8.2.3 高性能推理サービス
前の節で扱ったのが:
- モデルをローカルで動かせるか
だとすると、この節で扱うのは、もっと現実的な一段階上の話です。
モデルが本番環境で安定してリクエストをさばけるか。
プロジェクトが demo から production に進むとき、最初に本当に壁にぶつかりやすいのも、ここです。
学習目標
- スループット、レイテンシ、バッチ処理、キューといった推理サービスのキーワードを理解する
- 「動く」ことと「サービスとして提供できる」ことは違うと理解する
- 最小構成のバッチ処理推理サービスの考え方を読み取れるようになる
- 推理サービス最適化の考え方の第一歩を身につける
まずは全体像をつかもう
推理サービスは、「リクエストがどう入ってきて、どう並び、どうまとめられ、どう返るか」で理解すると分かりやすいです。
この節で本当に解決したいのは、次の2つです。
- なぜモデルを1回動かせることと、サービスとして運用できることはまったく別なのか
- なぜ推理サービスは本質的に、キュー、バッチ、リソース配分の問題なのか
一、なぜローカル推論と推理サービスは別物なのか?
ローカル推論で気にするのは「結果が出るか」
たとえば:
- 1つの prompt に答えられるか
- 1枚の画像を生成できるか
推理サービスで気にするのは「同時にどれだけのリクエストをさばけるか」
一度本番に出すと、相手はこうなります。
- 複数のリクエストが同時に来る
- 流量が急に増える
- 使えるリソースに限りがある
- タイムアウトがある
だから推理サービスの核心はこうなります。
限られたリソースの中で、速度とスループットをどう両立するか。
初学者向けの分かりやすい比喩
推理サービスは、こんなものだと考えるとイメージしやすいです。
- 飲食店の厨房で料理を出すこと
ローカル推論は、もっとこうです。
- 自分で家で1食作って、ちゃんと作れるかを見ること
推理サービスは、もっとこうです。
- 昼のピークに注文が一気に入る
- 厨房がどう順番を決めるか
- どうまとめて作るか
- どうすればお客さんを長く待たせないか
この比喩は初心者にとても役立ちます。なぜなら、推理サービスの本質が
- 流量をどうさばくか
という問題だとつかみやすくなるからです。
二、まず最重要の2つの用語を分けよう
Latency
1回のリクエストにどれくらい待つか。
Throughput
単位時間あたりにどれくらいのリクエストを処理できるか。
この2つは、たいてい引き合います。
たとえば:
- batch を大きくすると、スループットは上がりやすい
- でも、1件あたりの待ち時間は長くなることがある
つまり推理サービスは、「どれか1つだけ高ければよい」のではなく、バランスの問題です。
三、なぜバッチ処理(batching)がとても重要なのか?
直感的にいうと
8件のリクエストがほぼ同時に来たら、次の2通りがあります。
- 1件ずつ別々に実行する
- まとめて1つの batch として実行する
後者のほうが、ハードウェアをより効率よく使えることが多いです。
最小のイメージ
requests = [12, 8, 15]
batch_size = 8
for r in requests:
num_batches = (r + batch_size - 1) // batch_size
print("必要な batch 数:", num_batches)
期待される出力:
必要な batch 数: 2
必要な batch 数: 1
必要な batch 数: 2
ここでの requests は、分かりやすくした作業量のリストです。大事なのは切り上げ計算で、作業量が batch size を超えると、サービス層は複数回のモデル実行に分ける必要があります。
このコードは何を教えているのか?
このコードが教えているのは、
推理サービスは「1つのリクエスト」だけで考えるのではなく、「キューと batch」で考える
ということです。
初学者がまず覚えておくとよい見分け表
| 現象 | まず見るべき層 |
|---|---|
| 1件の処理は速いのに、全体ではさばききれない | スループットとバッチ処理 |
| 応答が遅いのに、GPU が遊んでいる | キューと batch の組み方 |
| リクエストが増えると急にタイムアウトする | キュー長と並行処理の制御 |
| 単体 benchmark は良いのに、本番では悪い | モデル本体よりサービス層のスケジューリング |
この表は初心者にとても役立ちます。なぜなら、「推理サービスが遅い」という曖昧な話を、具体的な切り分けポイントに分解してくれるからです。
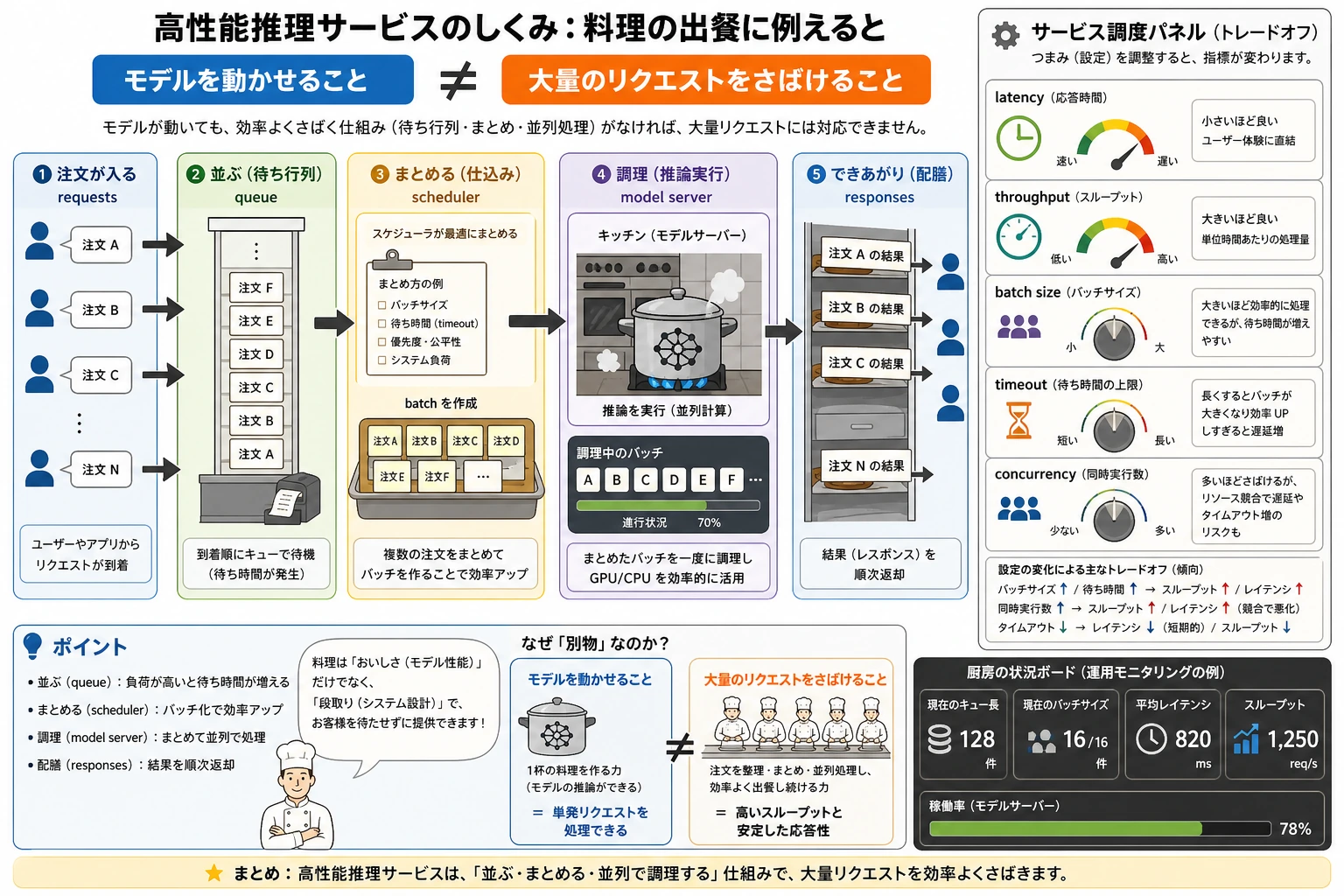
リクエストは直接モデルに飛び込むのではなく、まずキューに並び、そのあと batch にまとめられ、最後に実行されます。batch はスループットを上げますが、待ち時間も増やし得るので、サービス化の調整はいつも latency と throughput のバランス取りになります。
四、なぜキューが高性能サービスの基本部品なのか?
なぜなら、リクエストはきれいには来ないから
実際の流量は、たいてい次のようになります。
- 山がある
- 谷がある
- 突発的に増える
キューがないと、システムは簡単に:
- 突然落ちる
- リクエストをそのまま取りこぼす
ことになります。
最小のキューの例
from collections import deque
queue = deque(["req1", "req2", "req3", "req4", "req5"])
batch_size = 2
while queue:
batch = []
for _ in range(min(batch_size, len(queue))):
batch.append(queue.popleft())
print("batch を実行:", batch)
期待される出力:
batch を実行: ['req1', 'req2']
batch を実行: ['req3', 'req4']
batch を実行: ['req5']
この例はとてもシンプルですが、すでに次のことを示しています。
- リクエストはまずキューに入る
- そのあと batch ごとに実行される
これが、多くの推理サービスの基本的な動きです。
五、並行処理とバッチ処理は同じではない
これは、初学者がいちばん混同しやすいところです。
並行処理
複数のリクエストが、システムの中で同時に進むこと。
バッチ処理
複数のリクエストを、モデル側で1つの batch にまとめて計算すること。
つまり、こう覚えるとよいです。
- 並行処理はスケジューリングの問題
- バッチ処理はモデル実行の問題
この2つはしばしば一緒に現れますが、同じ意味ではありません。
六、最小の推理サービスのメインループ
from collections import deque
queue = deque(["q1", "q2", "q3", "q4"])
batch_size = 2
def run_model(batch):
return [f"{item}_の回答" for item in batch]
while queue:
batch = []
for _ in range(min(batch_size, len(queue))):
batch.append(queue.popleft())
results = run_model(batch)
for item, result in zip(batch, results):
print(item, "->", result)
期待される出力:
q1 -> q1_の回答
q2 -> q2_の回答
q3 -> q3_の回答
q4 -> q4_の回答
このコードが重要な理由
このコードには、高性能推理サービスの最も重要な骨組みがすでに入っています。
- 入隊
- バッチ化
- 推論
- 結果の返却
この流れこそが、「サービス」の本体です。
初めて推理サービスを作るときの、いちばん安定した順番
一般に、次の順番のほうが安定して進めやすいです。
- まず 1件のリクエストを安定して返せるようにする
- 次にキューを入れる
- そのあと batch 化する
- 最後に batch サイズとリソース利用率を調整する
最初から最大スループットを狙うより、この順番のほうがシステムを安定させやすいです。
七、なぜ高性能推理サービスは常にバランス調整なのか?
実際には、次のようなトレードオフがあります。
- batch を大きくすると、スループットは上がりやすい
- batch を小さくすると、応答は速くなりやすい
- モデルを常駐させると速いが、リソースを多く使う
- インスタンス数を増やすと安定しやすいが、コストが上がる
つまり、
推理サービスの最適化は、絶対値を上げることではなく、業務上の制約の中でバランスを取ること。
八、本番サービスで特に見るべき指標
少なくとも、次の指標はよく見ます。
- 平均レイテンシ
- P95 / P99 レイテンシ
- キュー長
- batch 利用率
- エラー率
- GPU / CPU 利用率
これらの指標を見ると、今のボトルネックが
- リクエスト側にあるのか
- batch の組み方にあるのか
- モデル実行側にあるのか
が分かりやすくなります。
初学者がまず覚えるとよい監視表
| 指標 | まず何を知るのに役立つか |
|---|---|
| 平均 / P95 レイテンシ | ユーザーが実際にどれくらい待ったか |
| キュー長 | リクエストがたまっているか |
| batch 利用率 | ハードウェアをしっかり使えているか |
| GPU / CPU 利用率 | ボトルネックがモデル実行にあるか、それ以外か |
この表も初心者に向いています。なぜなら、「監視項目が多い」という状態を、もっと直感的な問いに変えてくれるからです。
九、よくある誤解
単発の推論 benchmark だけを見る
本番で本当に大事なのは、全体の流量の中でどう動くかです。
最初から batch を大きくしすぎる
スループットは上がるかもしれませんが、レイテンシが悪化することがあります。
モデルを動かせるだけで満足する
キューやリソース利用率を見られないと、どこが本当のボトルネックか分かりにくくなります。
まとめ
この節でいちばん大事なのは、ある推理サービス用語を1つ覚えることではなく、次の理解です。
高性能推理サービスの核心は、モデル呼び出しを「単発の実行」から「実際の流量の中で、スループット・レイテンシ・リソース使用をバランスさせるシステム」に変えること。
これが、「ローカルでモデルを動かす」ことと本質的にまったく違う点です。
これをプロジェクトやシステム設計として見せるなら、何を見せるべきか
特に見せる価値が高いのは、次のような点です。
- リクエストをどうキューイングし、どう batch 化するか
- スループットとレイテンシをどう両立させているか
- 本番で重要な監視指標は何か
- どのときにボトルネックがキューにあり、どのときにモデル実行にあるか
こうすると、相手には次のことが伝わりやすくなります。
- ただモデルを呼べるだけではない
- サービスとしての推論を理解している
練習
- 自分の言葉で説明してみましょう:なぜ batching と concurrency は同じではないのか?
- 考えてみましょう:あなたのプロダクトが非常に低いレイテンシを求めるなら、大きい batch と小さい batch のどちらを選びやすいですか?
- 最小構成の推理サービス監視項目リストを設計してみましょう。
- なぜ推理サービスの本当の難しさは「どれか1つを極めること」ではなく、「バランスを取ること」だと言えるのでしょうか?