9.3.6 工具安全与错误处理
工具让 Agent 从“会说”变成“会做”, 但一旦开始“会做”,风险就立刻升级。
例如:
- 查错数据还能补救
- 写错文件可能直接出事
- 调错删除接口,后果就更严重
所以这一节的核心不是“工具能不能跑通”,而是:
工具出错、超时、误用甚至越权时,系统能不能稳稳兜住。
学习目标
- 理解工具风险为什么比纯文本回答更高
- 学会设计权限分级、参数校验和错误返回
- 理解重试、超时、幂等和人工确认分别在防什么
- 通过可运行示例看懂一个带安全护栏的工具执行器
为什么工具安全是 Agent 的红线?
纯回答错,通常是“说错”
如果模型只是回答文本, 错误后果往往是:
- 信息不准
- 表述误导
虽然也很重要, 但很多场景里还停留在“输出层”。
工具调用错,可能是“做错”
一旦工具有执行能力, 风险会变成:
- 查到不该查的数据
- 写坏文件
- 调错外部接口
- 重复下单、重复扣费
也就是说:
工具把错误从语言层,放大成了动作层。
一个类比:聊天机器人和实习操作员不是一个风险等级
一个只会解释流程的机器人, 和一个真的能去点击按钮、改数据库、发邮件的操作员, 风险等级完全不同。
Agent 一旦进到工具层,也一样。
工具安全最常见的四层防线
参数校验
先确认:
- 参数齐不齐
- 类型对不对
- 值是否合法
权限分级
不同工具风险不同, 常见可分成:
read_onlywrite_limiteddestructive
执行约束
例如:
- 超时
- 最大重试次数
- 速率限制
- 幂等 key
审计与回放
最少也应该记录:
- 谁发起了调用
- 选了哪个工具
- 参数是什么
- 是否成功
- 返回了什么
先跑一个带护栏的最小执行器
下面这个例子会模拟三类工具:
- 低风险只读工具
- 中风险写操作工具
- 高风险删除工具
然后在执行前做:
- 白名单检查
- 参数校验
- 权限检查
- 超时模拟
ALLOWED_TOOLS = {
"search_docs": {"risk": "read_only", "required_args": ["keyword"]},
"update_profile": {"risk": "write_limited", "required_args": ["user_id", "city"]},
"delete_file": {"risk": "destructive", "required_args": ["path"]},
}
def run_tool(name, arguments, user_role):
if name not in ALLOWED_TOOLS:
return {"ok": False, "error": "unknown_tool"}
meta = ALLOWED_TOOLS[name]
for field in meta["required_args"]:
if field not in arguments:
return {"ok": False, "error": f"missing_arg:{field}"}
if meta["risk"] == "destructive" and user_role != "admin":
return {"ok": False, "error": "permission_denied"}
if name == "search_docs":
return {"ok": True, "data": {"result": f"找到与 {arguments['keyword']} 相关的文档"}}
if name == "update_profile":
return {
"ok": True,
"data": {"message": f"已把用户 {arguments['user_id']} 的城市更新为 {arguments['city']}"},
}
if name == "delete_file":
return {"ok": True, "data": {"message": f"已删除 {arguments['path']}"}}
return {"ok": False, "error": "tool_not_implemented"}
calls = [
("search_docs", {"keyword": "退款"}, "guest"),
("update_profile", {"user_id": 7, "city": "台北"}, "operator"),
("delete_file", {"path": "/tmp/a.txt"}, "operator"),
]
for call in calls:
print(call, "->", run_tool(*call))
预期输出:
('search_docs', {'keyword': '退款'}, 'guest') -> {'ok': True, 'data': {'result': '找到与 退款 相关的文档'}}
('update_profile', {'user_id': 7, 'city': '台北'}, 'operator') -> {'ok': True, 'data': {'message': '已把用户 7 的城市更新为 台北'}}
('delete_file', {'path': '/tmp/a.txt'}, 'operator') -> {'ok': False, 'error': 'permission_denied'}
这段代码为什么比“判断在不在白名单里”强得多?
因为它不是只做一个开关判断, 而是体现了工具安全的真实多层结构:
- 先确认工具存在
- 再确认参数完整
- 再确认权限够不够
- 最后才执行
这就是现实里工具执行器该做的事。
为什么权限不能只按“能不能用 Agent”来分?
因为风险不是统一的。
- 搜索文档的风险很低
- 修改资料风险中等
- 删除文件风险很高
所以权限要和工具风险绑定, 不能只做一个总开关。
为什么高风险工具常常要加人工确认?
因为就算模型大多数时候都选对, 高风险动作也不适合完全自动化。
典型做法是:
- 先生成执行计划
- 再要求用户或管理员确认
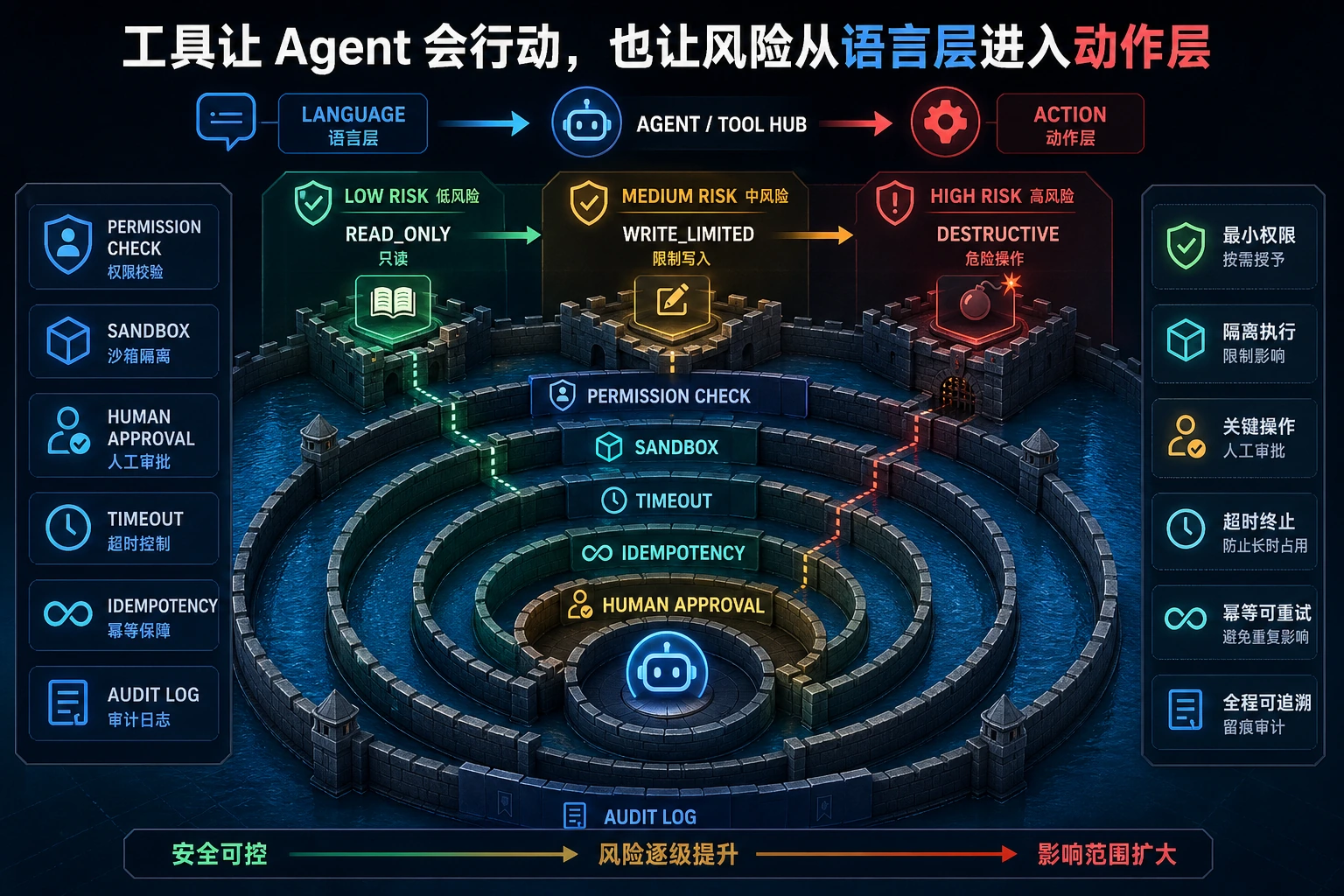
读这张图时,把“工具调用”想成一次真实操作:低风险可直接记录,高风险要经过权限、沙箱、人工确认和 audit log。Agent 越能行动,系统护栏越不能省。
错误处理为什么不能只靠 try/except?
因为失败不只有一种
常见失败类型至少包括:
- 参数错误
- 权限错误
- 工具超时
- 外部服务失败
- 返回结果为空
如果所有失败都只返回:
something went wrong
那后面几乎无法调试和恢复。
更好的做法:错误类型结构化
def normalize_error(code, detail):
return {
"ok": False,
"error": {
"code": code,
"detail": detail,
"retryable": code in {"timeout", "temporary_unavailable"},
},
}
print(normalize_error("missing_arg", "缺少 keyword"))
print(normalize_error("timeout", "上游接口 3 秒未返回"))
预期输出:
{'ok': False, 'error': {'code': 'missing_arg', 'detail': '缺少 keyword', 'retryable': False}}
{'ok': False, 'error': {'code': 'timeout', 'detail': '上游接口 3 秒未返回', 'retryable': True}}
结构化错误的好处是:
- 调度器知道是否该重试
- 日志系统更容易统计
- 前端也能做更清楚的反馈
什么错误适合重试?
通常更适合重试的是:
- timeout
- temporary unavailable
- transient network error
不适合重试的是:
- 参数缺失
- 权限不足
- 逻辑校验失败
超时、重试、幂等分别是在防什么?
超时:防止系统一直挂住
如果工具一直不返回, agent 整条链路都会被拖住。
所以超时本质上是在保护:
- 延迟
- 资源占用
重试:防止偶发故障直接变成失败
如果上游偶尔抖一下, 合理的重试可以明显提升稳定性。
但重试也要配合判断:
- 是不是临时错误
- 重试次数是否受限
幂等:防止重复执行造成重复副作用
例如:
- 重复扣款
- 重复发邮件
- 重复创建工单
所以写操作类工具通常要特别关心:
- 重复请求会不会造成重复副作用
审计日志为什么不是“以后再加”?
没有审计,出事后很难还原过程
你至少要能回答:
- 谁调用了什么工具
- 当时参数是什么
- 系统为什么允许它执行
- 最终结果是什么
一个最小审计记录例子
def audit_log(user_id, tool_name, arguments, result):
return {
"user_id": user_id,
"tool_name": tool_name,
"arguments": arguments,
"ok": result["ok"],
"error": result.get("error"),
}
result = run_tool("search_docs", {"keyword": "退款"}, "guest")
print(audit_log("u_001", "search_docs", {"keyword": "退款"}, result))
预期输出:
{'user_id': 'u_001', 'tool_name': 'search_docs', 'arguments': {'keyword': '退款'}, 'ok': True, 'error': None}
这虽然简单,但已经体现出审计核心:
- 记录动作
- 记录上下文
- 记录结果
最常见的误区
误区一:工具安全等上线前再补
不对。 工具安全是设计期就该进入的部分。
误区二:所有失败都重试一下就好
参数错误和权限错误, 重试只会浪费资源。
误区三:读操作就完全没有风险
很多读操作也可能涉及:
- 隐私
- 越权查询
- 敏感信息暴露
小结
这节最重要的,不是背下几种错误码, 而是建立一个工具层的基本安全观:
Agent 一旦具备行动能力,工具执行器就必须像后端核心服务一样处理权限、校验、超时、幂等和审计,而不能只把它当作“模型后面接个函数”。
这层意识越早建立, 后面的代码 Agent、多工具协作和真实上线系统就越稳。
练习
- 给示例再加一个
send_email工具,思考它的风险等级该怎么定。 - 为什么说“是否允许重试”应该是错误结构的一部分?
- 想一想:一个读数据库的工具为什么也可能需要权限控制?
- 如果你要为高风险工具增加人工确认,你会把确认放在调用前还是调用后?为什么?