8.2.2 ローカルモデルの実行
大規模モデルのアプリで、いちばん思いつきやすい方法は次のものです。
- そのままクラウド API を呼ぶ
でも、実際のプロジェクトではすぐに次の問題にぶつかります。
- コスト
- 遅延
- データ安全性
- ネットワーク依存
そのため、「ローカルモデルは動かせるのか、動かす価値はあるのか」が、とても現実的な問題になります。
学習目標
- なぜ多くの場面でローカルモデルが優先されるのかを理解する
- モデルサイズ、量子化、ハードウェア条件の関係を理解する
- CPU 実行、GPU 実行、量子化実行の基本的な違いを区別する
- 最小限のローカル推論フローを読み取れるようになる
- 「いつローカルで動かすべきか、いつ API のほうが向いているか」を判断できるようになる
まずは地図を作ろう
ローカルモデルのこの節で、初心者にいちばん合う理解順は「先にモデル名を選ぶ」ことではなく、まず次をはっきり見ることです。
つまり、この節で本当に解決したいのは次のことです。
- なぜ、すぐ使える API があるのにローカルで動かす人がいるのか
- ローカルで動かすことで、何を交換しているのか
初心者向けの、もっと分かりやすいたとえ
クラウド API とローカルモデルは、次の関係として考えられます。
- タクシー
- 自分で車を持つ
タクシーのよさは:
- 手間が少ない
- いつでも呼びやすい
自分の車のよさは:
- よりコントロールしやすい
- 長期的には安くなることがある
- 場合によってはより安全
でも、その代わりに自分で負う必要があるものもあります。
- メンテナンス
- 駐車
- 故障対応
ローカルモデルとクラウド API の関係も、まさにこうしたトレードオフです。
一、なぜローカルモデルを考えるのか?
まずはクラウド API のよさを見る
クラウド API の強みはとても分かりやすいです。
- すぐ使える
- モデルの性能が高いことが多い
- 運用の負担が小さい
そのため、多くのプロジェクトの立ち上げでは、クラウド API がいちばん楽な選択肢になりやすいです。
それでもローカルで動かしたいのはなぜ?
よくある理由は次のとおりです。
- データをローカルや企業内ネットワークの外に出せない
- API のコストがすぐ膨らむ
- オフラインでも使いたい
- モデルや推論の流れをより細かく制御したい
つまり、ローカルモデルの本当の価値は「より高級」ということではなく、
品質、コスト、プライバシー、制御性の間で、別のトレードオフを取り直せること
にあります。
二、いちばん大事な現実感覚を持とう:モデルサイズは抽象的な数字ではない
パラメータ数は、そのままリソース消費に影響する
モデルが次のような表記のとき、
- 7B
- 13B
- 70B
これはただの宣伝文句ではなく、たいてい次の意味を持ちます。
- メモリ / VRAM の使用量がかなり違う
- 読み込み時間がかなり違う
- 推論速度もかなり違う
おおまかなリソースのイメージ
runtime_options = [
{"name": "small_quantized_model", "memory_gb": 4, "quality": "basic"},
{"name": "medium_quantized_model", "memory_gb": 8, "quality": "good"},
{"name": "larger_model", "memory_gb": 16, "quality": "better"}
]
for item in runtime_options:
print(item)
期待される出力:
{'name': 'small_quantized_model', 'memory_gb': 4, 'quality': 'basic'}
{'name': 'medium_quantized_model', 'memory_gb': 8, 'quality': 'good'}
{'name': 'larger_model', 'memory_gb': 16, 'quality': 'better'}
このコードは本当は何を伝えているのか?
数字を覚えてほしいのではありません。
まず、とても実用的な判断軸を持ってほしいのです。
モデルがローカルで動くかどうかは、最初にリソースの条件が合うかで決まることが多い。
つまり、「動かしたいか」よりも「そのマシンで耐えられるか」が先です。
初学者がまず覚えやすい意思決定表
| いちばん重視するもの | まず優先しやすい選択肢 |
|---|---|
| 素早い試作 | クラウド API |
| プライバシーと社内ネットワーク | ローカルモデル |
| 長期コスト | ローカルモデルまたはハイブリッド構成 |
| 最高の性能 | まずはクラウド API を試すことが多い |
この表は絶対ルールではありませんが、初心者が現実的に考える助けになります。
- デプロイ方法は、まず業務判断であって、単なる技術の好みではない
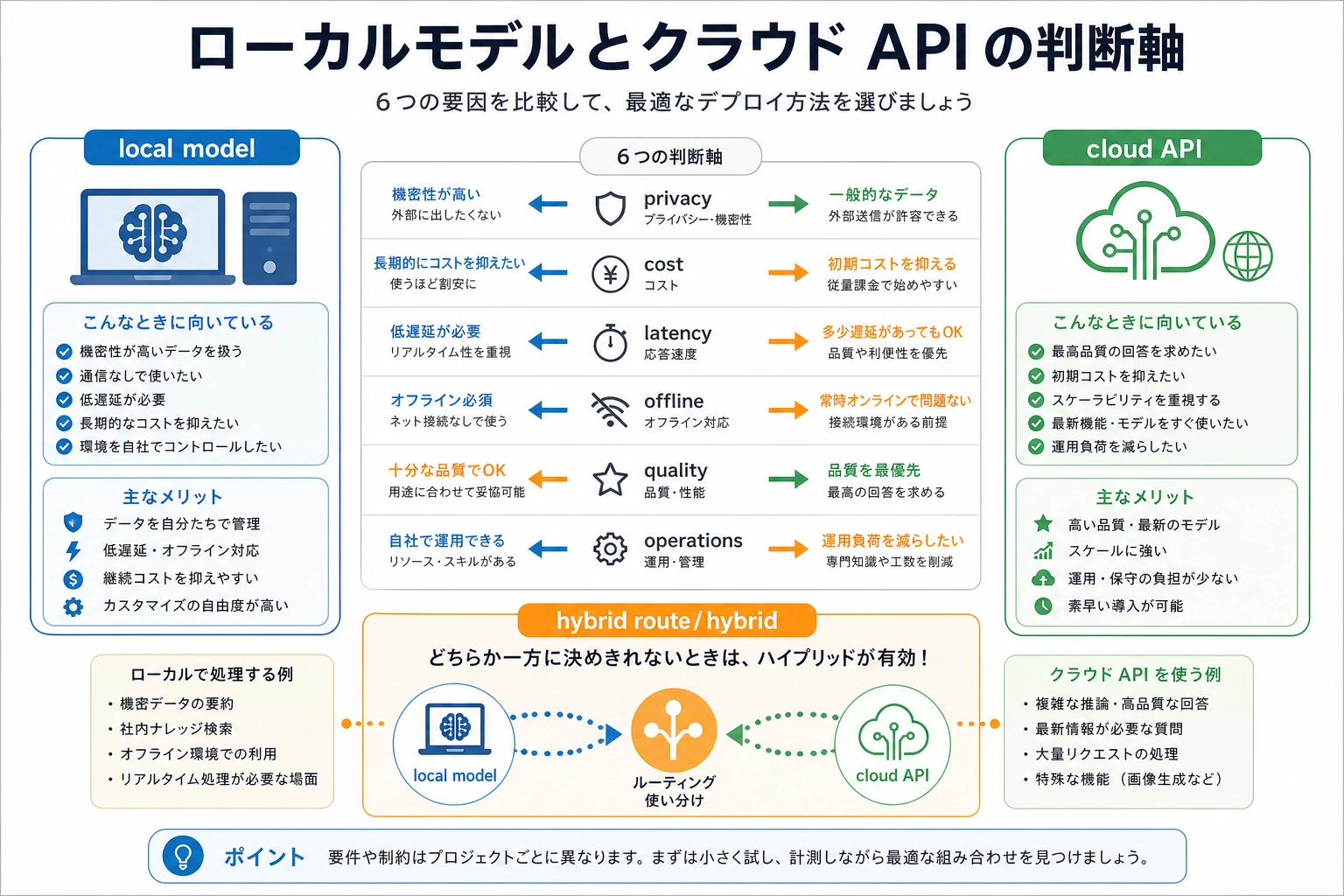
図を見るときは、「どのモデルが強いか」から考えないでください。まず見るべきなのは、プライバシー、コスト、遅延、オフライン対応、運用能力です。多くのデプロイ判断は、モデル性能の比較ではなく、業務上の制約の順番で決まります。
三、なぜ量子化はローカルモデルと一緒に語られるのか?
みんな、より小さなマシンにモデルを載せたいから
量子化をいちばんざっくり、でも分かりやすく言うとこうです。
モデルのパラメータをより低い精度で表現して、メモリ使用量を減らすこと。
最小限のイメージ
params = 7_000_000_000 # 70億パラメータ、イメージ
precisions = {
"fp16": 2.0,
"int8": 1.0,
"int4": 0.5
}
for name, bytes_per_param in precisions.items():
memory_gb = params * bytes_per_param / (1024 ** 3)
print(name, "rough memory GB =", round(memory_gb, 2))
期待される出力:
fp16 rough memory GB = 13.04
int8 rough memory GB = 6.52
int4 rough memory GB = 3.26
これはパラメータ分のメモリだけを見た、とても粗い見積もりです。実際の実行時には KV cache、一時バッファ、tokenizer/runtime のオーバーヘッド、サービス用キューなども加わります。
量子化の利点と代償
利点:
- ローカルで動かしやすくなる
- 端末や弱いマシンにも載せやすくなる
代償:
- 精度が少し落ちることがある
- タスクによっては影響を受けやすい
つまり、量子化も典型的なエンジニアリング上のトレードオフであって、ノーコストの魔法ではありません。
「リソースが足りないとき、どうするか」の最小例
constraints = {
"memory_gb": 8,
"need_low_latency": False,
"privacy_sensitive": True,
}
def suggest_runtime(constraints):
if constraints["privacy_sensitive"] and constraints["memory_gb"] <= 8:
return "小型の量子化ローカルモデルを優先して検討します。"
if constraints["need_low_latency"] and constraints["memory_gb"] >= 16:
return "GPU によるローカル推論を優先して検討します。"
return "まずはクラウド API で試作し、その後ローカル移行を検討します。"
print(suggest_runtime(constraints))
期待される出力:
小型の量子化ローカルモデルを優先して検討します。
この例は初学者にとても役立ちます。なぜなら、次のことを思い出させてくれるからです。
- ローカル導入では、まずモデル選びではない
- 先に見るべきなのは制約条件
四、CPU 実行と GPU 実行は何が違うのか?
CPU 実行の特徴
利点:
- ふつうのマシンならたいていある
- 導入のハードルが低い
欠点:
- 遅い
GPU 実行の特徴
利点:
- より速い
- 比較的大きなモデルに向いている
欠点:
- コストが高い
- 環境構築の要求が高い
実用的な判断
もし対象が次のようなものなら、
- 個人用ツール
- 小規模な試験運用
- オフラインアシスタント
小さなモデルを CPU で動かすだけでも十分なことがあります。
一方で、次のようなケースなら、
- 複数ターンの対話
- ユーザーの待ち時間に敏感
- モデルが少し大きい
GPU や、より専門的な runtime のほうが現実的です。
五、最小のローカル推論フローのイメージ
なぜ最初に mock runtime を使うのか?
ここでは本物の大規模モデルは使わず、mock runtime を書きます。目的は、「読み込み -> 推論 -> 返却」という流れをはっきり見ることです。
class LocalModelRuntime:
def __init__(self, model_name):
self.model_name = model_name
self.loaded = False
def load(self):
self.loaded = True
print(f"{self.model_name} を読み込みました")
def generate(self, prompt):
if not self.loaded:
raise RuntimeError("model not loaded")
return f"[{self.model_name}] {prompt} へのローカル応答"
runtime = LocalModelRuntime("small-local-model")
runtime.load()
print(runtime.generate("返品ポリシーは何ですか?"))
期待される出力:
small-local-model を読み込みました
[small-local-model] 返品ポリシーは何ですか? へのローカル応答
このコードは何を教えているのか?
ローカルモデルの基本は、次の 3 つです。
- まずモデルを読み込む
- 推論リクエストを runtime に通す
- 結果を上位システムに返す
見た目はとても簡単ですが、これはすでに本番の推論システムの最小構成にかなり近いです。
初学者が最初のプロジェクトで、どうやってローカル実行を選ぶか?
より安全な順番は、たいてい次のとおりです。
- まず本当にプライバシー、オフライン、コストの制約があるかを確認する
- 次に、今のマシンで本当に耐えられるかを見る
- ただの試作なら、まずはクラウド API を優先する
- 推論の流れを自分で制御したい、または長期的にコストを抑えたいなら、ローカルモデルをしっかり検討する
この順番のほうが、最初から「ローカルデプロイはかっこいい」と追いかけるよりずっと現実的です。
これをプロジェクトや提案資料にするなら、何を見せるべきか
特に見せる価値が高いのは、次のような点です。
- 「モデルを動かせた」こと
- なぜ API ではなくローカルを選んだのか
- ハードウェアとモデルサイズをどう合わせたのか
- 量子化を使ったかどうか
- コールドスタート、遅延、コストをどうトレードオフしたか
- この構成が向いている場面、向いていない場面はどこか
こうしておくと、見る人にも次が伝わります。
- 理解しているのはデプロイの判断
- 単に推論を 1 回通しただけではない
6、本当に難しいのは「生成に成功すること」ではなく、「長く安定して動かすこと」
実際のシステムになると、次のような現実的な問題が出てきます。
- コールドスタートにどれくらいかかるか
- 常駐するモデルがどれだけリソースを使うか
- 1 台のマシンでどれくらい同時処理できるか
- モデルを切り替えるたびに再読み込みが必要か
コールドスタートの問題
最初のモデル読み込みは、たいていかなり遅いです。
これはサービス型システムでは大きな問題になります。
常駐プロセスの問題
コールドスタートを減らすために、モデルをメモリに常駐させることがよくあります。
でもその代わりに、次の負担が増えます。
- 長期的なリソース占有が増える
つまり、こういうことです。
ローカルモデル実行の本当の難しさは、「1 回うまく動かすこと」ではなく、「サービスのように動き続けさせること」にある。
7、どんなときにローカルモデルは特に価値があるのか?
向いているケース
- 企業内ネットワーク
- プライバシーに敏感な内容
- API コストの圧力が大きい
- 電波が弱い / オフライン環境
- 推論の流れを強く制御したい
必ずしも向いていないケース
- チームに運用能力がない
- 仕事が最先端の大規模モデル性能に強く依存している
- ユーザー数が少なく、API でも十分に楽
この場合は、クラウドモデルのほうがむしろ向いていることがあります。
8、実用的な意思決定チェックリスト
ローカル実行を決める前に、次のことを考えてみましょう。
- いちばん大事なのはコスト、プライバシー、モデル品質のどれか?
- 十分なハードウェアがあるか?
- デプロイや保守の複雑さを引き受けられるか?
- そもそも API で十分に良い結果が出るのではないか?
この答えがはっきりすると、ローカルモデルの判断もかなりぶれにくくなります。
9、初心者がよくハマる落とし穴
モデルのパラメータ数だけ見て、runtime を見ない
同じモデルでも、runtime が変わると体験はかなり違います。
最初から大きいモデルを狙う
ローカルの多くの場面では、小さなモデルで十分なことがあります。
「動いた」ことを「本番に載せられる」と思ってしまう
本番ではさらに次の点が必要です。
- 安定性
- 監視
- 同時実行
- コスト
まとめ
この節でいちばん大切なのは、いくつかのモデル名を覚えることではなく、次のような安定した感覚を持つことです。
ローカルモデル実行の核心は、「品質、コスト、プライバシー、ハードウェア、保守の複雑さ」の間で現実的なトレードオフを取ること。
これはクラウド API の単なる代替ではなく、まったく別のデプロイ選択肢です。
練習
- 今の自分のマシン条件を使って、妥当だと思うローカルモデル実行の案を書いてみましょう。
- 自分の言葉で説明してみましょう。なぜ量子化はローカルモデル実行で頻繁に登場するのでしょうか?
- なぜ「モデルファイルを読み込める」ことと「モデルサービスを本番公開できる」ことは同じではないのでしょうか?
- もしシステムがかなりプライバシー重視で、でもチームの運用力が弱いなら、どう取捨選択しますか?