8.4.3 API 設計とサービス化
LLM アプリを作るとき、多くの人はローカルスクリプトまでは書けても、サービス化の段階で急に混乱します。
本当に大事なのは「インターフェースを書けるか」ではなく、次の点です。
このインターフェースを、他の人が長期的に安定して呼び出せるか。
この節では、その問いに答えます。
学習目標
- LLM サービス API が最低限どんな内容を定義すべきか理解する
- わかりやすいリクエスト・レスポンス構造を設計できるようになる
- 冪等性、エラー返却、trace_id、バージョン管理といったサービス化の重要概念を理解する
- 最小限の API 処理の流れを読めるようになる
初学者向けの用語ブリッジ
API 設計は、次の言葉に直感を持てるとかなり読みやすくなります。
| 用語 | 初学者向けの意味 | この節での役割 |
|---|---|---|
API | Application Programming Interface。あるプログラムが別のプログラムを安定して呼ぶための入口 | 他のコードが依存するサービス入口 |
endpoint | /api/v1/chat のような、具体的に呼び出せるアドレス | 機能を URL パスとして公開する場所 |
schema | どのフィールドを許可し、何を必須にするかを決めるルール | リクエストとレスポンスの形を予測しやすくする |
payload | リクエストで送るデータ本体 | この節では、ユーザーの質問や関連メタデータを指すことが多い |
trace_id | 1件のリクエストを追跡するための一意な ID | API ログ、検索ログ、モデルログ、エラーをつなげる |
idempotency | 同じリクエストを繰り返しても、制御できない副作用が増えない性質 | タイムアウトやネットワーク失敗後のリトライで重要 |
これらは単なる用語ではありません。実際のシステムでは、フロントエンド、バックエンド、ログ、評価、デプロイが協調するための部品です。
なぜ API 設計は「ただ JSON で包むだけ」ではないのか?
よくないインターフェースはどんな形?
bad_request = {
"msg": "返金ポリシーは何ですか"
}
bad_response = {
"text": "7 日以内なら返金可能です"
}
何が問題でしょうか?
msgは何を意味するのか? ユーザーメッセージ? システムメッセージ?trace_idがない- エラー構造がない
- バージョン情報がない
- コンテキスト用のフィールドがない
よい API 設計は何をしているのか?
本質的には、次のことに答えています。
- 入力はどんな形か
- 出力はどんな形か
- 失敗したときどう表すか
- 1回呼んでも10万回呼んでも安定するか
つまり、API 設計は「入口を作る」ことではなく、次を定義することです。
システムと外部世界の契約。
まずはリクエスト構造を設計する
最小のリクエスト構造には、少なくともこれが必要
queryuser_id(任意)session_id(複数ターンのとき)metadata(任意)
もっとわかりやすいリクエストオブジェクト
request = {
"query": "返金ポリシーは何ですか?",
"user_id": 1,
"session_id": "sess_001",
"metadata": {
"channel": "web"
}
}
print(request)
想定出力:
{'query': '返金ポリシーは何ですか?', 'user_id': 1, 'session_id': 'sess_001', 'metadata': {'channel': 'web'}}
これで、次のことがはっきりします。
- 何についての問い合わせか
- 誰から送られたのか
- どの会話に属するのか
- 追加のコンテキストは何か
これは「文字列を1つ渡すだけ」よりずっと良い設計です。
次にレスポンス構造を設計する
なぜレスポンスも規約化する必要があるのか?
実際の呼び出し元は、人だけではありません。たとえば:
- フロントエンド
- 他のサービス
- ログシステム
- 評価システム
これらは、安定した形式で結果を受け取る必要があります。
より安定したレスポンス構造
response = {
"trace_id": "trace_001",
"answer": "コース購入後 7 日以内、かつ学習進捗が 20% 未満であれば返金申請できます。",
"sources": [
{"id": "doc_001", "section": "返金ポリシー"}
],
"usage": {
"prompt_tokens": 120,
"completion_tokens": 35
}
}
print(response)
想定出力:
{'trace_id': 'trace_001', 'answer': 'コース購入後 7 日以内、かつ学習進捗が 20% 未満であれば返金申請できます。', 'sources': [{'id': 'doc_001', 'section': '返金ポリシー'}], 'usage': {'prompt_tokens': 120, 'completion_tokens': 35}}
これらのフィールドに価値がある理由
trace_id:処理の流れを追いやすくなるanswer:実際の業務出力sources:参照元の確認や検証に使えるusage:コスト分析に使える
エラー応答も必ず設計する
多くのシステムは成功時の返却だけを考えがち
でも、実務で多いのはむしろ次のような問題です。
- パラメータが不正
- 上流タイムアウト
- 権限不足
- ナレッジベースが空
統一されたエラー構造
error_response = {
"trace_id": "trace_002",
"error": {
"code": "INVALID_ARGUMENT",
"message": "query は空にできません"
}
}
print(error_response)
想定出力:
{'trace_id': 'trace_002', 'error': {'code': 'INVALID_ARGUMENT', 'message': 'query は空にできません'}}
これはとても重要です。呼び出し側が次のことを明確に判断できるからです。
- 何が起きたのか
- エラーの種類は何か
- リトライする価値があるか
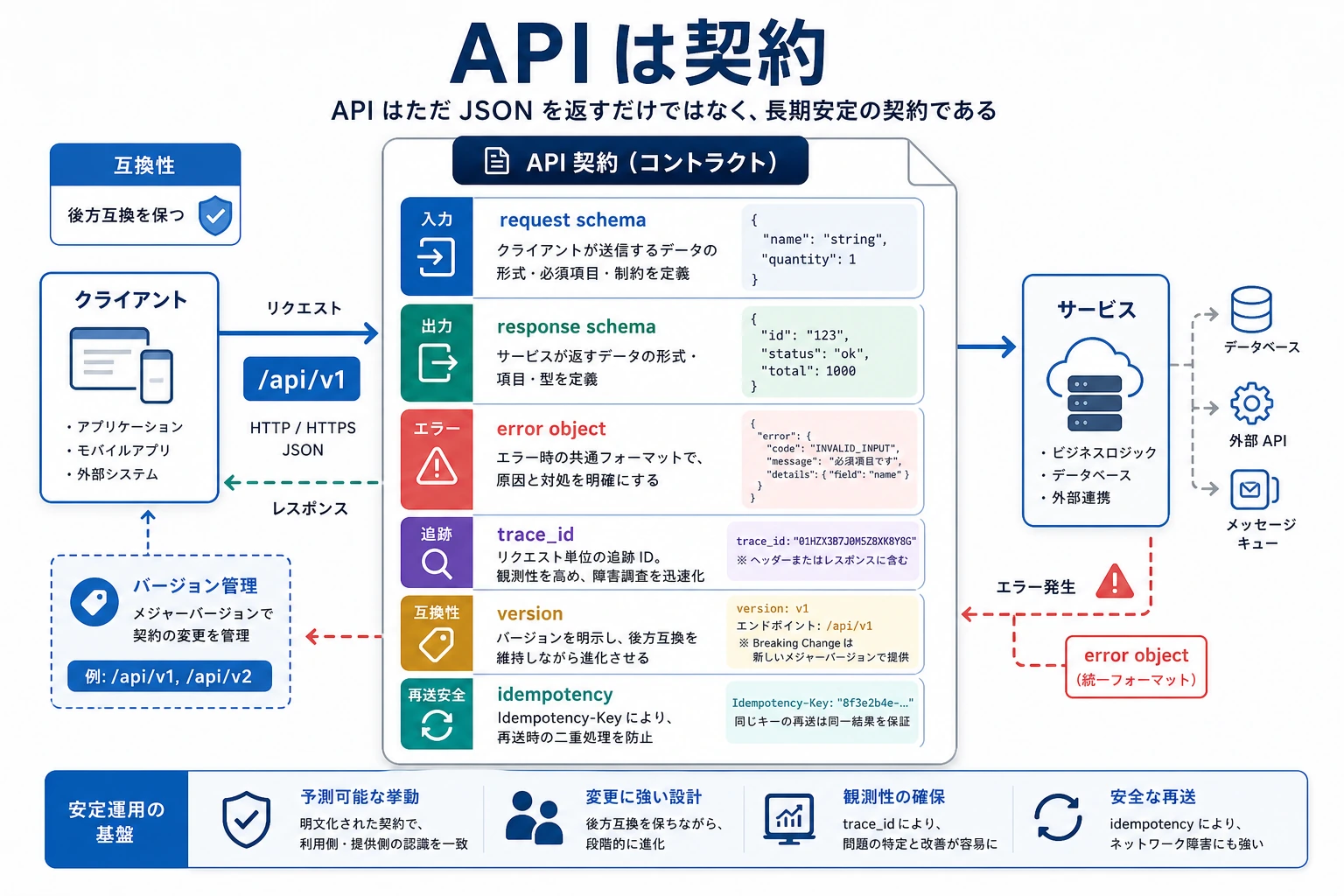
API は単なる JSON ではなく、システムの契約です。図を見るときは request schema、response schema、error object、trace_id、version に注目してください。これらが、フロントエンド、評価システム、他サービスから長期的に安定して使われるかどうかを決めます。
最小で動くサービス化処理関数
純粋な Python で API handler を模擬する
def handle_chat(request):
trace_id = "trace_demo_001"
if "query" not in request or not request["query"].strip():
return {
"trace_id": trace_id,
"error": {
"code": "INVALID_ARGUMENT",
"message": "query は空にできません"
}
}
answer = f"システム応答:{request['query']}"
return {
"trace_id": trace_id,
"answer": answer,
"sources": [],
"usage": {"prompt_tokens": 12, "completion_tokens": 8}
}
print(handle_chat({"query": "返金ポリシーは何ですか?"}))
print(handle_chat({"query": ""}))
想定出力:
{'trace_id': 'trace_demo_001', 'answer': 'システム応答:返金ポリシーは何ですか?', 'sources': [], 'usage': {'prompt_tokens': 12, 'completion_tokens': 8}}
{'trace_id': 'trace_demo_001', 'error': {'code': 'INVALID_ARGUMENT', 'message': 'query は空にできません'}}
このコードは何を教えているのか?
教えているのは、次の3点です。
- まずリクエストを検証する
- すべてのリクエストに
trace_idを付ける - 成功時と失敗時の返却形式を統一する
これが、サービス化設計の最も重要な基礎です。
なぜ冪等性が重要なのか?
冪等性とは?
簡単に言うと、
同じリクエストを何回呼んでも、結果が同じ、または制御可能であること。
これは次のような場面で特に重要です。
- リトライ
- タイムアウト後の再送信
- ネットワークの揺らぎ
どんなインターフェースで特に意識すべきか?
特に重要なのは、次のようなものです。
- 問い合わせチケットの作成
- 支払いの開始
- 注文変更
一方、純粋な QA インターフェースは、もともと「読み取り」に近いので、冪等性は比較的扱いやすいです。
なぜバージョン管理は後回しにできないのか?
API は一度他のシステムに組み込まれると、自由に項目を変えにくい
たとえば、今日の返却が
answer
だったのに、明日いきなり
response_text
に変えると、呼び出し側はすぐ壊れます。
シンプルなバージョン戦略
api_info = {
"version": "v1",
"endpoint": "/api/v1/chat"
}
print(api_info)
想定出力:
{'version': 'v1', 'endpoint': '/api/v1/chat'}
小さなプロジェクトでも、早めにバージョン意識を持つことをおすすめします。
より実際のサービスに近い FastAPI の例
実際のバックエンドに近い書き方を見たいなら、次の最小例が参考になります。
pip install fastapi uvicorn
uvicorn app:app --reload
from fastapi import FastAPI
from pydantic import BaseModel, Field
class ChatRequest(BaseModel):
query: str = Field(min_length=1)
session_id: str | None = None
app = FastAPI()
@app.post("/api/v1/chat")
def chat(payload: ChatRequest):
return {
"trace_id": "trace_demo_002",
"answer": f"システム応答:{payload.query}",
"session_id": payload.session_id,
}
このコードはシンプルですが、直接 dict を受け取るより実サービスに近い形です。ChatRequest はリクエスト schema であり、FastAPI はビジネスロジックに入る前に payload を検証します。本番では通常、認証、統一エラー、ログ、実際の trace_id 生成も追加します。
目標が「ナレッジベース駆動の教材生成アシスタント」なら、API の最小構成はどうなるか?
この種のシステムは、/chat だけでは足りないことが多いです。
少なくとも次のようなインターフェースがあるとよいです。
| インターフェース | 役割 |
|---|---|
/courseware/generate | テーマに基づいて教材の構成や文書を生成する |
/courseware/preview | 構造化された結果を先に確認する |
/documents/ingest | PDF / Word / PPT をアップロードして解析する |
/retrieval/search | 検索結果をデバッグする |
最初に作るときは、より安定した進め方として、だいたい次の順番がよいです。
- まず
generateだけを作る - まずは構造化結果かエクスポートリンクを返す
- その後にデバッグ用インターフェースやバッチ処理を追加する
最小のリクエスト構造は、まずこんな形で定義できます。
generate_request = {
"topic": "割引の応用問題",
"audience": "小学校高学年",
"doc_format": "word",
"style": "授業解説",
"exercise_count": 3,
}
print(generate_request)
想定出力:
{'topic': '割引の応用問題', 'audience': '小学校高学年', 'doc_format': 'word', 'style': '授業解説', 'exercise_count': 3}
このオブジェクトの価値は、次の点にあります。
- 複数ターン対話で集めた項目を、実際のサービス API のパラメータとして落とし込める
実践:教材生成 API の契約を模擬する
本物の FastAPI endpoint を作る前に、まず純粋な Python でリクエスト検証とレスポンス契約を書いてみます。これにより、サービス境界がはっきりします。
REQUIRED_FIELDS = ["topic", "audience", "doc_format", "style", "exercise_count"]
def validate_generate_request(payload):
missing = [field for field in REQUIRED_FIELDS if not payload.get(field)]
if missing:
return False, {
"code": "INVALID_ARGUMENT",
"message": f"不足フィールド:{missing}"
}
if payload["doc_format"] not in {"word", "ppt"}:
return False, {
"code": "INVALID_ARGUMENT",
"message": "doc_format は word または ppt である必要があります"
}
return True, None
def handle_generate(payload):
trace_id = "trace_courseware_001"
ok, error = validate_generate_request(payload)
if not ok:
return {"trace_id": trace_id, "error": error}
return {
"trace_id": trace_id,
"status": "accepted",
"courseware": {
"title": payload["topic"],
"audience": payload["audience"],
"format": payload["doc_format"],
"sections": ["知識ポイント確認", "例題解説", "授業内演習"],
}
}
generate_request = {
"topic": "割引の応用問題",
"audience": "小学校高学年",
"doc_format": "word",
"style": "授業解説",
"exercise_count": 3,
}
print(handle_generate(generate_request))
print(handle_generate({"topic": "割引の応用問題", "doc_format": "pdf"}))
想定出力:
{'trace_id': 'trace_courseware_001', 'status': 'accepted', 'courseware': {'title': '割引の応用問題', 'audience': '小学校高学年', 'format': 'word', 'sections': ['知識ポイント確認', '例題解説', '授業内演習']}}
{'trace_id': 'trace_courseware_001', 'error': {'code': 'INVALID_ARGUMENT', 'message': "不足フィールド:['audience', 'style', 'exercise_count']"}}
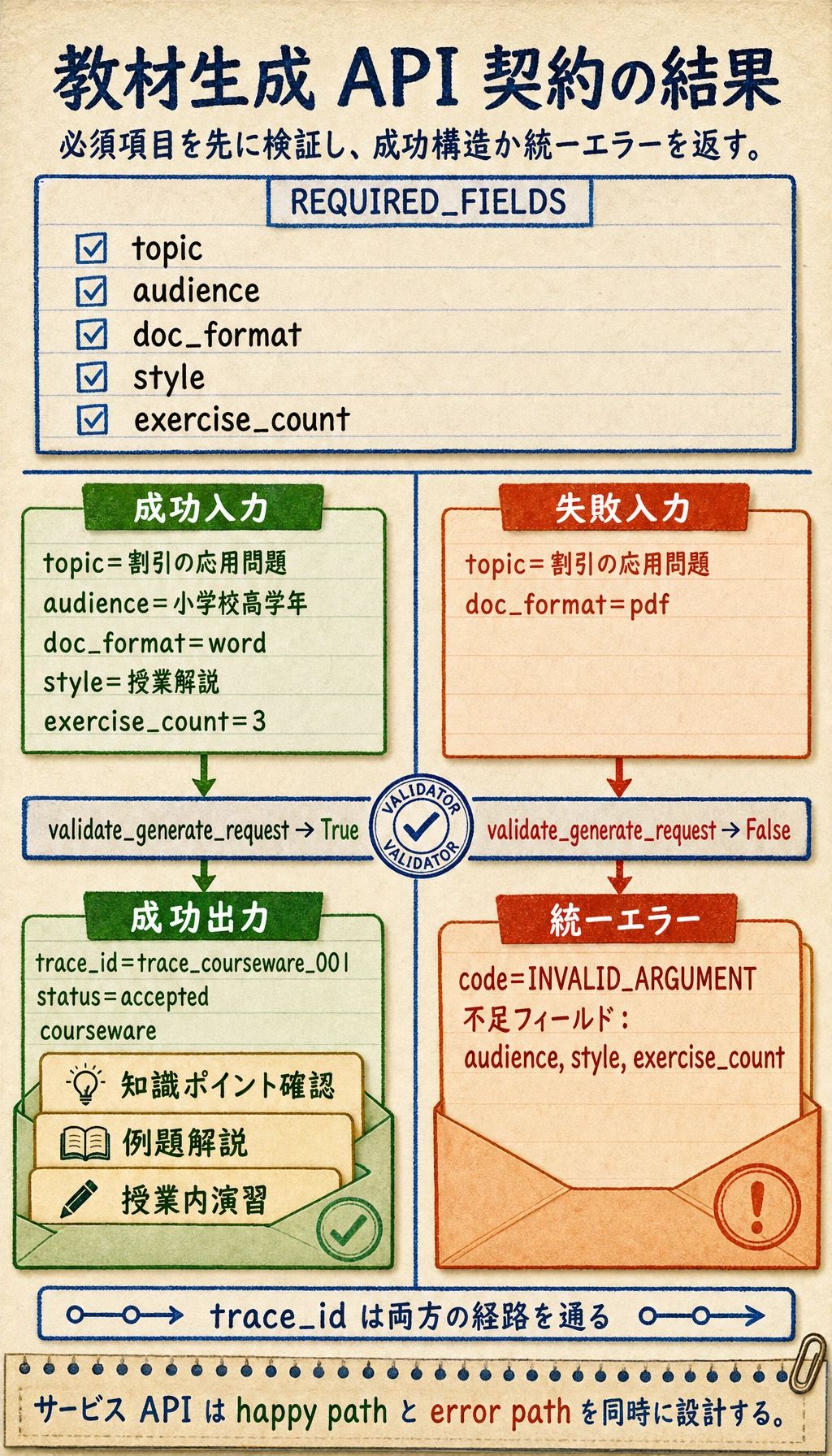
2つの経路を同じ検証ゲートに通して読みます。完全な payload は status=accepted の courseware になり、不完全な payload はビジネスロジックの前で統一された INVALID_ARGUMENT エラーに止まります。
この練習が役立つのは、成功と失敗を同時に設計する必要があるからです。happy path の返却だけでは、サービスが準備できたとは言えません。
初学者がよくつまずくポイント
リクエスト構造が雑すぎる
最初は楽でも、後でとても苦しくなります。
エラー構造が統一されていない
フロントエンドや他サービスとの接続がどんどん難しくなります。
trace_id がない
問題が起きたときに、処理の流れを追えません。
最初からインターフェースを単一の業務ロジックに固定しすぎる
後からの拡張がかなり難しくなります。
まとめ
この節で最も大事なのは、インターフェースを動かすことそのものではなく、次を理解することです。
API 設計の本質は、入力、出力、エラー、トレース情報を安定したシステム契約にすること。
契約がはっきりしていれば、サービスは他人に長く安定して使われるようになります。
練習
handle_chat()にsession_idフィールドのサポートを追加してみましょう。INVALID_ARGUMENT、TIMEOUT、NOT_FOUNDのような統一エラーコード列挙を設計してみましょう。- 考えてみましょう:もしこれが「チケット作成」インターフェースなら、冪等性をどう考えますか?
- 自分の言葉で説明してみましょう。なぜ API 設計は本質的にシステム契約を定義することだと言えるのでしょうか?