9.2.2 LLM 推論能力
多くの人が初めて Agent に触れるとき、大規模モデルを自然に次のように理解します。
- 会話できる
- 文章を書ける
- ツールを呼び出せる
でも、Agent に「頭脳」があると言えるかどうかは、ただ話せるかではなく、次の点にあります。
複雑な問題に出会ったとき、問題を分解して、中間状態を保ちながら、段階的に結論へ進めるか。
これが推論能力で解決したいことです。
学習目標
- 「知識検索」と「推論による解決」は同じではないと理解する
- LLM の推論でよくある 3 種類のタスク形態を理解する
- 実行可能な例を通して「中間状態」がなぜ重要かを理解する
- Agent がなぜツールだけでは足りず、推論層も必要なのかを理解する
この節は、前の Agent 基礎とどうつながるのか
「Agent とは何か」を学び終えたばかりなら、この節はまず次のように理解するとよいです。
- 前の節で、Agent は目標に沿って行動する必要があると分かった
- この節では、ではそれをどうやって複雑な問題に分解し、中間状態を保つのかを考える
なので、この節で本当に大事なのは「推論という言葉が高度に聞こえること」ではなく、次の点です。
- 推論層は Agent システムの中で何を担当するのか
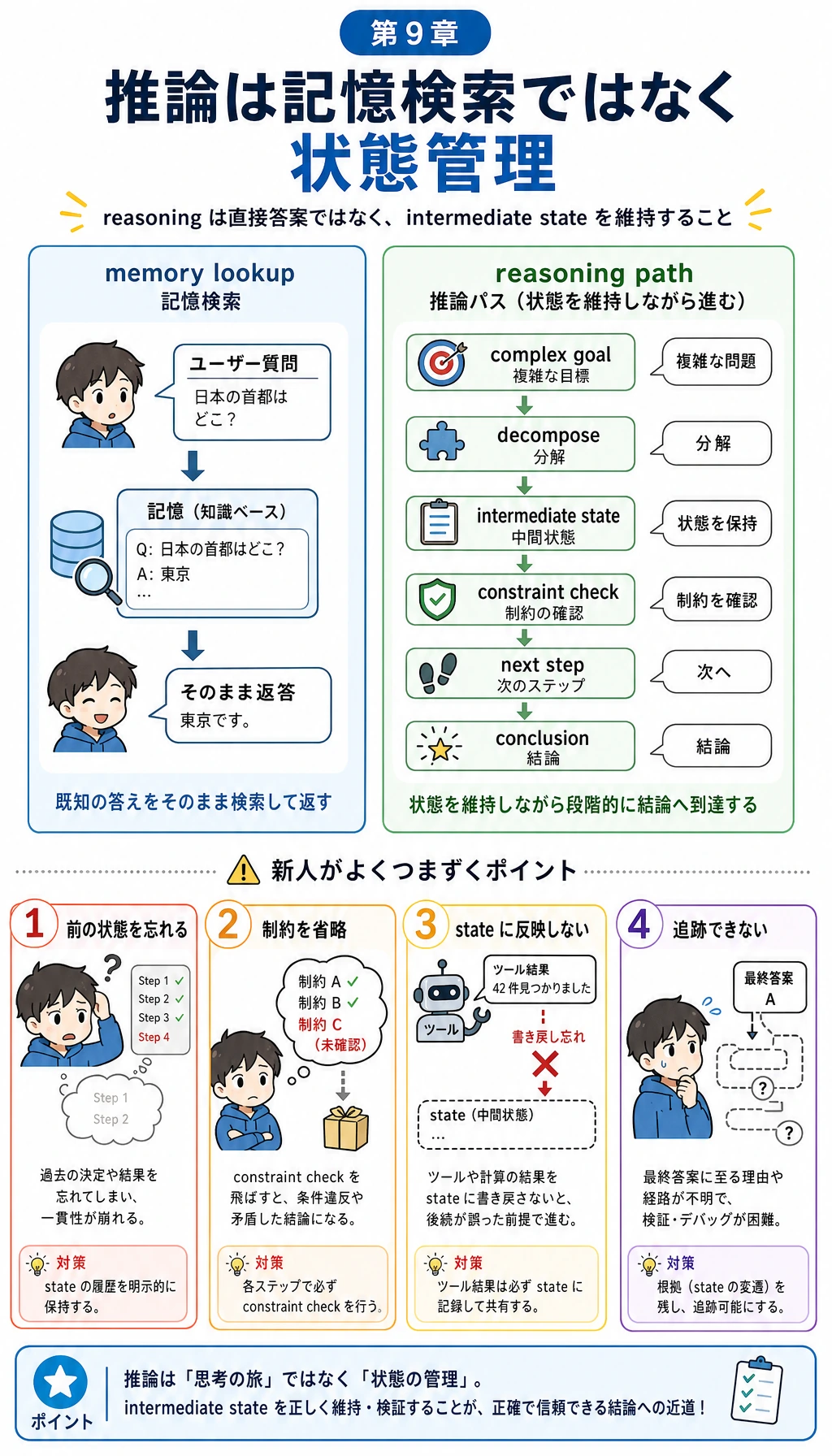
「推論」とは何か。「答えを覚える」ことと何が違うのか?
答えを覚える:脳内辞書を引くようなもの
もし私がこう聞いたら、
- フランスの首都はどこですか?
モデルは、学習済みの知識パターンを呼び出しているようなものです。
この種の問題は、次のものに近いです。
- 記憶
- 検索
- パターンマッチング
推論:答えが問題文にそのまま置かれていない
もし私がこう聞いたら、
3 * (4 + 2) - 5はいくつですか?
モデルは「この式を暗記していた」だけでは足りません。
次の処理が必要です。
- まず括弧を計算する
- 次に掛け算をする
- 最後に引き算をする
つまり、
推論問題のポイントは、元の問題を見たことがあるかではなく、正しい中間状態の連鎖を維持できるかどうかです。
初めて推論を学ぶとき、まず何をつかむべきか?
まずつかむべきなのは専門用語ではなく、この一文です。
推論で本当に難しいのは最後の答えではなく、中間ステップをずっと正しく保てるかどうかです。
この感覚がつかめると、後で次のものを見るときに、
- Chain-of-Thought
- ReAct
- Plan-and-Execute
それらを「モデルが中間状態の連鎖を守るのを助ける仕組み」として、自然に理解できるようになります。
たとえ話:推論は料理であって、料理名を唱えることではない
「宮保鶏丁が何かを知っている」は知識に近いです。
「鶏肉を下味に漬ける → 香りを立たせる → タレを作る → 煮詰める」は推論に近いです。
そこではシステムに次のことが求められます。
- 順序を知っている
- 中間結果を覚えている
- 手順を飛ばさない
LLM の推論でよく出る問題はどの 3 種類か?
算術と記号推論
例えば、
- 多段の四則演算
- 日付や時刻の計算
- 単位変換
この種の問題の特徴は、
- 結論はステップによって決まる
- 1 ステップでも間違えると、その後全部ずれる
制約充足と比較・意思決定
例えば、
- 予算、時間、在庫の制約の下で案を選ぶ
- シフト作成
- ルート計画
この種の問題は、必ずしも単なる計算ではありません。
より重要なのは、
- 複数条件が同時に成り立つこと
- 中間判断同士が矛盾しないこと
ツール呼び出しの前後で状態を統合すること
これは Agent の場面で最もよくある種類です。
例えば、
- まず天気を調べる
- 次にフライトを調べる
- 最後に振り替えするか決める
ツールは外部情報を返してくれます。
でも、その情報をまとめて結論にするには、やはり推論が必要です。
なぜこの 3 種類は、Agent 入門として学ぶのに向いているのか?
どれも「調べたら終わり」の問題ではなく、次のことが必要だからです。
- まずステップに分解する
- 中間結果を保存する
- 外部から得た観察結果を再統合する
まさにこれが、Agent の推論層の中心的な仕事です。
まずは「中間状態」がよく分かる例を動かしてみる
以下のコードは、ある式を構文木に変換し、
その後に再帰的に評価して、各計算ステップを記録します。
LLM そのものを再現しているわけではありません。
ただし、次の非常に大事な感覚を身につける助けになります。
多段問題の核心は最後の答えではなく、中間状態がどう正しく受け渡されるかです。
import ast
import operator
OPS = {
ast.Add: ("+", operator.add),
ast.Sub: ("-", operator.sub),
ast.Mult: ("*", operator.mul),
ast.Div: ("/", operator.truediv),
}
def solve(node):
if isinstance(node, ast.Constant):
return node.value, []
if isinstance(node, ast.BinOp):
left_value, left_steps = solve(node.left)
right_value, right_steps = solve(node.right)
symbol, fn = OPS[type(node.op)]
result = fn(left_value, right_value)
step = f"{left_value} {symbol} {right_value} = {result}"
return result, left_steps + right_steps + [step]
raise TypeError(f"Unsupported node: {type(node)}")
expression = "3 * (4 + 2) - 5"
tree = ast.parse(expression, mode="eval").body
answer, steps = solve(tree)
print("expression:", expression)
print("steps:")
for step in steps:
print("-", step)
print("answer:", answer)
期待される出力:
expression: 3 * (4 + 2) - 5
steps:
- 4 + 2 = 6
- 3 * 6 = 18
- 18 - 5 = 13
answer: 13
このコードで本当に学ぶべきなのは ast ではない
本当に持ち帰るべきなのは次の点です。
- 各ステップで明確な中間結果が生まれる
- 次のステップは前のステップに依存する
- 最終回答は、最後の状態にすぎない
これは LLM が複雑な推論をするときの姿にとてもよく似ています。
なぜ中間状態は「最終回答」より大事なのか?
中間のどこかで計算を間違えると、
たまたま最後が合っていても、安定して再現するのは難しくなります。
推論システムが本当に目指すべきなのは、
- 途中経過が信頼できること
- どこで間違えたかを特定できること
であって、偶然当たることではありません。
なぜ Agent はこの能力に特に依存するのか?
Agent が扱う問題は、普通 1 ステップでは終わりません。
たとえば次のような流れが必要です。
- まず要件を読む
- 次にデータを調べる
- 次に制約を比較する
- 最後に行動を選ぶ
これは本質的に、より長い中間状態の連鎖を保っているのと同じです。
なぜこのコードは「最後の答えが合っている」より教育的なのか?
なぜなら、これによって次のことがはっきり見えるからです。
- 各ステップがどのように生まれるか
- 次のステップは何に依存しているか
- どこから誤りが伝播するのか
そして Agent システムで本当に必要なのも、まさにこの性質です。
- 途中経過が読める
- 中間状態を確認できる
- エラーの位置を特定できる
LLM の推論は、なぜ強いときと急に崩れるときがあるのか?
パターン化された段階的構造は得意
タスクを比較的はっきりしたステップに組み立てられるなら、
LLM はしばしば良い結果を出します。たとえば、
- 問題を分解する
- 理由を説明する
- 候補案を生成する
長い連鎖ではずれやすい
よくある問題は次のとおりです。
- ステップを飛ばす
- 同じステップを繰り返す
- 中間の数字を間違える
- 前後の制約が矛盾する
つまり、
LLM の推論能力は「安定した論理エンジン」ではなく、
どちらかというと次のようなものです。
- ステップの下書きをうまく作る言語推論器
だから複雑なタスクでは外部ツールと組み合わせる
例えば、
- 正確な数値計算には電卓を使う
- 現在の状態を調べるにはデータベースを使う
- 制約の衝突をチェックするにはルールエンジンを使う
Agent の推論層は、単独で働くことが多いわけではなく、
ツールと協力して動きます。
なぜ「推論できる」と「会話がうまい」はまったく別なのか?
会話は次のようなものだからです。
- 文章がなめらか
- 文体が自然
一方、推論は次のようなものです。
- ステップが正しい
- 制約がぶつからない
- 中間状態が安定している
だから、「よく話せる」モデルでも、複雑な多段タスクでは崩れることがあるのです。
いつ「より強い推論モード」を使うべきか?
答えに多段の導出が必要なとき
問題そのものが明らかに次を必要とするなら、
- 段階的な計算
- 順序に沿った判断
- 条件の絞り込み
より明示的な推論戦略を使う価値があります。
間違いのコストが高いとき
例えば、
- 財務計算
- 設定変更
- 医療判断の補助
このような場面では、
「それっぽい」だけでは足りません。
より重要なのは、
- 途中経過を検証できること
です。
問題が外部観察結果に依存するとき
例えば、
- 在庫を確認してから発注案を出す
- フライトを見てから変更判断をする
この場合、推論はツールによる観察と結びつく必要があります。
よくある誤解
誤解 1: モデルが大きければ、自然に推論できる
モデルが大きいほど上限は上がりやすいですが、
複雑な推論がすべて安定するわけではありません。
誤解 2: 推論とは、手順を長く書けばよいだけ
違います。
本当に有効な推論とは、次のようなものです。
- ステップ同士に依存関係がある
- 中間状態を再利用できる
- 最終回答が過程によって支えられている
誤解 3: ツールがあれば推論は不要
ツールは外部の能力を提供するだけです。
次のことを決めるのは、やはり推論です。
- いつ呼び出すか
- 何を呼び出すか
- 結果をどう統合するか
まとめ
この節で最も大事なのは、「推論」を神秘化することではなく、まずはっきりした判断基準を持つことです。
LLM の推論能力の本質は、多段問題の中で正しい中間状態を維持し、外部情報、制約条件、局所的な結果を統合して最終結論にまとめることです。
この見方が固まれば、
その後に学ぶ次のものも、
- CoT
- ReAct
- Plan-and-Execute
それらはすべて、モデルがこの仕事をより安定してこなせるようにする仕組みだと分かります。
この節で必ず持ち帰りたいこと
- 推論とは「答えを長く書くこと」ではなく、正しい中間状態の連鎖を保つこと
- Agent に推論が必要なのは、多くのタスクが 1 ステップで終わらないから
- ツールは能力を提供し、推論はその能力と結果を組み立てる
練習
- 例の式を
12 / (3 + 1) + 7に変えて、ステップ出力が予想どおりか確認してみましょう。 - 自分の言葉で説明してみましょう。なぜ推論問題のポイントは「最終回答」ではなく「中間状態」にあるのでしょうか?
- 自分が行った Agent タスクを 1 つ思い出し、その中で前のステップの結果に明確に依存している箇所を 2 つ以上見つけてみましょう。
- なぜ「ツールがある」ことは「推論できる」ことと同じではないのでしょうか?