9.3.8 コード生成と実行 Agent
コード Agent と聞くと、多くの人がまず思い浮かべるのは次のことです。
- 自動でコードを書いてくれる
もちろん、それも一部です。
でも、本当に動くコード Agent は、単に「コードを生成する」だけではありません。
少なくとも、次のような閉ループを回す必要があります。
文脈を読む -> 修正計画を立てる -> 変更を出す -> 検証を実行する -> 結果を見てさらに修正する
この閉ループがなければ、そのシステムはコード補完器に近く、本当のコード Agent とは言えません。
学習目標
- コード Agent と普通のコード生成の根本的な違いを理解する
- コード Agent の最小ワークループを理解する
- 実行可能な例を通して、「読む-直す-動かす-確認する」がなぜ閉ループである必要があるのかを理解する
- サンドボックス、テスト、ロールバックがコード Agent でなぜ重要かを理解する
コード Agent と「モデルにコードを書かせる」のは何が違うのか?
普通のコード生成は一回きりの出力に近い
たとえば:
- 「クイックソートを書いて」
モデルがコードを出力したら、
そのタスクはたいていそこで終わります。
コード Agent は、実際のリポジトリの中で作業する感じに近い
扱うタスクは、もっと次のようなものです。
- bug を修正する
- 関数にテストを追加する
- 設定を変更する
- エラーを見て二回目の修正をする
つまり、次のようなものを処理しなければなりません。
- 文脈
- バージョン状態
- 実行フィードバック
- エラー復旧
比喩でいうと:例題の答えを書く vs 本当にプロジェクトに入って問題を直す
「コード生成」は、面接でホワイトボードに問題を解くようなものです。
「コード Agent」は、実際にリポジトリに入って作業する感じです。
- まずプロジェクトを読む
- ファイルを探す
- 一か所直す
- テストを回す
- エラーを見る
- もう一度修正する
この二つは、難易度がまったく違います。
コード Agent の最小閉ループとは何か?
Read:まず文脈を読む
通常、次のような情報が必要です。
- 関連ファイルがどこにあるか
- 関数が今どう書かれているか
- テストがどう整理されているか
Plan:修正案を立てる
たとえば:
- 実装を直す
- テストを補う
- 設定を調整する
Act:実際に変更する
ここが、みんなが最も思い浮かべやすい「コードを書く」部分です。
Verify:検証を実行する
たとえば:
- 単体テストを回す
- スクリプトを実行する
- 出力を見る
Repair:フィードバックを見てさらに修正する
これも、コード Agent と普通の生成器の大きな違いの一つです。
- 実行結果を読み、それを次のループに反映する
まずは最小の「コード Agent 閉ループ」例を動かしてみる
次の例は、実際にファイルを変更するわけではありません。
でも、非常に重要な一連の流れを完全に再現しています。
- 関数実装に bug があると見つける
- パッチ関数を生成する
- テストを実行する
- テストに通れば変更を受け入れる
def buggy_discount(price, discount_rate):
# エラー: 8割引を 8 円引きとして扱っている
return price - discount_rate
def generate_patch():
def fixed_discount(price, discount_rate):
return price * discount_rate
return fixed_discount
def run_tests(fn):
cases = [
((100, 0.8), 80.0),
((50, 0.5), 25.0),
]
failures = []
for args, expected in cases:
actual = fn(*args)
if actual != expected:
failures.append(
{
"args": args,
"expected": expected,
"actual": actual,
}
)
return failures
current_impl = buggy_discount
failures = run_tests(current_impl)
print("修正前の失敗:", failures)
if failures:
candidate_impl = generate_patch()
candidate_failures = run_tests(candidate_impl)
print("修正後の失敗:", candidate_failures)
if not candidate_failures:
current_impl = candidate_impl
print("パッチを受け入れました")
期待される出力:
修正前の失敗: [{'args': (100, 0.8), 'expected': 80.0, 'actual': 99.2}, {'args': (50, 0.5), 'expected': 25.0, 'actual': 49.5}]
修正後の失敗: []
パッチを受け入れました
このコードは実際の世界では何に対応するのか?
これは、コード Agent の最も核となる閉ループに対応しています。
- ただコードを出力するだけではない
- コードが検証に通る必要がある
これが欠けると、
システムはすぐに次のようになりがちです。
- 見た目はもっともらしいコードを書く
- でも実際には動かない
なぜ generate_patch より run_tests のほうが重要なのか?
なぜなら、システムを現実に引き戻すのは、
多くの場合、生成能力ではなく検証能力だからです。
検証がなければ、コード Agent はすぐに次の状態で止まりやすくなります。
- なんとなく正しそう
なぜこれが Agent であって、単なる「関数の差し替え」ではないのか?
次の要素があるからです。
- 現在の状態
- 候補となる行動
- 外部からのフィードバック
- 意思決定の更新
これはもう、最小構成の agentic loop です。
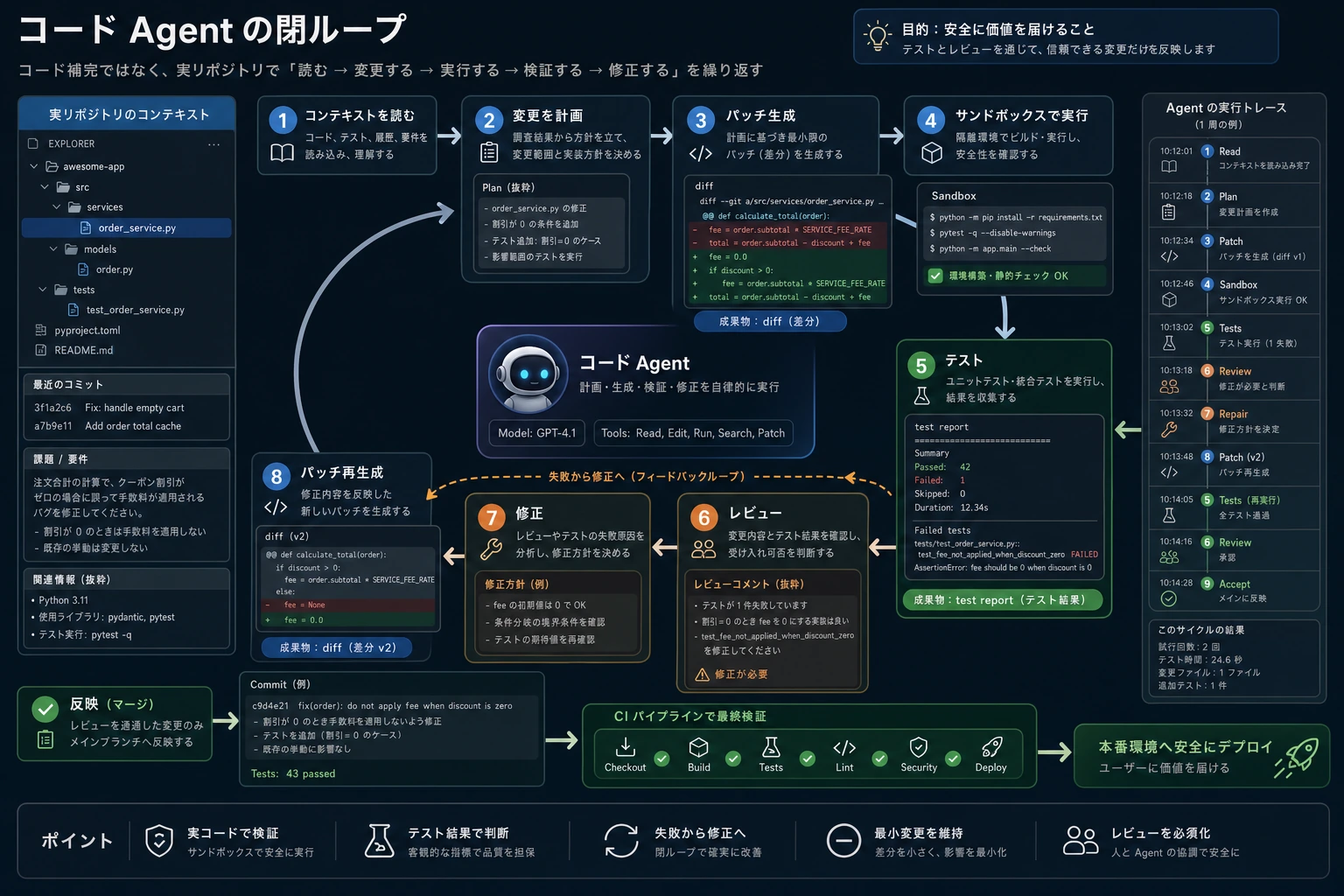
コード Agent のポイントは「コードが書けること」ではなく、サンドボックスの中で文脈を読み、patch を生成し、テストを回し、失敗を見て、もう一度修正できることです。図の Verify と Review は、アイデアを現実に引き戻すための重要な部分です。
実際のコード Agent では、他にどんな重要な工程があるのか?
ファイルの特定と読み込み
実際のリポジトリでは、まず次のことを解決する必要があります。
- どのファイルを直すか
- どの実装部分を見るか
- どのテストが関係するか
全ファイルの書き直しではなく patch 形式にする
より安定したやり方は、通常次のどちらかです。
- patch を生成する
- あるいは局所的な diff にする
なぜなら、そうすると次の利点があるからです。
- 変更が小さい
- review しやすい
- ロールバックしやすい
実行環境の分離
コード Agent には、次のようなことが必要になる場面が多いです。
- コードを実行する
- テストを実行する
- ファイルを読み書きする
そのため、次のような要素が関わります。
- サンドボックス
- 権限の境界
- タイムアウト
ロールバックと再試行
候補のパッチが失敗したら、
システムはできれば次のように動くべきです。
- 元のバージョンを残す
- 失敗した変更を捨てる
- 別の修正方法を試す
なぜコード Agent は特に検証に依存するのか?
コードタスクには客観的なフィードバックがあることが多いから
純粋なテキストタスクと比べて、コードタスクの大きな利点の一つは、
多くの場合、はっきりした結果を得られることです。
たとえば:
- テストが通るか
- プログラムがエラーになるか
- 出力が期待どおりか
これにより、コード Agent は「試して直す」反復にとても向いている
次のように進められます。
- まず一版修正する
- フィードバックを実行する
- 失敗に応じてさらに修正する
だからこそ、コード Agent は Agent システムの中でも、特に強い閉ループを作りやすい種類なのです。
ただし、楽観しすぎてもいけない
「テストが通った」からといって、必ずしも次のことが保証されるわけではありません。
- 回帰がない
- ロジックが本当に完全である
なので、検証は強力ですが、
万能ではありません。
コード Agent でよく起きる失敗ポイント
文脈を理解しないまま修正する
これにより、次のような問題が起きます。
- 間違ったファイルを直す
- 既存の API 仕様を壊す
- 今あるスタイルと合わない
表面的なエラーだけ直して、根本原因を理解しない
典型例は次のようなものです。
- if を一つ足す
- 例外を押し込める
- テストが「たまたま通る」状態にする
でも、本当の問題は残ったままです。
検証が不十分
たとえば、単一の happy path だけを実行して、
次のような観点を見ていない場合です。
- 境界入力
- 回帰リスク
- 関連モジュール
コード Agent をエンジニアリング上で守るべきことは何か?
ロールバック可能であること
自動変更はどれも、次のようにできるべきです。
- 元に戻せる
小さくコミットすること
patch が小さいほど、次のことがしやすくなります。
- review
- 問題の特定
- 次の修正
明確な境界を持つこと
たとえば:
- 指定ディレクトリだけを変更できる
- 特定のコマンドだけ実行できる
- 高リスクなコマンドは人の確認が必要
まとめ
この節で最も大事なのは、コード Agent を「コードが書けるモデル」として理解することではなく、
その本当の閉ループを理解することです。
コード Agent の核心は、実際のリポジトリの文脈を中心に、読む・直す・動かす・確認する・さらに直す、という流れを安定して回すことです。
この閉ループがはっきり分かれば、
この先もっと複雑なものを見ても、
- 自動 bug 修正
- 自動テスト追加
- 自動リファクタリング
が、どこで本当に難しくなるのか分かるようになります。
練習
- 例にある
buggy_discountを自分の bug 関数に置き換えて、patch を一つ設計してみましょう。 - なぜコード Agent は普通のコード生成より「フィードバック閉ループ」に強く依存すると言えるのでしょうか?
- 考えてみましょう: テストがなければ、コード Agent はほかにどんな検証方法に頼れるでしょうか?
- なぜ patch は小さいほど、通常はコード Agent に向いているのでしょうか?