8.1.4 ベクトルデータベース
学習目標
この節を終えると、次のことができるようになります。
- RAG でベクトルデータベースがよく使われる理由を理解する
- 「ベクトル」「メタデータ」「類似度検索」の関係を整理する
- 最小限で動くベクトル検索の例を実行する
- ベクトルデータベースを選ぶときに注目すべき観点を知る
一、なぜ普通のデータベースでは不十分なのか?
RAG で探したいのは「完全一致」ではなく「意味が近いもの」
従来のデータベースが得意なのは次のような処理です。
- 完全一致
- 条件での絞り込み
- リレーションの検索
でも RAG でよくある問題は、次のようなものです。
ユーザーが 1 文で質問したとき、システムは「意味が最も近い」文章を見つける必要がある。
たとえば、ユーザーがこう質問したとします。
「どうやって受講をキャンセルしますか?」
知識ベースには次のように書かれているかもしれません。
「コース購入後 7 日以内であれば返金を申請できます」
この 2 つは文字通りには同じではありませんが、意味は関連しています。
これがベクトル検索の得意な場面です。
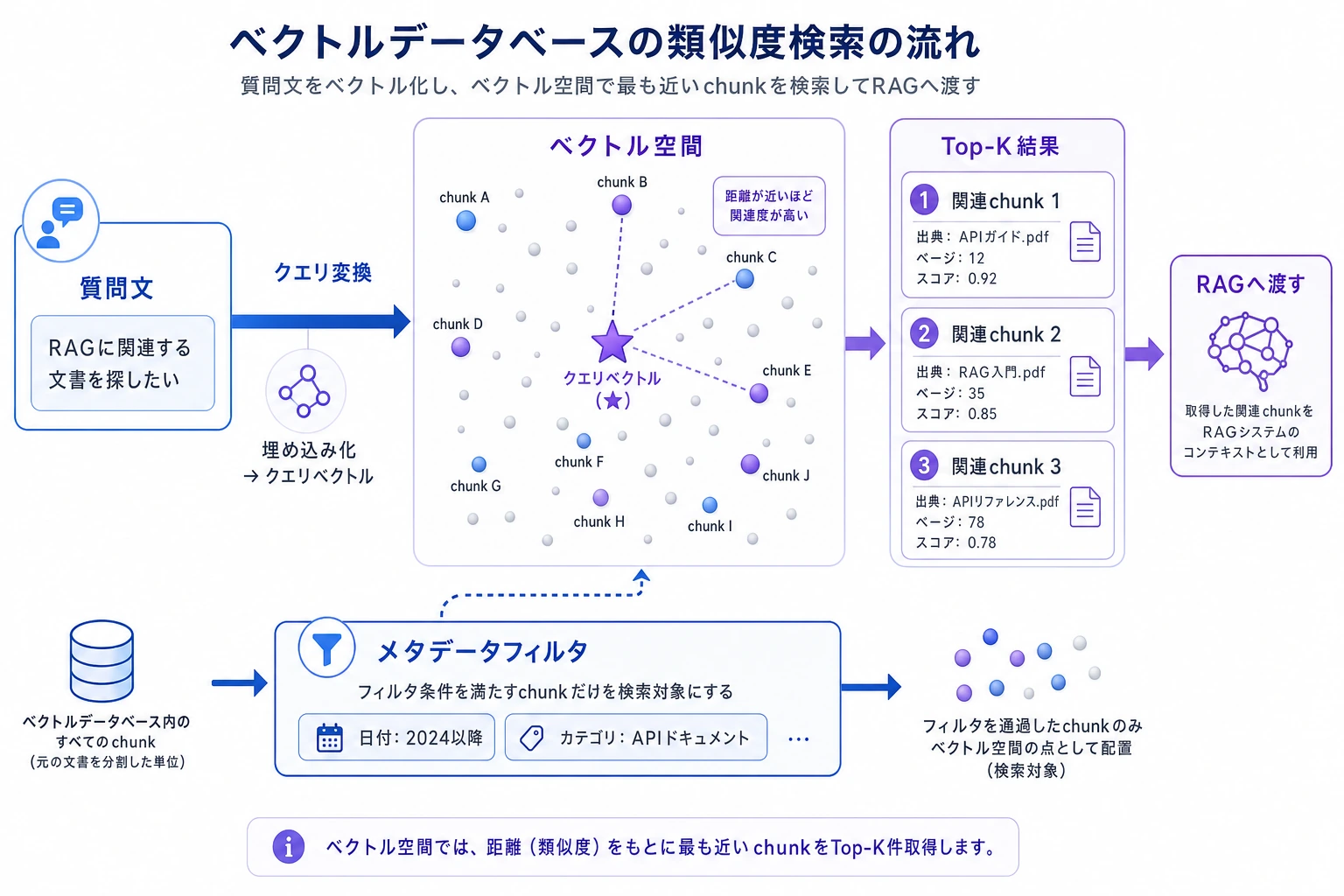
ベクトルデータベースは本質的に「意味の座標」を管理している
各テキストの embedding は、座標の集まりのように考えられます。
ベクトルデータベースの役割は、次の通りです。
- こうした座標を保存する
- ユーザーの検索時に、質問も座標に変換する
- その座標に近い点を探す
二、ベクトルデータベースには通常何を保存するのか?
ベクトルだけではなく、テキストやメタデータも保存する
1 件のレコードには、通常少なくとも次のような情報が含まれます。
idvectortextmetadata
たとえば、次のように書けます。
record = {
"id": "doc_001",
"vector": [0.2, 0.8, 0.1],
"text": "コース購入後 7 日以内であれば返金を申請できます",
"metadata": {"section": "返金ポリシー", "source": "policy.pdf"}
}
print(record)
なぜメタデータが重要なのか?
なぜなら、多くの場合は「意味が近い」だけでなく、「業務上の条件も満たしたい」からです。
たとえば、次のような条件です。
section=返金ポリシーのみを検索する- 特定の製品バージョンだけを対象にする
- 特定の部門の文書だけを検索する
つまり、ベクトルデータベースは「ベクトルだけ」を扱うのではなく、「ベクトル + テキスト + メタデータ」を組み合わせて管理します。

vector の列だけを見ないようにしましょう。実際の RAG では、text がモデルへの根拠になり、metadata がフィルタ、権限、引用、評価を支えます。どれか 1 つでも欠けると、システムのデバッグが難しくなります。
三、最小限で動くベクトル検索器
ここでは numpy を使って、原理が見えるミニベクトルデータベースを手作りしてみます。
import numpy as np
records = [
{
"id": "r1",
"vector": np.array([0.95, 0.05, 0.10]),
"text": "コース購入後 7 日以内であれば返金を申請できます",
"metadata": {"section": "返金ポリシー"}
},
{
"id": "r2",
"vector": np.array([0.10, 0.95, 0.05]),
"text": "コース修了プロジェクトを完了すると証明書を取得できます",
"metadata": {"section": "証明書の説明"}
},
{
"id": "r3",
"vector": np.array([0.20, 0.80, 0.15]),
"text": "修了テストに合格するとシステムが証明書を発行します",
"metadata": {"section": "証明書の説明"}
}
]
query_vector = np.array([0.90, 0.10, 0.10])
def cosine_similarity(a, b):
return float(np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b)))
results = []
for item in records:
score = cosine_similarity(query_vector, item["vector"])
results.append((score, item["id"], item["text"]))
for score, rid, text in sorted(results, reverse=True):
print(rid, round(score, 4), text)
期待される出力:
r1 0.9983 コース購入後 7 日以内であれば返金を申請できます
r3 0.3601 修了テストに合格するとシステムが証明書を発行します
r2 0.218 コース修了プロジェクトを完了すると証明書を取得できます
ここでの query_vector は、「ユーザーの質問の embedding」と考えてください。
四、メタデータフィルタを追加する
なぜフィルタはよく使うのか?
企業の知識ベースは、ただ何でも一気に検索するものではなく、境界を持って使うことが多いからです。
たとえば、次のような条件です。
- HR ポリシーだけを検索する
- 特定の製品ドキュメントだけを検索する
- 2025 年以降のバージョンだけを検索する
実行できる例
import numpy as np
records = [
{
"id": "r1",
"vector": np.array([0.95, 0.05, 0.10]),
"text": "コース購入後 7 日以内であれば返金を申請できます",
"metadata": {"section": "返金ポリシー"}
},
{
"id": "r2",
"vector": np.array([0.10, 0.95, 0.05]),
"text": "コース修了プロジェクトを完了すると証明書を取得できます",
"metadata": {"section": "証明書の説明"}
},
{
"id": "r3",
"vector": np.array([0.20, 0.80, 0.15]),
"text": "修了テストに合格するとシステムが証明書を発行します",
"metadata": {"section": "証明書の説明"}
}
]
query_vector = np.array([0.15, 0.90, 0.10])
def cosine_similarity(a, b):
return float(np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b)))
target_section = "証明書の説明"
filtered_results = []
for item in records:
if item["metadata"]["section"] != target_section:
continue
score = cosine_similarity(query_vector, item["vector"])
filtered_results.append((score, item["text"]))
for score, text in sorted(filtered_results, reverse=True):
print(round(score, 4), "->", text)
期待される出力:
0.9966 -> コース修了プロジェクトを完了すると証明書を取得できます
0.9944 -> 修了テストに合格するとシステムが証明書を発行します
これが「類似度検索 + 業務フィルタ」の最小形です。
五、目標が「知識ベース駆動の教材生成アシスタント」なら、メタデータには最低でも何を持たせるべきか?
この種のプロジェクトでは、ベクトルデータベースは単に「意味が近いものを探す」ためだけではありません。
その後の処理を支えるためにも使われます。
- テーマごとに絞る
- 概念 / 例題 / 練習問題で絞る
- 内部資料 / 外部資料で絞る
- 最後に出典をたどれるようにする
そのため、初心者向けの最小メタデータセットは、通常次のようになります。
| フィールド | 何を助けるか |
|---|---|
topic | 現在のテーマへのルーティング |
content_type | 概念 / 例題 / 練習問題を区別する |
source_origin | 内部資料 / 外部資料を区別する |
page_or_slide | 生成時の出典として使う |
grade | 対象学年や対象者を絞る |
小さなレコードは、次のように書けます。
record = {
"id": "doc_001_chunk_03",
"text": "商品の元値が 100 円で、2 割引きした後の価格はいくらですか?",
"metadata": {
"topic": "割引の文章題",
"content_type": "example",
"source_origin": "internal",
"page_or_slide": 3,
"grade": "小学高学年",
},
}
print(record)
この例で、初心者が特に気をつけるべき点は次の通りです。
- ベクトルストアのこの層が、後の教材を安定して組み立てられるかどうかを実は左右している
六、厳密検索と近似検索の違いは何か?
厳密検索
検索クエリのベクトルを、すべてのベクトルと 1 つずつ比較します。
利点:
- 結果が正確
欠点:
- データ量が大きいと遅い
近似最近傍(ANN)
実際のベクトルデータベースでは、検索を速くするために近似手法がよく使われます。
これは次のように考えるとわかりやすいです。
すべてを地道に 1 件ずつ比べるのではなく、まず候補を素早く絞ってから近いものを探す。
利点:
- 速い
代償:
- 絶対に最適とは限らないが、たいていは十分良い
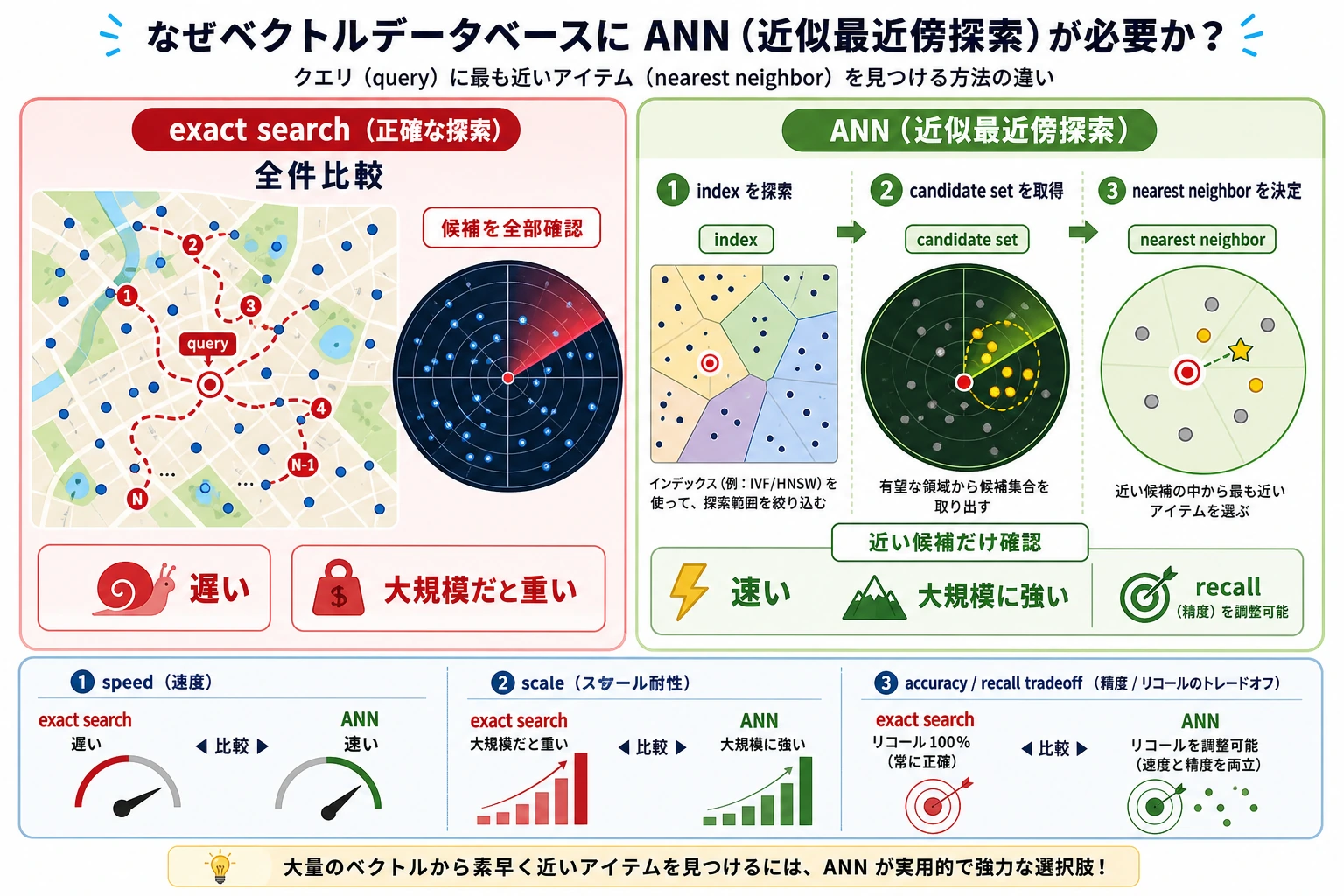
厳密検索はクラス全員を 1 人ずつ比べるようなもの、ANN はまずエリアで候補を絞ってから近所を探すようなものです。初心者はまず 1 つ覚えましょう。ANN は「絶対最適の保証」を少し犠牲にして、大規模検索の速度を得ます。
七、よくあるベクトルデータベース / ツールの役割
軽量なローカル方式
次のような用途に向いています。
- 学習
- プロトタイプ検証
- 小規模プロジェクト
よく使われるもの:
- FAISS
- Chroma
- SQLite + ベクトル拡張
より完成度の高いサービス型方式
次のような用途に向いています。
- マルチユーザーシステム
- 大規模データ
- オンラインサービス
より重視されるのは次の点です。
- 永続化
- 同時実行
- インデックス管理
- 権限管理
- 運用性
八、選定するときは何を見るべきか?
まず業務規模を見る
確認すべき主な点は次の通りです。
- データ量はどれくらいか?
- 更新頻度は高いか?
- オンラインでの増分書き込みが必須か?
- 強いメタデータフィルタが必要か?
次に、工程上の制約を見る
たとえば、次のような点です。
- 自前でデプロイできるか?
- クラウドホスティングに対応しているか?
- 既存システムと統合しやすいか?
- 保守コストは高くないか?
多くの場合、最適なのは「最も強力なもの」ではなく、「いちばん扱いやすいもの」です。
九、初学者がよくある誤解
ベクトルデータベースが自分で意味を理解していると思う
違います。
意味の品質をまず左右するのは embedding モデルです。
ベクトルを保存すれば RAG は必ずうまくいくと思う
それだけでは不十分です。
前段では文書のクリーニングや分割が必要で、後段では prompt と出力制約も必要です。
取りこぼしだけを見る
実際のプロジェクトでは、メタデータフィルタと出典の追跡可能性も同じくらい重要です。
ベクトルストアのデバッグ Checklist
ベクトルデータベースを接続したら、最初にやるべきことは、すぐに LLM につなぐことではありません。
「書き込み、フィルタ、検索、引用」の 4 つがすべて信頼できるかを確認しましょう。
| チェック項目 | 確認できるべきこと | よくあるリスク |
|---|---|---|
| 書き込み件数 | 元の chunk 数と保存件数が一致、または明確なフィルタ理由がある | 文書解析の失敗、重複書き込み |
| ベクトル次元 | 同じバッチのレコードで次元が一致している | embedding モデル変更後に次元が不一致 |
| メタデータ | source、section、page、topic などのフィールドが揃っている | 後で引用やフィルタができない |
| 類似度結果 | top-k の結果に id、score、text、metadata が出せる | 答えだけ見て、ヒット内容を見ない |
| フィルタ条件 | metadata filter で検索範囲を絞れる | フィールド型が不一致で見つからない |
この表を通過できないなら、すぐに prompt を改善しようとしないでください。多くの RAG 問題は、実はベクトルストアの段階で既に種がまかれています。
最小の入庫レコード確認例
records = [
{
"id": "doc_001_chunk_01",
"vector": [0.95, 0.05, 0.10],
"text": "コース購入後 7 日以内であれば返金を申請できます",
"metadata": {"source": "policy.md", "section": "返金ポリシー", "page": 1},
},
{
"id": "doc_001_chunk_02",
"vector": [0.10, 0.90, 0.05],
"text": "コース修了プロジェクトを完了すると証明書を取得できます",
"metadata": {"source": "policy.md", "section": "証明書の説明", "page": 2},
},
]
required_meta = {"source", "section", "page"}
vector_dim = len(records[0]["vector"])
for record in records:
problems = []
if len(record["vector"]) != vector_dim:
problems.append("vector_dim_mismatch")
missing = required_meta - set(record["metadata"])
if missing:
problems.append(f"missing_metadata={sorted(missing)}")
if not record["text"].strip():
problems.append("empty_text")
print(record["id"], problems or "ok")
期待される出力:
doc_001_chunk_01 ok
doc_001_chunk_02 ok
この確認は、入庫前に入れておくとよいです。実際のプロジェクトでは、metadata が欠けると、その後の引用、フィルタ、権限、評価がとても難しくなります。
ベクトルデータベースの選定意思決定表
| シーン | 推奨の出発点 | 理由 |
|---|---|---|
| 学習、最小 Demo | メモリ上のリスト、FAISS、Chroma | シンプルで、見えやすく、デバッグしやすい |
| ローカルの試作で永続化が必要 | Chroma、SQLite ベクトル拡張 | 保存しやすく、再実行しやすい |
| 企業知識ベース | メタデータフィルタと権限に対応したサービス型ベクトル DB | 同時実行、権限、監視、運用が必要 |
| マルチテナント SaaS | マネージドベクトルデータベース、または成熟した検索サービス | 分離、拡張、バックアップ、コストが重要 |
選定は「どれが一番流行っているか」ではなく、データ量、更新頻度、フィルタ要件、デプロイ方法、保守コストから考えましょう。
まとめ
この節で最も大切な理解は次の通りです。
ベクトルデータベースは「魔法のブラックボックス」ではなく、意味ベクトルとその付随情報を効率よく管理する仕組みです。
本当に気にすべきなのは、次の点です。
- ベクトルの品質は十分か
- 検索速度は十分か
- メタデータが業務要件を支えられるか
練習
- ミニベクトルデータベースにさらに 2 件のレコードを追加し、新しい
query_vectorを手動で作って並び順を試してみましょう。 sourceというメタデータフィールドを追加して、2 条件のフィルタを試してみましょう。- 考えてみましょう。もし embedding モデルがよくなかったら、ベクトルデータベースがどれだけ強くても挽回できるでしょうか?