5.6.6 实操工作坊:构建可复现的 ML 证据包
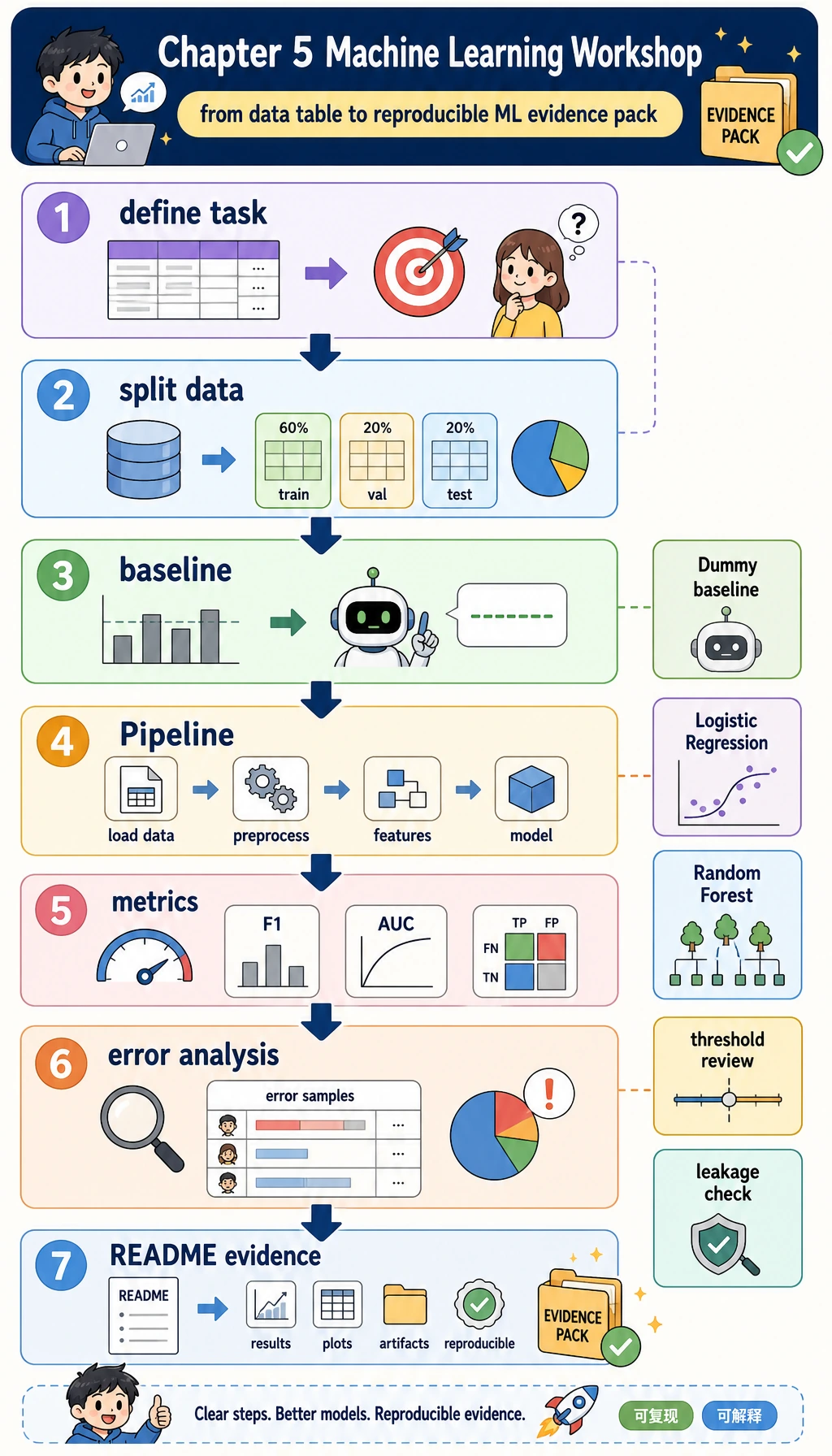
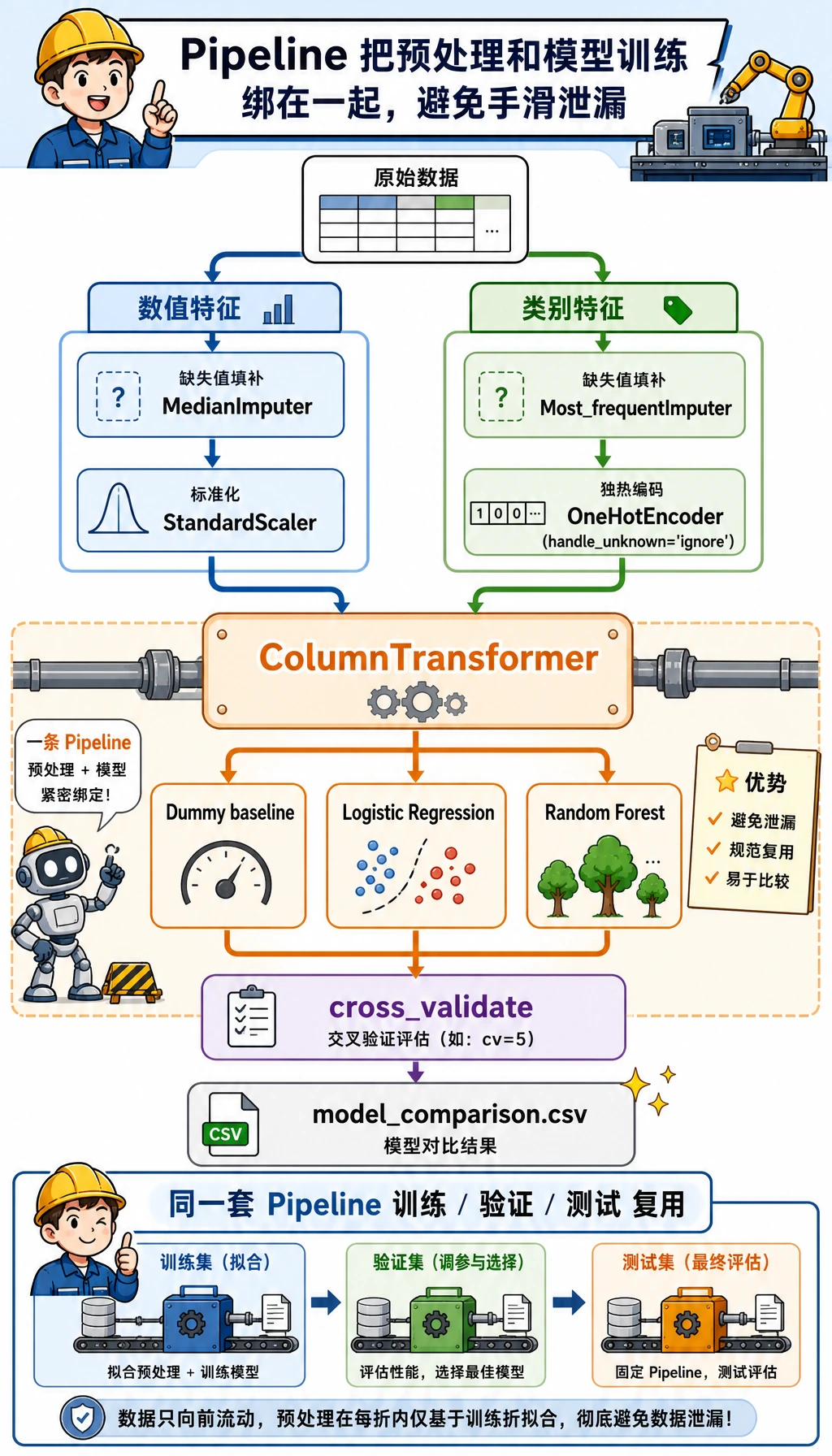
先看图,再跑代码。本工作坊的目标不是追最高分,而是练完整第 5 章主线:定义任务、划分数据、建立 baseline、训练真实模型、评估结果、检查错误,并留下别人可以复跑的证据。
学习目标
- 把一个表格业务问题转成监督学习任务
- 在尝试更强模型前,先建立
DummyClassifierbaseline - 使用
ColumnTransformer和Pipeline,让预处理留在训练流程内部 - 用交叉验证和独立测试集比较模型
- 复盘阈值取舍,不把
0.5当成魔法数字 - 保存指标、错误样本、泄漏检查和实验日志,形成项目证据
你要构建什么
这个工作坊会创建一个本地小项目:ml_workshop_run/。
任务是:
预测学习者是否可能延迟完成下一项学习任务。
数据是本地生成的合成表格数据,不需要下载。它包含练习时长、测验分数等数值特征,也包含学习路线、学习方式等类别特征。目标列是 delayed,其中 1 表示学习者延期风险较高。
| 第 5 章知识点 | 在项目里要做什么 |
|---|---|
| 任务定义 | 把“延期风险”转成二分类 |
| Baseline | 先训练 DummyClassifier |
| 特征预处理 | 填补缺失值、缩放数值列、对类别列做 one-hot |
| Pipeline | 把预处理和模型训练合成一个安全流程 |
| 评估 | 比较 F1、recall、precision、AUC 和混淆矩阵 |
| 阈值 | 复盘不同概率阈值的取舍 |
| 错误分析 | 保存预测错误的样本 |
| 作品集证据 | 保存 README、指标、错误样本和泄漏检查 |
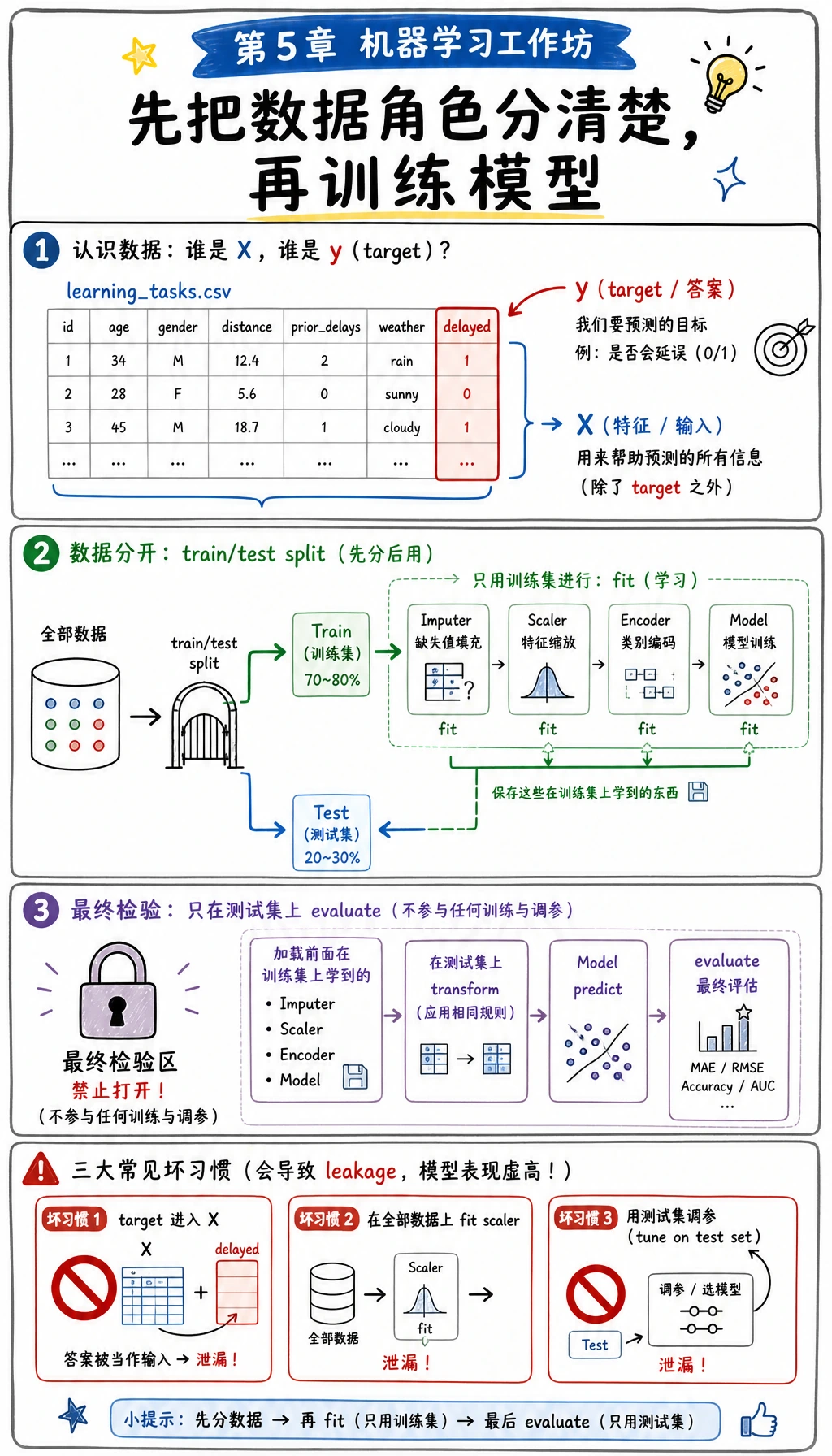
先看这张图再运行脚本。目标列 delayed 是模型要学习的答案,不能进入 X。训练集用来学习预处理参数和模型参数,测试集要留到最后验收。如果把这些角色混在一起,分数可能很好看,但项目已经不可信。
证据流程:从数据到报告
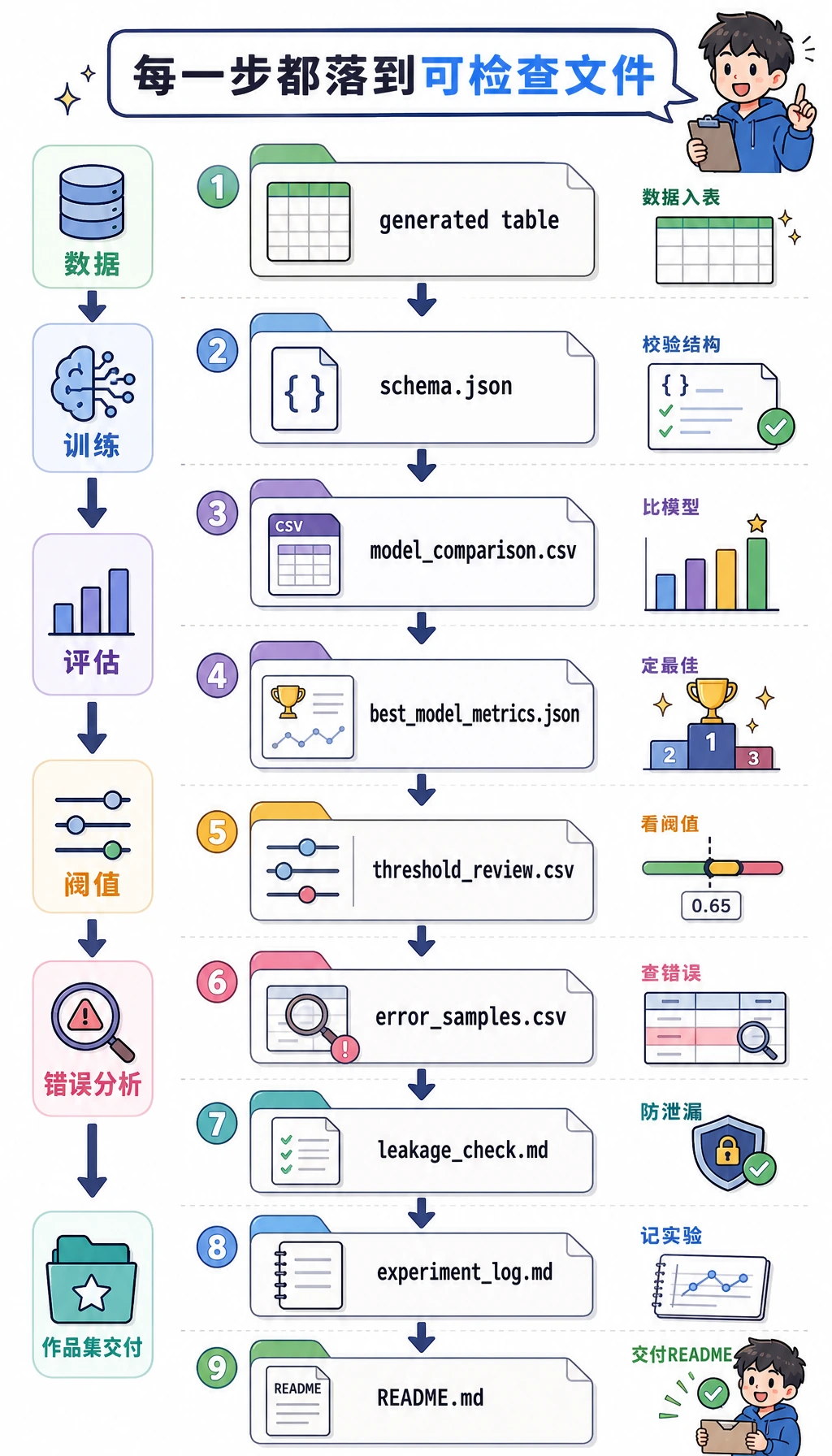
新手常见错误是停在:
model.fit(...)
print(score)
这还不够像一个真实机器学习项目。你需要留下证据链:
- 使用了什么数据?
- baseline 是什么?
- 哪个模型超过了 baseline?
- 哪个指标最重要?
- 模型错在哪里?
- 别人怎样复跑这个项目?
下面脚本会生成这套证据包:
ml_workshop_run/
data/learning_tasks.csv
data/schema.json
outputs/model_comparison.csv
outputs/best_model_metrics.json
outputs/threshold_review.csv
outputs/error_samples.csv
outputs/classification_report.txt
reports/leakage_check.md
reports/experiment_log.md
README.md
运行前先解码几个术语
- Baseline:最简单的第一个模型,用来告诉你必须超过什么水平。
- F1:precision 和 recall 的平衡,适合正类重要且类别不完全均衡的任务。
- Recall:真正延期的学习者里,有多少被模型抓到了?
- Precision:被模型标记为延期风险的人里,有多少真的延期?
- AUC:在不同阈值下,模型把正类排在负类前面的能力。
- Pipeline:scikit-learn 里把预处理和建模打包成一个安全工作流的对象。
- Data leakage(数据泄漏):模型不小心看到了预测时本来拿不到的信息。
准备环境
如果你在本课程仓库里,安装第 1~5 章运行环境:
python -m pip install -r requirements-course-core.txt
如果你在单独目录里练习,可以直接安装所需包:
python -m pip install numpy pandas scikit-learn
本工作坊使用稳定的 scikit-learn API,例如 Pipeline、ColumnTransformer、OneHotEncoder、DummyClassifier、LogisticRegression 和 RandomForestClassifier。本地已用 Python 3.13、NumPy 2.4、pandas 3.0、scikit-learn 1.8 验证。
跟着跑完整工作坊
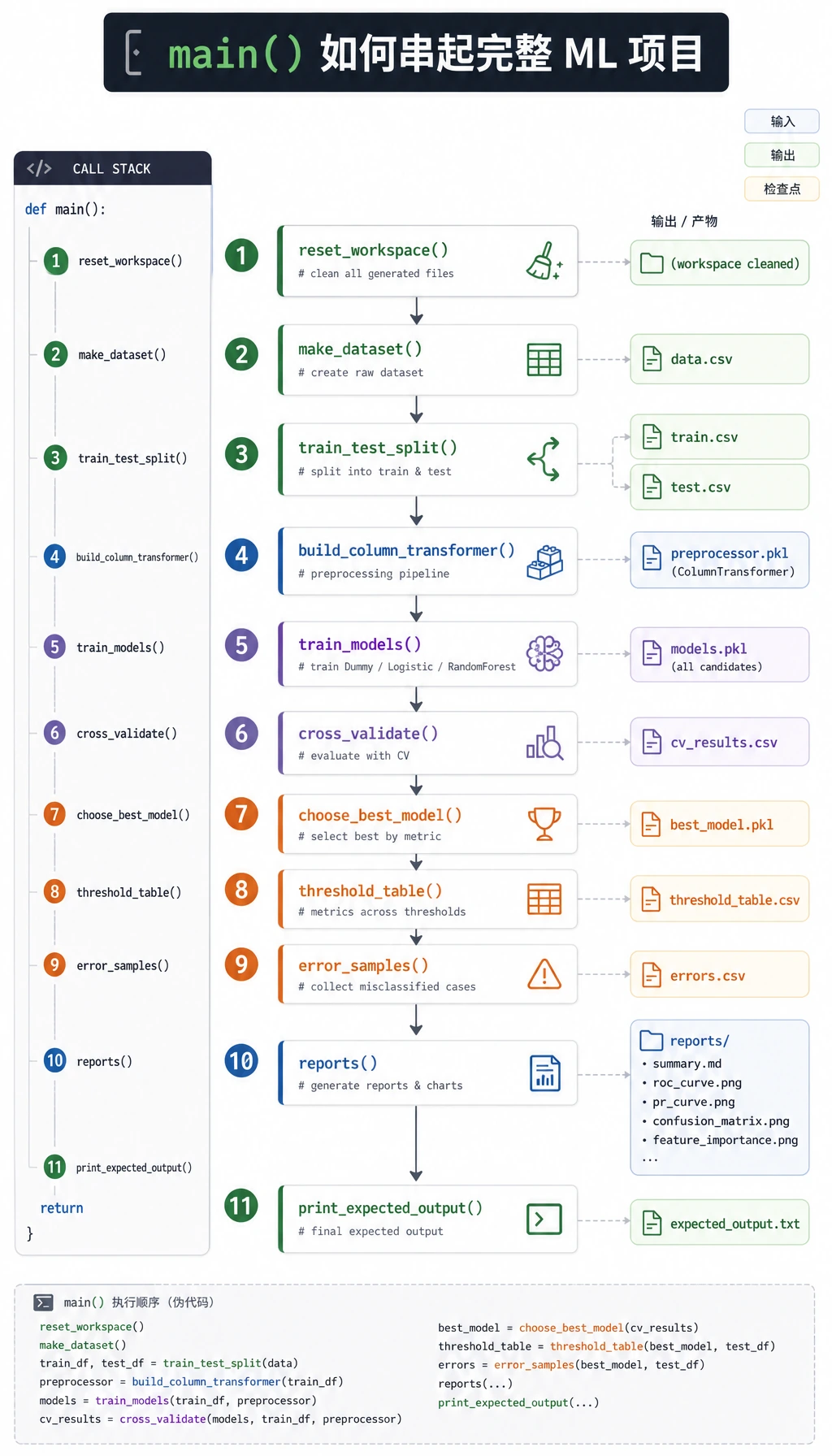
你要按这个顺序来:创建干净目录、复制一个脚本、运行一次,再检查生成的证据。先不要改模型。第一次运行是你的参照线。
创建干净目录
mkdir ch05-ml-workshop
cd ch05-ml-workshop
创建 ml_workshop.py
把下面代码保存为 ml_workshop.py。
from __future__ import annotations
import json
import shutil
from pathlib import Path
import numpy as np
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.dummy import DummyClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import (
accuracy_score,
classification_report,
confusion_matrix,
f1_score,
precision_score,
recall_score,
roc_auc_score,
)
from sklearn.model_selection import StratifiedKFold, cross_validate, train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler
RUN_DIR = Path("ml_workshop_run")
DATA_DIR = RUN_DIR / "data"
OUTPUT_DIR = RUN_DIR / "outputs"
REPORT_DIR = RUN_DIR / "reports"
NUMERIC_FEATURES = [
"hours_practiced",
"quiz_score",
"forum_questions",
"previous_stage_days",
]
CATEGORICAL_FEATURES = ["track", "study_mode"]
TARGET = "delayed"
def reset_workspace() -> None:
if RUN_DIR.exists():
shutil.rmtree(RUN_DIR)
for folder in (DATA_DIR, OUTPUT_DIR, REPORT_DIR):
folder.mkdir(parents=True, exist_ok=True)
def write_json(path: Path, payload) -> None:
path.write_text(json.dumps(payload, indent=2, ensure_ascii=False), encoding="utf-8")
def make_learning_dataset(seed: int = 42) -> pd.DataFrame:
rng = np.random.default_rng(seed)
rows = 240
hours = rng.normal(7.5, 2.2, rows).clip(1, 14)
quiz = rng.normal(72, 13, rows).clip(25, 100)
questions = rng.poisson(2.5, rows)
previous_days = rng.normal(9, 3.5, rows).clip(2, 24)
track = rng.choice(["data", "app", "model"], rows, p=[0.38, 0.34, 0.28])
study_mode = rng.choice(["solo", "group", "mentor"], rows, p=[0.45, 0.35, 0.20])
track_risk = np.select([track == "model", track == "app", track == "data"], [0.55, 0.20, 0.05])
mode_bonus = np.select([study_mode == "mentor", study_mode == "group", study_mode == "solo"], [-0.45, -0.18, 0.15])
raw_score = (
1.3
- 0.22 * hours
- 0.035 * quiz
+ 0.16 * questions
+ 0.14 * previous_days
+ track_risk
+ mode_bonus
+ rng.normal(0, 0.55, rows)
)
probability = 1 / (1 + np.exp(-raw_score))
delayed = (probability >= 0.38).astype(int)
df = pd.DataFrame(
{
"hours_practiced": hours.round(1),
"quiz_score": quiz.round(1),
"forum_questions": questions,
"previous_stage_days": previous_days.round(1),
"track": track,
"study_mode": study_mode,
TARGET: delayed,
}
)
missing_hours = rng.choice(df.index, size=10, replace=False)
missing_track = rng.choice(df.index, size=8, replace=False)
df.loc[missing_hours, "hours_practiced"] = np.nan
df.loc[missing_track, "track"] = np.nan
return df
def build_preprocessor() -> ColumnTransformer:
numeric_pipe = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="median")),
("scaler", StandardScaler()),
]
)
categorical_pipe = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("onehot", OneHotEncoder(handle_unknown="ignore", sparse_output=False)),
]
)
return ColumnTransformer(
transformers=[
("num", numeric_pipe, NUMERIC_FEATURES),
("cat", categorical_pipe, CATEGORICAL_FEATURES),
]
)
def make_models() -> dict[str, Pipeline]:
return {
"Dummy baseline": Pipeline(
steps=[
("preprocess", build_preprocessor()),
("model", DummyClassifier(strategy="most_frequent")),
]
),
"Logistic Regression": Pipeline(
steps=[
("preprocess", build_preprocessor()),
("model", LogisticRegression(max_iter=1000, class_weight="balanced")),
]
),
"Random Forest": Pipeline(
steps=[
("preprocess", build_preprocessor()),
("model", RandomForestClassifier(n_estimators=160, max_depth=5, random_state=42, class_weight="balanced")),
]
),
}
def evaluate_models(models, X_train, y_train, X_test, y_test) -> pd.DataFrame:
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
rows = []
for name, model in models.items():
cv_scores = cross_validate(
model,
X_train,
y_train,
cv=cv,
scoring={"f1": "f1", "roc_auc": "roc_auc", "recall": "recall"},
n_jobs=None,
)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
probabilities = model.predict_proba(X_test)[:, 1]
rows.append(
{
"model": name,
"cv_f1_mean": round(float(cv_scores["test_f1"].mean()), 3),
"cv_auc_mean": round(float(cv_scores["test_roc_auc"].mean()), 3),
"test_accuracy": round(accuracy_score(y_test, predictions), 3),
"test_precision": round(precision_score(y_test, predictions, zero_division=0), 3),
"test_recall": round(recall_score(y_test, predictions, zero_division=0), 3),
"test_f1": round(f1_score(y_test, predictions, zero_division=0), 3),
"test_auc": round(roc_auc_score(y_test, probabilities), 3),
}
)
return pd.DataFrame(rows).sort_values(["test_f1", "test_auc"], ascending=False)
def threshold_table(model: Pipeline, X_test: pd.DataFrame, y_test: pd.Series) -> pd.DataFrame:
probabilities = model.predict_proba(X_test)[:, 1]
rows = []
for threshold in [0.30, 0.40, 0.50, 0.60, 0.70]:
pred = (probabilities >= threshold).astype(int)
rows.append(
{
"threshold": threshold,
"precision": round(precision_score(y_test, pred, zero_division=0), 3),
"recall": round(recall_score(y_test, pred, zero_division=0), 3),
"f1": round(f1_score(y_test, pred, zero_division=0), 3),
"flagged_students": int(pred.sum()),
}
)
return pd.DataFrame(rows)
def save_error_samples(model: Pipeline, X_test: pd.DataFrame, y_test: pd.Series) -> pd.DataFrame:
probabilities = model.predict_proba(X_test)[:, 1]
predictions = (probabilities >= 0.5).astype(int)
errors = X_test.copy()
errors["actual_delayed"] = y_test.to_numpy()
errors["predicted_delayed"] = predictions
errors["delay_probability"] = probabilities.round(3)
errors = errors[errors["actual_delayed"] != errors["predicted_delayed"]]
return errors.sort_values("delay_probability", ascending=False).head(8)
def write_markdown_report(path: Path, title: str, lines: list[str]) -> None:
path.write_text("# " + title + "\n\n" + "\n".join(lines) + "\n", encoding="utf-8")
def main() -> None:
reset_workspace()
df = make_learning_dataset()
df.to_csv(DATA_DIR / "learning_tasks.csv", index=False)
write_json(
DATA_DIR / "schema.json",
{
"target": TARGET,
"numeric_features": NUMERIC_FEATURES,
"categorical_features": CATEGORICAL_FEATURES,
"meaning": "Predict whether a learner is likely to delay the next task.",
},
)
X = df[NUMERIC_FEATURES + CATEGORICAL_FEATURES]
y = df[TARGET]
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.25,
random_state=42,
stratify=y,
)
models = make_models()
metrics = evaluate_models(models, X_train, y_train, X_test, y_test)
metrics.to_csv(OUTPUT_DIR / "model_comparison.csv", index=False)
best_name = str(metrics.iloc[0]["model"])
best_model = models[best_name]
best_model.fit(X_train, y_train)
best_predictions = best_model.predict(X_test)
best_probabilities = best_model.predict_proba(X_test)[:, 1]
write_json(
OUTPUT_DIR / "best_model_metrics.json",
{
"best_model": best_name,
"accuracy": round(accuracy_score(y_test, best_predictions), 3),
"precision": round(precision_score(y_test, best_predictions, zero_division=0), 3),
"recall": round(recall_score(y_test, best_predictions, zero_division=0), 3),
"f1": round(f1_score(y_test, best_predictions, zero_division=0), 3),
"auc": round(roc_auc_score(y_test, best_probabilities), 3),
"confusion_matrix": confusion_matrix(y_test, best_predictions).tolist(),
},
)
threshold_results = threshold_table(best_model, X_test, y_test)
threshold_results.to_csv(OUTPUT_DIR / "threshold_review.csv", index=False)
errors = save_error_samples(best_model, X_test, y_test)
errors.to_csv(OUTPUT_DIR / "error_samples.csv", index=False)
report_text = classification_report(y_test, best_predictions, zero_division=0)
(OUTPUT_DIR / "classification_report.txt").write_text(report_text, encoding="utf-8")
write_markdown_report(
REPORT_DIR / "leakage_check.md",
"Leakage Check",
[
"- Split the data before fitting imputers, scalers, encoders, or models.",
"- Keep the target column out of the feature list.",
"- Put preprocessing inside ColumnTransformer and Pipeline.",
"- Use cross-validation on the training split, then check the test split once.",
],
)
write_markdown_report(
REPORT_DIR / "experiment_log.md",
"Experiment Log",
[
"| version | change | main result | next step |",
"|---|---|---|---|",
f"| v0 | Dummy baseline | f1={metrics[metrics['model'] == 'Dummy baseline'].iloc[0]['test_f1']} | Need a real model |",
f"| v1 | {best_name} with Pipeline | f1={metrics.iloc[0]['test_f1']} | Review threshold and errors |",
],
)
readme_lines = [
"# Machine Learning Workshop Evidence Pack",
"",
"Run command:",
"",
"```bash",
"python ml_workshop.py",
"```",
"",
"Generated files:",
"- data/learning_tasks.csv",
"- outputs/model_comparison.csv",
"- outputs/best_model_metrics.json",
"- outputs/threshold_review.csv",
"- outputs/error_samples.csv",
"- reports/leakage_check.md",
"- reports/experiment_log.md",
]
(RUN_DIR / "README.md").write_text("\n".join(readme_lines) + "\n", encoding="utf-8")
positive_rate = float(y.mean())
dummy_f1 = float(metrics[metrics["model"] == "Dummy baseline"].iloc[0]["test_f1"])
best_f1 = float(metrics.iloc[0]["test_f1"])
print("STEP 1: data prepared")
print(f"rows: {len(df)}")
print(f"features: {len(NUMERIC_FEATURES) + len(CATEGORICAL_FEATURES)}")
print(f"positive_rate: {positive_rate:.3f}")
print("STEP 2: baseline and model comparison")
print(f"dummy_f1: {dummy_f1:.3f}")
print(f"best_model: {best_name}")
print(f"best_f1: {best_f1:.3f}")
print("STEP 3: evidence files")
print(RUN_DIR / "README.md")
print(OUTPUT_DIR / "model_comparison.csv")
print(OUTPUT_DIR / "error_samples.csv")
print(REPORT_DIR / "leakage_check.md")
if __name__ == "__main__":
main()
运行
python ml_workshop.py
预期输出:
STEP 1: data prepared
rows: 240
features: 6
positive_rate: 0.287
STEP 2: baseline and model comparison
dummy_f1: 0.000
best_model: Logistic Regression
best_f1: 0.821
STEP 3: evidence files
ml_workshop_run/README.md
ml_workshop_run/outputs/model_comparison.csv
ml_workshop_run/outputs/error_samples.csv
ml_workshop_run/reports/leakage_check.md

检查生成的证据文件
在解释任何分数之前,先确认证据文件确实生成了。
find ml_workshop_run -maxdepth 2 -type f | sort
预期输出:
ml_workshop_run/README.md
ml_workshop_run/data/learning_tasks.csv
ml_workshop_run/data/schema.json
ml_workshop_run/outputs/best_model_metrics.json
ml_workshop_run/outputs/classification_report.txt
ml_workshop_run/outputs/error_samples.csv
ml_workshop_run/outputs/model_comparison.csv
ml_workshop_run/outputs/threshold_review.csv
ml_workshop_run/reports/experiment_log.md
ml_workshop_run/reports/leakage_check.md
一步一步读输出

先看 baseline
打开 ml_workshop_run/outputs/model_comparison.csv。
Dummy baseline 通常会得到 f1 = 0。这不是失败,而是最低参照线。如果真实模型连它都打不过,说明数据、特征、指标或任务定义还没准备好。
用这个小读表命令,不要对着原始 CSV 猜:
python - <<'PY'
import pandas as pd
comparison = pd.read_csv("ml_workshop_run/outputs/model_comparison.csv")
print(comparison[["model", "test_f1", "test_recall", "test_auc"]].to_string(index=False))
PY
预期输出:
model test_f1 test_recall test_auc
Logistic Regression 0.821 0.941 0.934
Random Forest 0.571 0.471 0.871
Dummy baseline 0.000 0.000 0.500
检查真实模型
预期最佳模型是 Logistic Regression。这对新手是很好的结果,因为它:
- 容易解释
- 训练速度快
- 足够作为第一个表格 baseline
- 适合数值缩放和类别 one-hot 后的特征
不要因为 Random Forest 听起来更强就直接跳过去。第 5 章最重要的习惯是:先简单 baseline,再更强模型。
复盘阈值
打开 ml_workshop_run/outputs/threshold_review.csv。
对延期风险模型来说,recall 往往比 precision 更重要:如果目标是及早帮助学习者,漏掉高风险学习者可能比多提醒几个人更贵。因此阈值是项目决策,不只是模型默认值。
运行这个小决策助手。它会选择 recall 至少为 0.90 的行里 F1 最好的方案,并用普通文本打印取舍。
python - <<'PY'
import pandas as pd
thresholds = pd.read_csv("ml_workshop_run/outputs/threshold_review.csv")
choice = thresholds[thresholds["recall"] >= 0.90].sort_values(
["f1", "precision"],
ascending=False,
).iloc[0]
print(f"chosen_threshold={choice.threshold:.2f}")
print(
f"precision={choice.precision:.3f} "
f"recall={choice.recall:.3f} "
f"f1={choice.f1:.3f} "
f"flagged={int(choice.flagged_students)}"
)
PY
预期输出:
chosen_threshold=0.50
precision=0.727 recall=0.941 f1=0.821 flagged=22
如果业务目标变了,就改这条规则。例如低成本提醒系统可能 recall >= 0.80 就够用;医疗或安全类场景则通常需要更严格的 recall 目标和人工复核。
检查错误样本

打开 ml_workshop_run/outputs/error_samples.csv。
请问自己:
- False negative 是否是测验分高但练习时间少的学习者?
- False positive 是否集中在某个学习路线或学习方式?
- 这些特征是否真的描述了延期原因,还是缺少关键变量?
错误分析会把项目从“一个分数”变成“一次调查”。
再用一个小读表命令,把错误预测分桶:
python - <<'PY'
import pandas as pd
errors = pd.read_csv("ml_workshop_run/outputs/error_samples.csv")
errors["error_type"] = errors.apply(
lambda row: "false_negative" if row.actual_delayed == 1 else "false_positive",
axis=1,
)
print(errors["error_type"].value_counts().to_string())
print("--- by track ---")
print(errors.groupby(["error_type", "track"]).size().to_string())
PY
预期输出:
error_type
false_positive 6
false_negative 1
--- by track ---
error_type track
false_negative data 1
false_positive app 2
data 3
model 1
把它当作待办清单,而不是“甩锅”。False positive 可能说明模型太谨慎;如果产品目标是提前帮助学习者,false negative 通常更值得优先处理。
阅读泄漏检查
打开 ml_workshop_run/reports/leakage_check.md。
最重要的一句是:
先划分数据,再只在训练流程内部 fit 预处理器。
这就是为什么示例把 ColumnTransformer 放在 Pipeline 里面。
常见错误与排查闭环
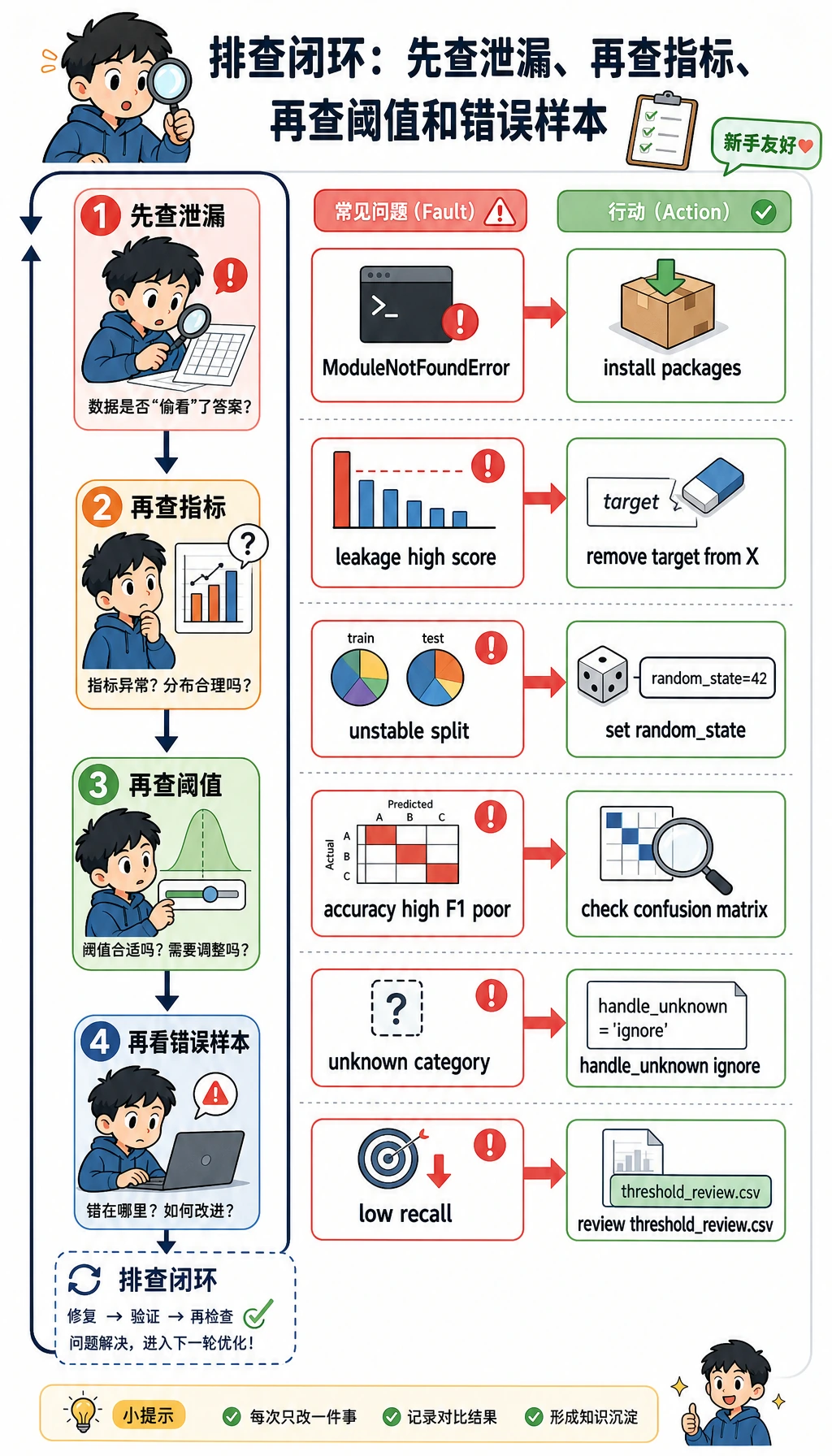
| 现象 | 可能原因 | 处理方法 |
|---|---|---|
ModuleNotFoundError: No module named 'sklearn' | 课程运行环境未安装 | 运行 python -m pip install -r requirements-course-core.txt,或安装 numpy pandas scikit-learn |
| 分数高得离谱 | 目标泄漏或划分错误 | 检查特征列表,确认 delayed 没有进入 X |
| 每次运行 Test F1 都变 | 随机种子或数据划分没有固定 | 学习阶段先保留 random_state=42 |
| Accuracy 高但 F1 很差 | 类别不均衡 | 同时看 precision、recall、F1 和混淆矩阵 |
| Pipeline 遇到类别值时报错 | 测试集出现了训练集没见过的新类别 | 使用 OneHotEncoder(handle_unknown="ignore") |
| 模型抓到的正类太少 | 阈值过高 | 查看 threshold_review.csv,如果 recall 更重要就降低阈值 |
把它升级成作品集项目


按小步升级:
- 把合成数据换成你自己项目里的 CSV。
- 增加
config.json,记录随机种子、测试集比例和模型列表。 - 再加入一个模型,但保留 Dummy baseline。
- 增加混淆矩阵图或阈值曲线。
- 写一段文字解释前 3 类错误模式。
- 在
README.md里加入“下一步怎么改”。
离开本页前做一次很小的迭代:先追加一条实验记录,然后只改一个地方再复跑,例如把随机森林的 max_depth 改成 8。
python - <<'PY'
from pathlib import Path
log_path = Path("ml_workshop_run/reports/experiment_log.md")
log = log_path.read_text(encoding="utf-8")
log += "\n| v2 | Try RandomForest max_depth=8 | Compare CV F1 and test F1 after rerun | Keep only if both stay stable |\n"
log_path.write_text(log, encoding="utf-8")
print(log_path.read_text(encoding="utf-8"))
PY
预期输出会包含这一行:
| v2 | Try RandomForest max_depth=8 | Compare CV F1 and test F1 after rerun | Keep only if both stay stable |
这就是第 5 章最该形成的习惯:一次只改一个变量,复跑,比较证据,再决定是否保留。随手乱试还不算建模实践;有记录的实验才算。
作品集检查清单
在宣布第 5 章项目完成前,确认你有:
- 能从干净目录运行的命令
- baseline 指标
- 真实模型指标
- 模型对比表
- 泄漏检查
- 阈值或指标解释
- 错误样本
- 带下一步计划的 README
总结
这个工作坊把第 5 章主线压缩到一个文件里:数据、baseline、Pipeline、模型对比、阈值复盘、错误分析、泄漏检查和 README 证据。如果你能复跑并解释每个输出文件,就不再只是学习机器学习 API,而是在练真实建模流程。