5.4.4 偏差-方差权衡
本节概览
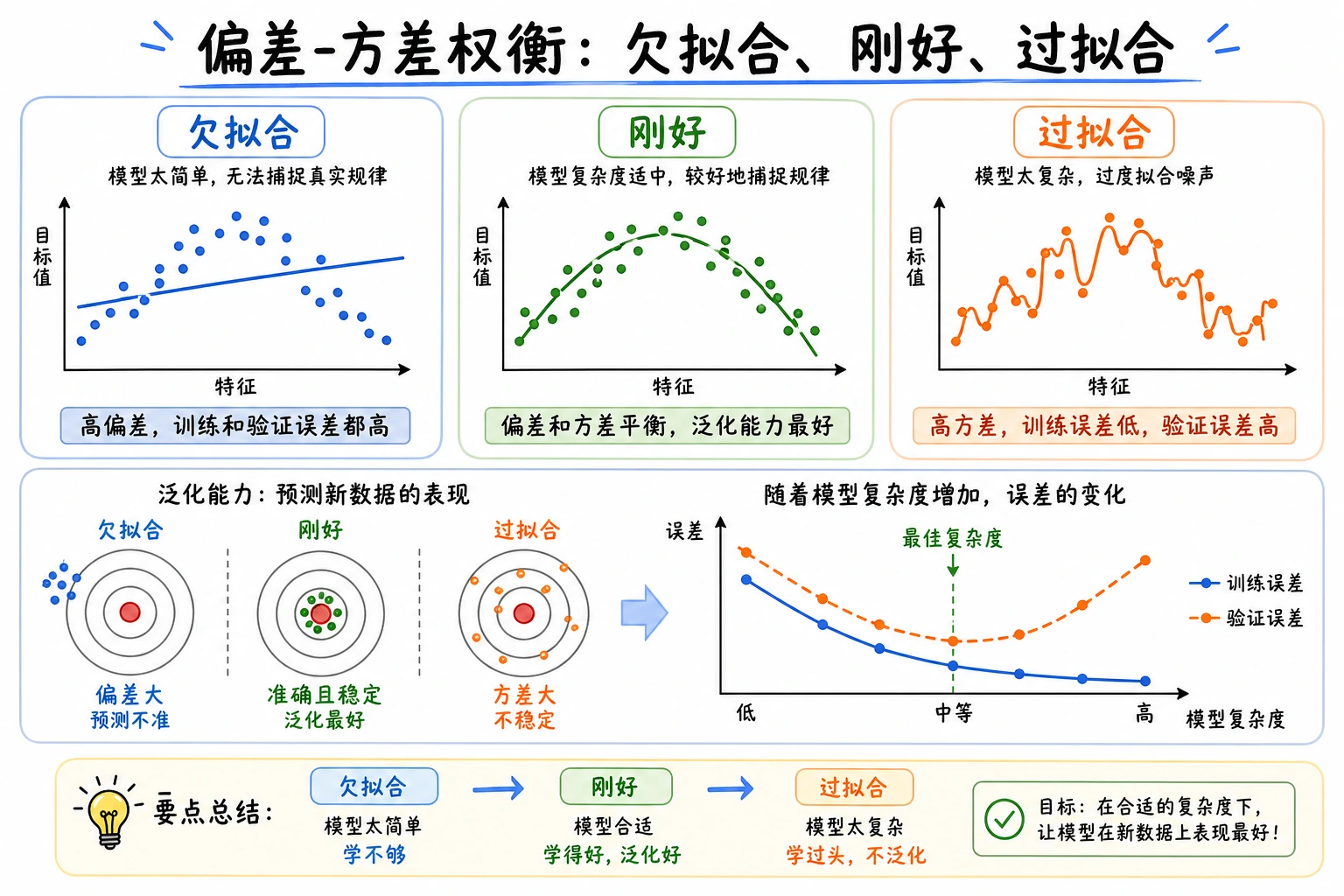
偏差和方差不是只存在于理论里的词。它们是一种诊断方式:模型是太简单、太不稳定,还是受限于数据质量。
你会做出什么
本节用决策树演示:
- 模型复杂度如何改变训练分数和测试分数;
- 如何通过 train-test gap 判断欠拟合和过拟合;
- 学习曲线如何说明更多数据是否可能有帮助;
- 高偏差和高方差分别应该采取什么行动。
环境准备
python -m pip install -U scikit-learn numpy
运行完整实验
新建 bias_variance_lab.py:
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.metrics import accuracy_score
from sklearn.model_selection import learning_curve, train_test_split
from sklearn.tree import DecisionTreeClassifier
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42, stratify=y
)
print("complexity_lab")
for depth in [1, 3, 5, None]:
model = DecisionTreeClassifier(max_depth=depth, random_state=42)
model.fit(X_train, y_train)
train_acc = accuracy_score(y_train, model.predict(X_train))
test_acc = accuracy_score(y_test, model.predict(X_test))
gap = train_acc - test_acc
print(
f"max_depth={str(depth):<4} "
f"train={train_acc:.3f} test={test_acc:.3f} gap={gap:.3f} "
f"leaves={model.get_n_leaves()}"
)
print("learning_curve_lab")
model = DecisionTreeClassifier(max_depth=3, random_state=42)
train_sizes, train_scores, val_scores = learning_curve(
model,
X,
y,
cv=5,
train_sizes=[0.2, 0.4, 0.6, 0.8, 1.0],
scoring="accuracy",
)
for size, train_mean, val_mean in zip(train_sizes, train_scores.mean(axis=1), val_scores.mean(axis=1)):
print(f"train_size={size:<3} train={train_mean:.3f} cv={val_mean:.3f} gap={train_mean - val_mean:.3f}")
运行:
python bias_variance_lab.py
预期输出:
complexity_lab
max_depth=1 train=0.923 test=0.923 gap=-0.001 leaves=2
max_depth=3 train=0.977 test=0.944 gap=0.032 leaves=7
max_depth=5 train=0.995 test=0.937 gap=0.058 leaves=15
max_depth=None train=1.000 test=0.923 gap=0.077 leaves=18
learning_curve_lab
train_size=91 train=0.989 cv=0.847 gap=0.142
train_size=182 train=0.986 cv=0.870 gap=0.116
train_size=273 train=0.978 cv=0.903 gap=0.075
train_size=364 train=0.975 cv=0.917 gap=0.057
train_size=455 train=0.974 cv=0.919 gap=0.055
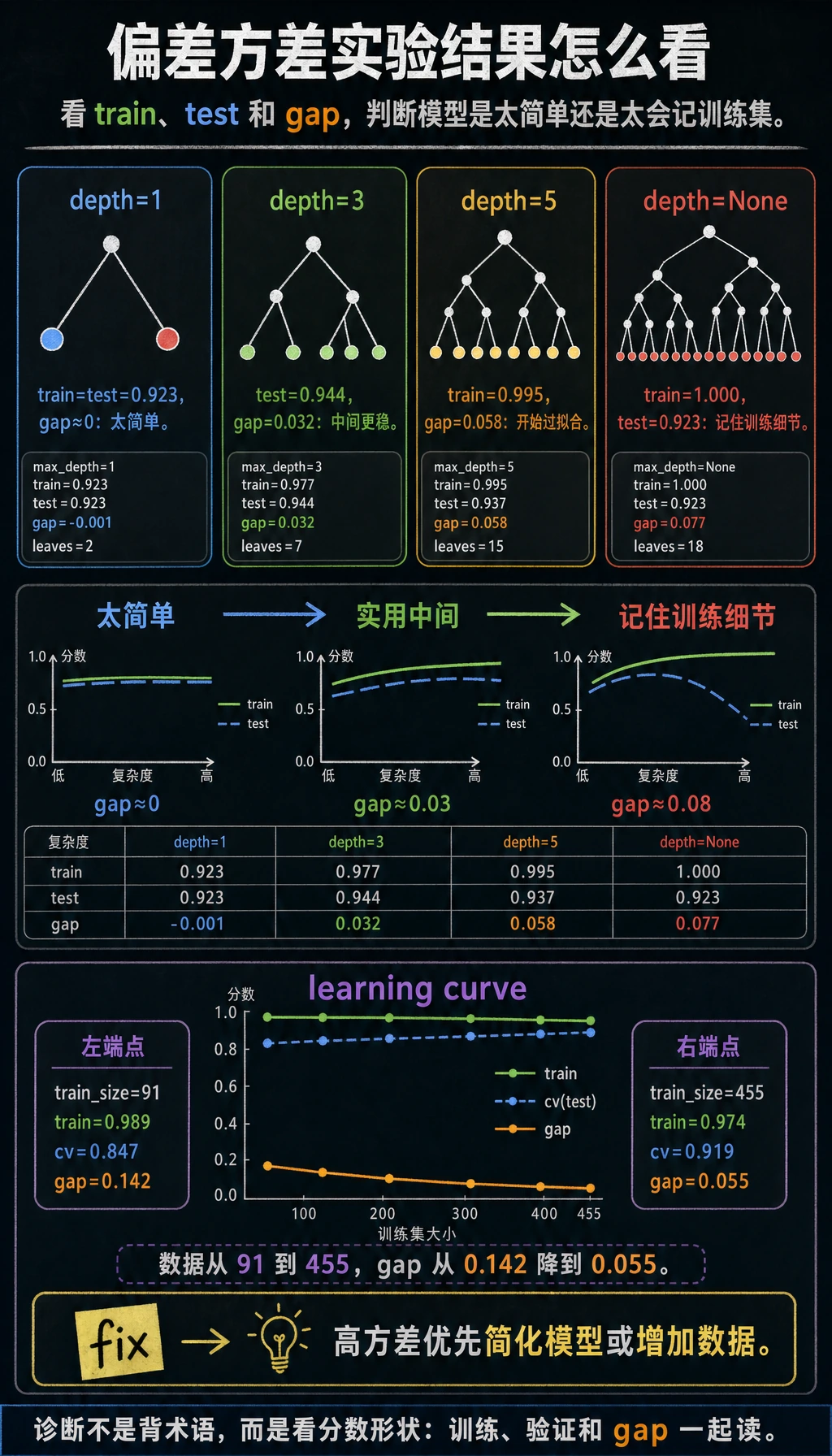
读懂复杂度实验
max_depth 越大,树越复杂:
max_depth=1 train=0.923 test=0.923 gap=-0.001 leaves=2
max_depth=None train=1.000 test=0.923 gap=0.077 leaves=18
max_depth=1 很简单。训练和测试很接近,但分数不是最好。这可能是高偏差:模型太简单。
max_depth=None 把训练集记得很完美,但测试准确率下降。这是高方差:模型学到了训练细节,却不能泛化。
实用上最好的模型往往在中间:
max_depth=3 train=0.977 test=0.944 gap=0.032
它没有在训练集上满分,但泛化更好。
学习曲线
学习曲线展示训练数据增加时会发生什么:
train_size=91 train=0.989 cv=0.847 gap=0.142
train_size=455 train=0.974 cv=0.919 gap=0.055
数据增多后,验证分数上升,gap 变小。这说明更多数据可能有帮助,但模型仍然可以通过更好的特征或调参继续改进。
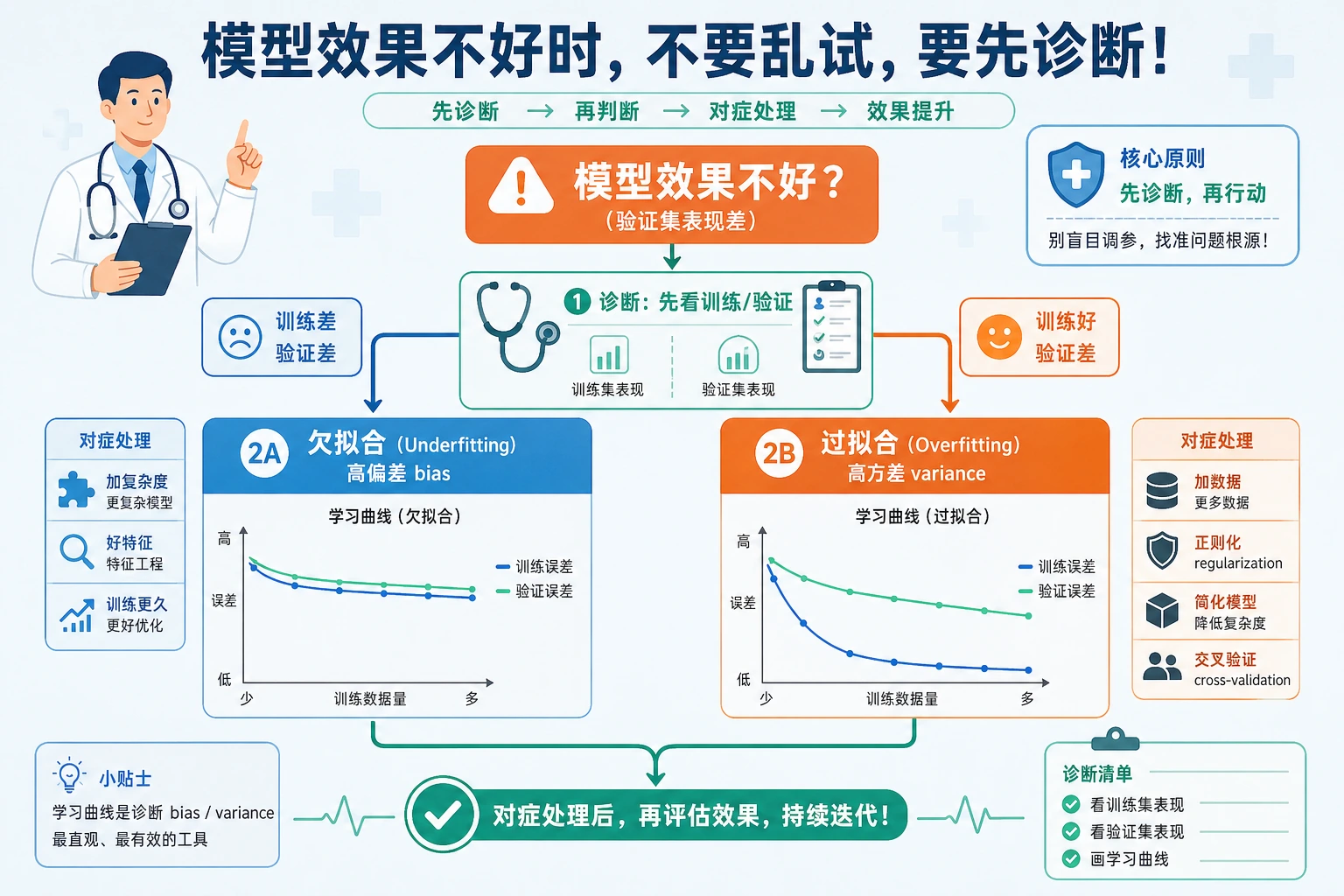
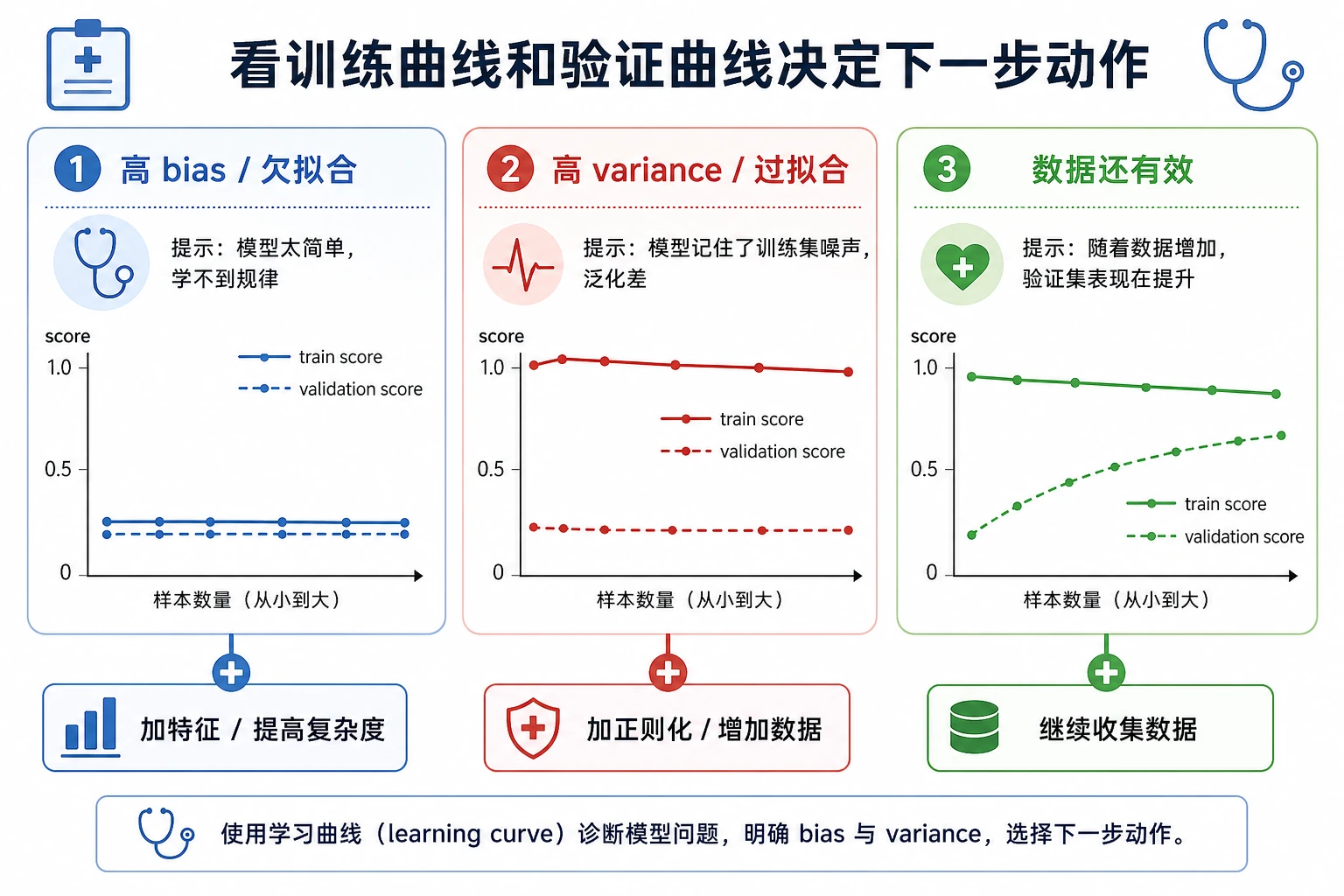
诊断规则
| 模式 | 可能问题 | 尝试 |
|---|---|---|
| train 低,validation 低 | 高偏差 / 欠拟合 | 更强模型、更好特征、减弱正则化 |
| train 高,validation 低 | 高方差 / 过拟合 | 简化模型、加强正则化、增加数据 |
| train 高,validation 高 | 拟合良好 | 在最终 holdout 上测试并监控漂移 |
| validation 按 fold 波动大 | 不稳定或存在数据分群 | 检查 fold,增加数据,使用更稳模型 |
不要只靠一个指标诊断。要同时看训练分数、验证分数、gap,以及错误是否集中在某个分群。
实用修复
高偏差时:
- 增加有用特征;
- 使用表达能力更强的模型;
- 减弱过强正则化;
- 如果是迭代模型,训练更久。
高方差时:
- 降低模型复杂度;
- 加强正则化;
- 收集更多样且有代表性的数据;
- 使用交叉验证和最终 holdout;
- 考虑能降低方差的集成模型。
常见排查清单
| 现象 | 可能原因 | 修复方式 |
|---|---|---|
| train 和 validation 都差 | 模型表达不了模式 | 改进特征或模型类别 |
| train 满分,validation 较差 | 过拟合 | 限制深度、剪枝、正则化 |
| 更多数据提升 validation | 方差或数据不足 | 收集更有代表性的数据 |
| 更多数据没帮助 | 高偏差或标签噪声 | 改进特征、标签或模型 |
| validation 按 fold 跳动 | 数据不均匀 | 检查分群分布 |
练习
- 给树加入
min_samples_leaf=5。gap 怎么变? - 尝试
max_depth=2, 4, 6, 8。测试准确率在哪里最高? - 把树换成逻辑回归。问题更像偏差还是方差?
- 在复杂度实验中改用 5 折交叉验证,而不是一次测试切分。
- 查看最佳树的错误样本。错误是否集中在某个类别?
过关检查
你能解释下面几点,就完成本节:
- 高偏差表示模型太简单或缺少信号;
- 高方差表示模型对训练细节太敏感;
- train-validation gap 是实用诊断工具;
- 学习曲线能说明更多数据是否可能有帮助;
- 修复方式取决于现象,不取决于术语本身。