- {task} ({workers[worker]})")
想定出力:
researcher <- 資料を検索する (資料を探す担当)
analyst <- 要点を整理する (情報を整理する担当)
writer <- 要約を書く (最終テキストを生成する担当)
長所と短所
長所:
- 分担が分かりやすい
- 制御しやすい
- どの段階で問題が起きたか観察しやすい
短所:
- supervisor がボトルネックになることがある
- タスク分解が悪いと、後続がすべて影響を受ける
Pipeline パターン:工場のラインのように協力する
supervisor パターンとの違い
supervisor パターンは「中心が調整する」ことを重視します。
pipeline パターンは「タスクが固定された段階に沿って流れる」ことを重視します。
たとえば、次のような流れです。
- Retriever Agent が資料を探す
- Filter Agent がノイズを除く
- Writer Agent が回答を生成する
最小の例
def retriever(query):
return {"docs": ["返金ポリシー", "証明書の説明"], "query": query}
def filter_agent(data):
return {"docs": [doc for doc in data["docs"] if "返金" in doc], "query": data["query"]}
def writer(data):
if not data["docs"]:
return "十分に関連する情報が見つかりませんでした。"
return f"{data['docs']} をもとに、最終回答を生成します。"
query = "返金ポリシーとは何ですか"
step1 = retriever(query)
step2 = filter_agent(step1)
step3 = writer(step2)
print(step1)
print(step2)
print(step3)
想定出力:
{'docs': ['返金ポリシー', '証明書の説明'], 'query': '返金ポリシーとは何ですか'}
{'docs': ['返金ポリシー'], 'query': '返金ポリシーとは何ですか'}
['返金ポリシー'] をもとに、最終回答を生成します。
どんな場面に向いている?
向いているのは次のような場面です。
- 段階が固定されている
- 順序がはっきりしている
- 各レイヤーの役割が非常に明確
あまり向いていないのは次のような場面です。
- 途中で何度も計画を見直す必要がある
- 柔軟な協議がたくさん必要
Reviewer パターン:生成とチェックを分ける
なぜ実用的なのか?
多くのタスクでは、「生成」と「レビュー」は本質的に異なる能力だからです。
たとえば、次のような対になります。
- コードを書く vs コードレビューをする
- レポートを書く vs 事実確認をする
- 答えを作る vs リスクを確認する
実行できる例
def writer_agent(topic):
return f"{topic} についての下書き: コース購入後7日以内は返金できます。"
def reviewer_agent(text):
if "7日以内" in text:
return {"approved": True, "comment": "重要な情報はカバーされています"}
return {"approved": False, "comment": "重要な期限条件が不足しています"}
draft = writer_agent("返金ポリシー")
review = reviewer_agent(draft)
print("draft :", draft)
print("review:", review)
想定出力:
draft : 返金ポリシー についての下書き: コース購入後7日以内は返金できます。
review: {'approved': True, 'comment': '重要な情報はカバーされています'}
なぜ使いやすいのか?
「生成の品質」と「チェックの品質」を分けて管理できるからです。
これは、リスクの高いタスクで特に価値があります。
Peer / Group パターン:複数の Agent が対等に協力する
自由そうに見えるが、制御は難しい
このパターンでは、複数の Agent がそれぞれ提案し、議論し、補足できます。
長所:
- 柔軟
- さまざまな案を引き出しやすい
短所:
- 作業の重複が起きやすい
- 話がそれやすい
- 収束しにくい
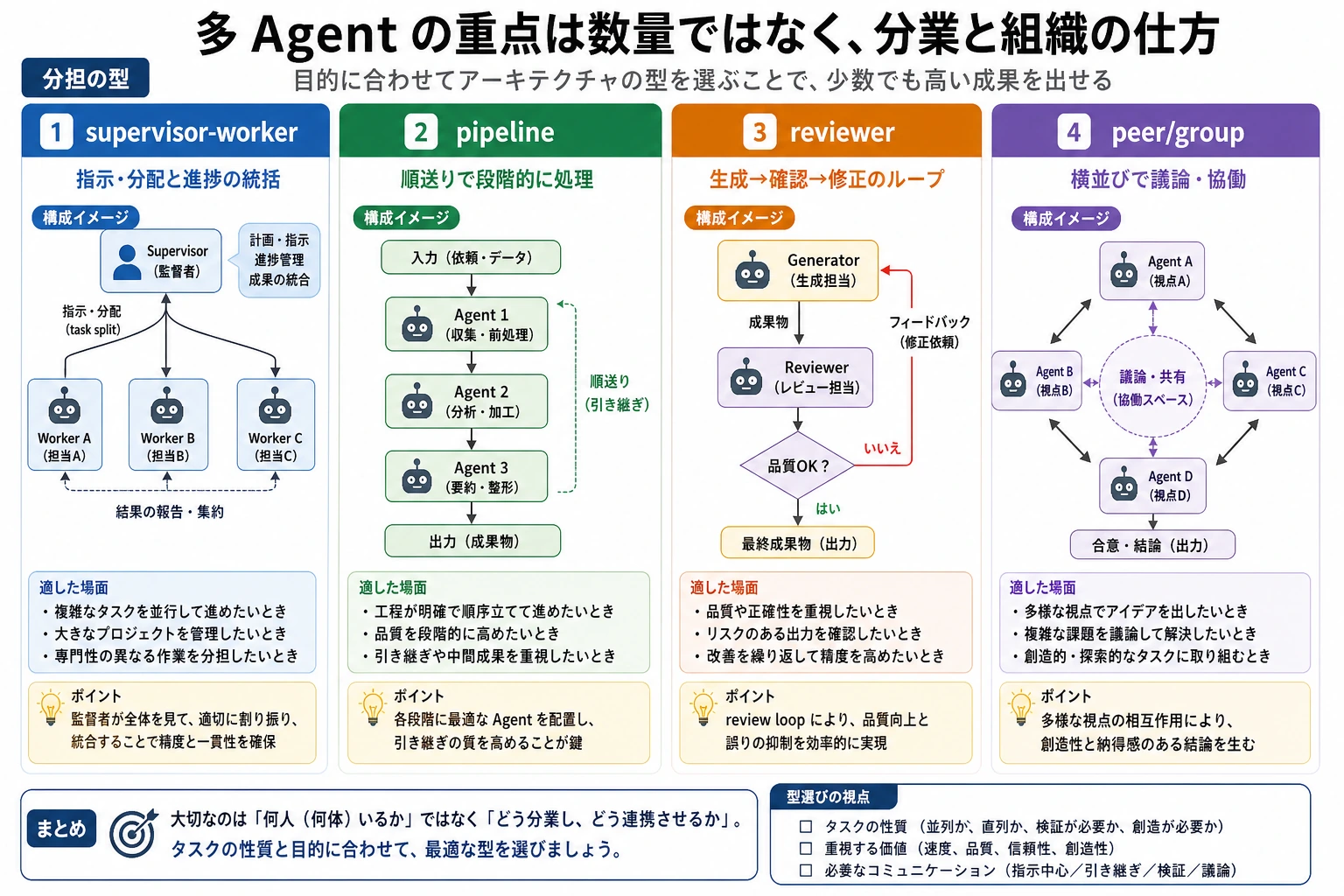
この図を見るときは、まずタスクに自然な分担があるかを確認しましょう。中心的な調整が必要なら supervisor-worker、段階が固定なら pipeline、品質チェックが必要なら reviewer、多視点の議論が必要なときだけ peer/group を考えます。
どんなときに考える?
次のような場面に向いています。
- ブレインストーミング
- 方案の比較
- 多視点での分析
ただし、多くのエンジニアリングシステムでは、最初の選択肢として最も安定しているとは限りません。
とても大事な問題:最後の取りまとめは誰がするのか?
どのパターンを使う場合でも、この問いに答える必要があります。
最終的に誰が「タスク完了」を決めるのか?
これを設計していないと、次のようなことが起こりやすくなります。
- みんなが作業しているのに、誰も終わりを決めない
- 複数の Agent が何度も行き来する
- タスクがいつまでも終わらない
だから、多くのマルチ Agent システムには、最後に「最終判断者」がいます。
マルチ Agent のアーキテクチャをどう選ぶか
タスクの段階が固定されているなら
優先するのは次です。
- Pipeline パターン
中心となる分解と調整が必要なら
優先するのは次です。
- Supervisor-Worker パターン
強いレビューと再確認が必要なら
優先するのは次です。
- Writer-Reviewer パターン
タスクそのものが多視点の議論なら
そのときに考えるのが次です。
- Peer / Group パターン
大事なのは「どのパターンが上位か」ではなく、次の点です。
どのパターンが自分のタスクの形にいちばん合っているか。
初心者がよくハマる落とし穴
マルチ Agent を「モデルをたくさん動かせばいいもの」と考える
本当に難しいのは数ではなく、アーキテクチャです。
最初からいちばん自由な協力パターンを選ぶ
自由度が高いほど、デバッグと収束は難しくなるのが普通です。
終了条件が明確でない
これは、多くのマルチ Agent の demo が「賢そうに見えるのに、実際に動かすと無限ループしやすい」原因です。
まとめ
この節で最も大事なのは、パターン名を覚えることではなく、次を理解することです。
マルチ Agent のアーキテクチャパターンの核心は、タスクを適切な役割と協力関係に分けることです。単に参加者を増やすことではありません。
アーキテクチャパターンを正しく選べば、システムはより安定し、より制御しやすくなります。
間違えると、複雑さが利益より早く大きくなってしまいます。
練習
- supervisor、pipeline、reviewer の3つのパターンの違いを、自分の言葉で説明してみましょう。
- 「自動研究レポート」を作るなら、どのパターンから始めるのがよいか考えてみましょう。なぜですか?
- 「検索 -> 執筆 -> レビュー」の3 Agent のパイプラインを設計してみましょう。
- なぜ、マルチ Agent アーキテクチャはまず「モデル数」の問題ではなく「組織の問題」だと言えるのでしょうか?