8.1.6 RAG の最適化
学習目標
この節を終えると、あなたは次のことができるようになります。
- RAG システムでよくある最適化ポイントを見分ける
- chunk、top-k、rerank、prompt が結果にどう影響するかを理解する
- 簡単なコンテキスト組み立て戦略を作れるようになる
- 「まずボトルネックを見つけて、それからパラメータを調整する」という最適化の考え方を身につける
一、最適化の前に、どの段階に問題があるかを特定する
RAG システムは通常 4 つの段階に分けられる
ざっくり分けると、次の 4 つです。
- 文書処理
- 検索召回
- コンテキストの組み立て
- 回答生成
もし回答の質が悪いなら、まず次のように考えます。
- そもそも正しい資料が見つかっていない?
- 見つかったけれど、うまく入れられていない?
- 入れたけれど、モデルがうまく使えていない?
問題ごとに、対応する最適化の方向は違う
| 現象 | よくある問題点 |
|---|---|
| 答えがあるはずなのに検索できない | 切り分け / embedding / 検索戦略 |
| 検索はできたのに、答えがずれる | prompt / context packing / モデルの要約 |
| 回答が遅い・高い | top-k が大きすぎる / コンテキストが長すぎる / rerank が多すぎる |
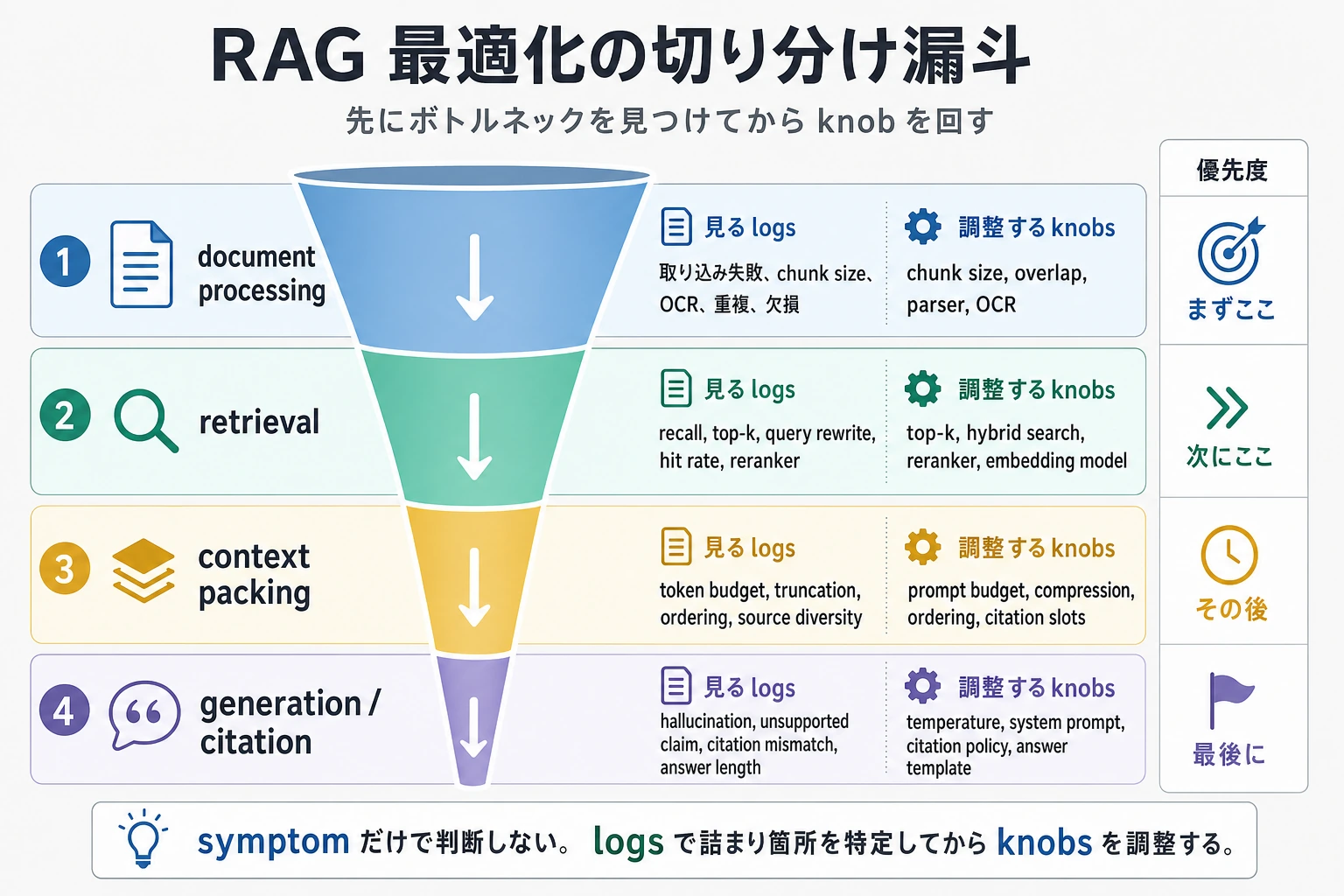
最適化の前に、まず漏斗に沿って段階を特定します。文書処理、召回、コンテキストの組み立て、生成制約のどこに問題があるかを見ます。段階を特定できないまま chunk、top-k、rerank、prompt をまとめて変えると、問題はむしろ再現しにくくなります。
二、文書処理から最適化する
Chunk の大きさは大きいほど良いわけではない
chunk が大きすぎると:
- 召回が不正確になる
- コンテキストを多く消費する
chunk が小さすぎると:
- 情報が切れ切れになりやすい
- 証拠が不完全になりやすい
なので、よくある最適化は「大きければ安全」ではなく、バランスを見つけることです。
構造情報を残すことは、とても重要な場合が多い
多くの文書では、価値があるのは文章そのものだけではなく、次のような情報です。
- 見出し
- 段落の階層
- 表の所属
- ページ位置
もしクリーニングのときにこれらの構造を全部消してしまうと、後の検索精度は下がりやすくなります。
三、召回段階でよく調整するポイント
top_k:多ければ多いほど良いわけではない
最初は多くの人がこう考えます。
資料を多めに取れば、間違いは減るはず
でも、そうとは限りません。
top_k が大きすぎると、関係ない内容まで入ってきて、逆にモデルの邪魔になることがあります。
Rerank:広く集めてから、きちんと選び直す
粗い召回にあいまいな内容が多く混ざるとき、rerank はとても役立ちます。
これは単に「1 段階増やす」だけではなく、コンテキストの質の密度を上げる作業です。
四、コンテキストの組み立ては、思っているより重要
モデルは「資料を見れば必ず使う」わけではない
正しい内容を召回できても、次のようなことは起こります。
- 重要な証拠が途中に埋もれる
- 複数の chunk の順番がバラバラ
- 情報の重複が多すぎる
つまり、「どのブロックを、どんな順番で入れるか」自体が最適化ポイントです。
実行できるコンテキストパッキングの例
chunks = [
{"score": 0.95, "text": "返金ポリシー:購入後 7 日以内で、学習進捗が 20% 未満なら返金できます。"},
{"score": 0.80, "text": "証明書の説明:すべてのプロジェクトを完了し、テストに合格すると証明書を取得できます。"},
{"score": 0.76, "text": "学習順序:まず Python を学び、その後に機械学習を学ぶのがおすすめです。"},
{"score": 0.72, "text": "補足条項:返金申請には注文情報の提出が必要です。"}
]
def pack_context(chunks, max_chars=60):
packed = []
total = 0
for item in sorted(chunks, key=lambda x: x["score"], reverse=True):
text = item["text"]
if total + len(text) > max_chars:
continue
packed.append(text)
total += len(text)
return packed
selected = pack_context(chunks, max_chars=60)
print("最終的にコンテキストに入れた chunk:")
for c in selected:
print("-", c)
これは最もシンプルな「コンテキスト予算の管理」です。
五、生成段階はどう最適化する?
Prompt で「資料をどう使うか」を明確に伝える
多くの場合、資料が見つからないのではなく、モデルに次の指示が十分に与えられていません。
- 与えられた資料だけを使って回答する
- 証拠が不足しているときは、知らないと認める
- 出典を引用する
よくある指示の考え方はこうです。
「以下の資料だけをもとに回答してください。資料が足りない場合は、足りないと明確に述べてください。」
出典を付けると、制御しやすさが大きく上がる
答えに出典があると、次のような利点があります。
- ユーザーの信頼が上がる
- 人が確認しやすい
- どの資料が効いたかを調べやすい
六、シンプルな最適化実験の考え方
一度に 5 つのパラメータを変えない
おすすめの順番は次のとおりです。
- 評価用データを固定する
- まず baseline を作る
- 1 回に変える変数は 1 つだけにする
たとえば:
- まず chunk size だけ変える
- 次に top-k だけ変える
- それから rerank を追加する
小さな設定比較スクリプト
configs = [
{"chunk_size": 200, "top_k": 3},
{"chunk_size": 400, "top_k": 3},
{"chunk_size": 200, "top_k": 5}
]
fake_scores = {
(200, 3): 0.78,
(400, 3): 0.71,
(200, 5): 0.74
}
for cfg in configs:
key = (cfg["chunk_size"], cfg["top_k"])
print(cfg, "-> 評価スコア", fake_scores[key])
これはおもちゃのデータですが、とても大事な考え方を表しています。
最適化は、感覚ではなく比較実験で行うものです。
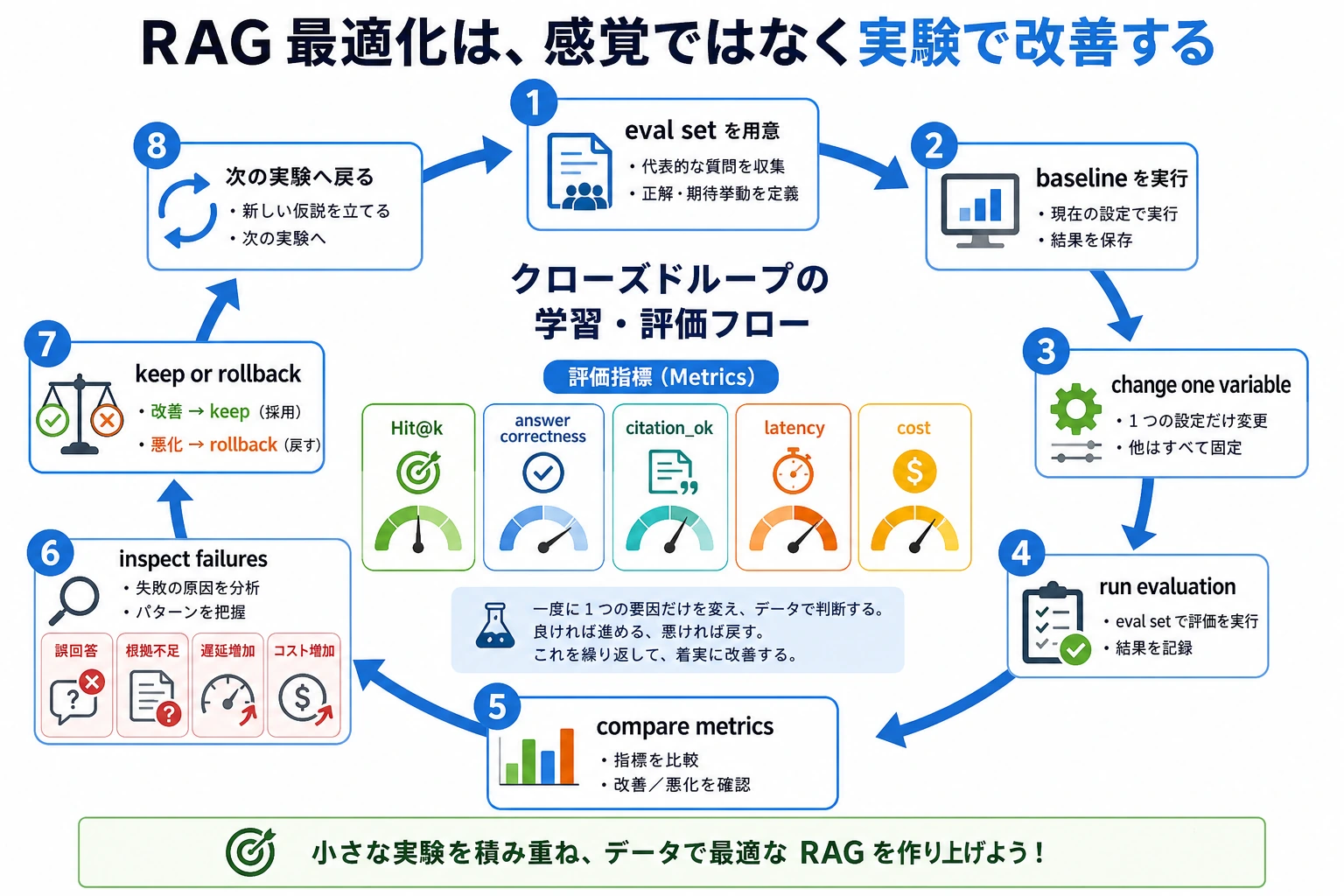
この図で大事なのは、「1 回に変える変数は 1 つだけ」という点です。毎回、評価用データを固定し、baseline を記録し、修復できなかった失敗と新しく出た失敗を確認してから、変更を残すかどうかを決めます。
七、RAG 最適化でよくあるトレードオフ
品質 vs コスト
- top-k を大きくする:より多く拾えるが、高くなる
- 強い reranker を使う:より正確だが、遅くなる
召回率 vs 精度
- 召回が少なすぎる:答えを取り逃がす
- 召回が多すぎる:ノイズが増える
リアルタイム性 vs 安定性
- リアルタイムで新しい資料を検索する方が柔軟
- 事前処理を十分にしておく方が、一般に安定する
万能の最適解はありません。あるのは、場面ごとの最適解だけです。
八、目標が「知識ベース駆動の教材生成アシスタント」なら、最適化の順番はどうする?
このようなプロジェクトで、最も起こしやすいミスは次のようなものです。
- 最初からもっと大きなモデルに変える
- あるいは最初から top-k を極端に大きくする
でも、より安定した基本順序はたいてい次の通りです。
- まず文書解析が正しいかを見る
- 次に知識ブロックが概念 / 例題 / 練習に分かれているかを見る
- それから、検索で正しい内容を召回できているかを見る
- さらに、構造化出力とテンプレートが正しい位置に内容を入れているかを見る
- 最後にモデルと prompt を調整する
一言でまとめると、こうです。
この種のプロジェクトでは、まず「正しく見つける」「正しく置く」を最適化し、最後に「もっときれいに書く」を最適化します。
九、教材生成プロジェクトに近い最小の最適化チェックリスト
| 現象 | まず確認したほうがよい場所 |
|---|---|
| テーマは合っているのに例題がない | 文書解析 / コンテンツタイプのラベル付け |
| 例題は見つかったのに、知識点の欄に入っている | schema / テンプレートのマッピング |
| 資料は多いのに、生成結果が空 | 検索フィルタ条件 / top-k / context packing |
| 内部文書に標準解答があるのに、外部内容に引っ張られる | ソース優先度の戦略 |
この表は特に初心者に向いています。なぜなら、「最適化」を、確認できるいくつかの段階に戻して考えられるからです。
十、初心者によくある誤解
最初からもっと大きなモデルに変える
RAG の問題は、モデルが弱いのではなく、検索の流れが調整できていないだけのことが多いです。
1 回のデモだけ見て、安定性を確認しない
1 回正解しても、システムが安定しているとは限りません。
top-k をどんどん大きくする
コンテキストが増えれば必ず良くなるわけではありません。特に、関係ない chunk が多く混ざると逆効果です。
RAG 最適化の切り分けマトリクス
実際に最適化するときに一番役立つのは、多くのテクニックを覚えることではなく、現象を具体的な流れに結びつけて特定できることです。
| 現象 | ログのどこを先に見るか | まず試すこと | 最初はおすすめしないこと |
|---|---|---|---|
| 正しい資料がまったく出てこない | query、top-k の元ヒット、chunk テキスト | 切り分けの調整、キーワード検索、query rewrite | いきなりもっと大きい生成モデルに変える |
| 正しい資料は出るが、順位が低い | 各 chunk の score と順位 | rerank を追加、混合検索の重み調整 | 理由なく top-k を大きくしすぎる |
| 正しい資料は context にあるのに、答えが条件を漏らす | 最終 context、prompt、回答の引用 | context packing の調整、1 つずつ引用させる | embedding モデルだけを変える |
| 答えが間違ったソースを引用する | answer、source_refs、証拠の断片 | citation check、引用形式の制限 | 最終回答が流暢かどうかだけを見る |
| 遅延とコストが急に上がる | top-k、rerank 数、context 長 | 候補数の制限、キャッシュ、段階的検索 | top-k とモデルサイズを同時に増やす |
この表の使い方は、毎回 1 つの現象だけを選び、対応するログを見て、どのレバーを動かすか決めることです。問題がどの段階にあるか分からないまま、chunk、embedding、top-k、rerank、prompt を同時に変えないでください。
固定した最適化実験フロー
RAG の最適化は、玄学的にパラメータをいじるのではなく、実験として進めるのがよいです。初心者向けの流れは、まず 20〜50 個の評価用質問を固定し、baseline を回し、検索ヒット、回答の正しさ、引用が結論を支えているかを記録し、それから 1 回に 1 つだけ変数を変えることです。
| 手順 | 出すべきもの | 判断基準 |
|---|---|---|
| baseline を作る | 現在の設定、評価用データ、失敗例 | 同じ結果を繰り返し出せる |
| 1 つの変数だけ変える | たとえば chunk size だけ、または rerank だけ追加 | 他の設定は変えない |
| 指標を比較する | Hit@k、回答正解率、引用の正しさ、平均遅延 | 少なくとも 1 つの重要指標が改善し、副作用が許容範囲 |
| 失敗例を見る | 新しく出た失敗と、修復できた失敗を分けて確認する | なぜ良くなったか、悪くなったかが分かる |
| 残すか決める | 1 行で結論を書く | 「なんとなく良い」ではなく、「どの種類の問題で良いか」まで書く |
最適化記録は、たとえば次のように書けます。
| 実験 | 変更点 | 改善 | 代償 | 結論 |
|---|---|---|---|---|
| baseline | キーワード検索、top-k=3 | 専門用語では安定 | 言い換え質問に弱い | 比較対象として残す |
| exp-1 | query rewrite を追加 | 言い換え質問のヒット率が上がる | 少量の誤った書き換え | 残すが、書き換えログを記録する |
| exp-2 | rerank を追加 | 正しい資料が上位に来やすい | 遅延が増える | 遅延が許容できるなら標準版にする |
コスト、遅延、品質のバランス確認
RAG システムは、最高スコアだけを追えばよいわけではありません。実際のプロジェクトでは、ユーザーが待てるか、コストに耐えられるか、結果が安定しているかも重要です。
| 最適化アクション | 期待できる効果 | ありうる代償 | 使うとよい場面 |
|---|---|---|---|
| top-k を増やす | 取り逃しを減らせる | コンテキストが長くなり、ノイズとコストが増える | 正しい資料が候補に入らないことが多いとき |
| rerank を追加する | 順位がより正確になる | 遅延が増え、実装も複雑になる | 候補に答えはあるが、順位が低いとき |
| query rewrite | 口語的な質問でも当たりやすくなる | 質問をずらしてしまうことがある | ユーザーの表現と文書の表現が大きく違うとき |
| より強い embedding | 意味検索が改善する | インデックスの再構築とコスト増 | baseline で意味検索がボトルネックだと分かったとき |
| より厳しい prompt | 幻覚が減る | 回答が慎重になりすぎることがある | 資料不足でも適当に答えがちなとき |
最適化するときの原則として、ログと評価用データがまだないなら、複雑な部品を急いで入れないことを覚えておいてください。観測できなければ、複雑な部品が問題を解決しているのか、新しい不確実性を増やしているのかを判断しにくいからです。
まとめ
この節で一番大事な理解は次のとおりです。
RAG の最適化は、1 つのパラメータを変えることではなく、「召回品質、コンテキスト品質、生成制約、コストと速度」のバランスを取ることです。
本当に有効な最適化は、たいていボトルネックの特定から始まります。やみくもに部品を増やすことではありません。
練習
pack_context()のmax_charsを変えて、選ばれる chunk がどう変わるか観察してください。- 自分でいくつかの
chunk_size / top_kの組み合わせを作り、小さな比較実験をしてみてください。 - 考えてみましょう。もしシステムがいつも「正しい資料は検索できるのに、答えがまだずれている」なら、次に最も最適化すべき場所はどこでしょうか。