6.7.3 訓練モニタリングと診断
この節の位置づけ
訓練診断とは、症状と根本原因を分けることです。最初からモデルを変えないでください。まずカーブを読み、予測と勾配を見て、データを確認し、最後に 1 つの targeted fix を選びます。
学習目標
- カーブから underfitting、overfitting、不安定な訓練を分類できる。
- prediction distribution と gradient norm を確認できる。
- 繰り返し使える troubleshooting order を使える。
- evidence から次の実験を 1 つ決められる。
- 各 training run で何を保存すべきか分かる。
まずカーブを見る
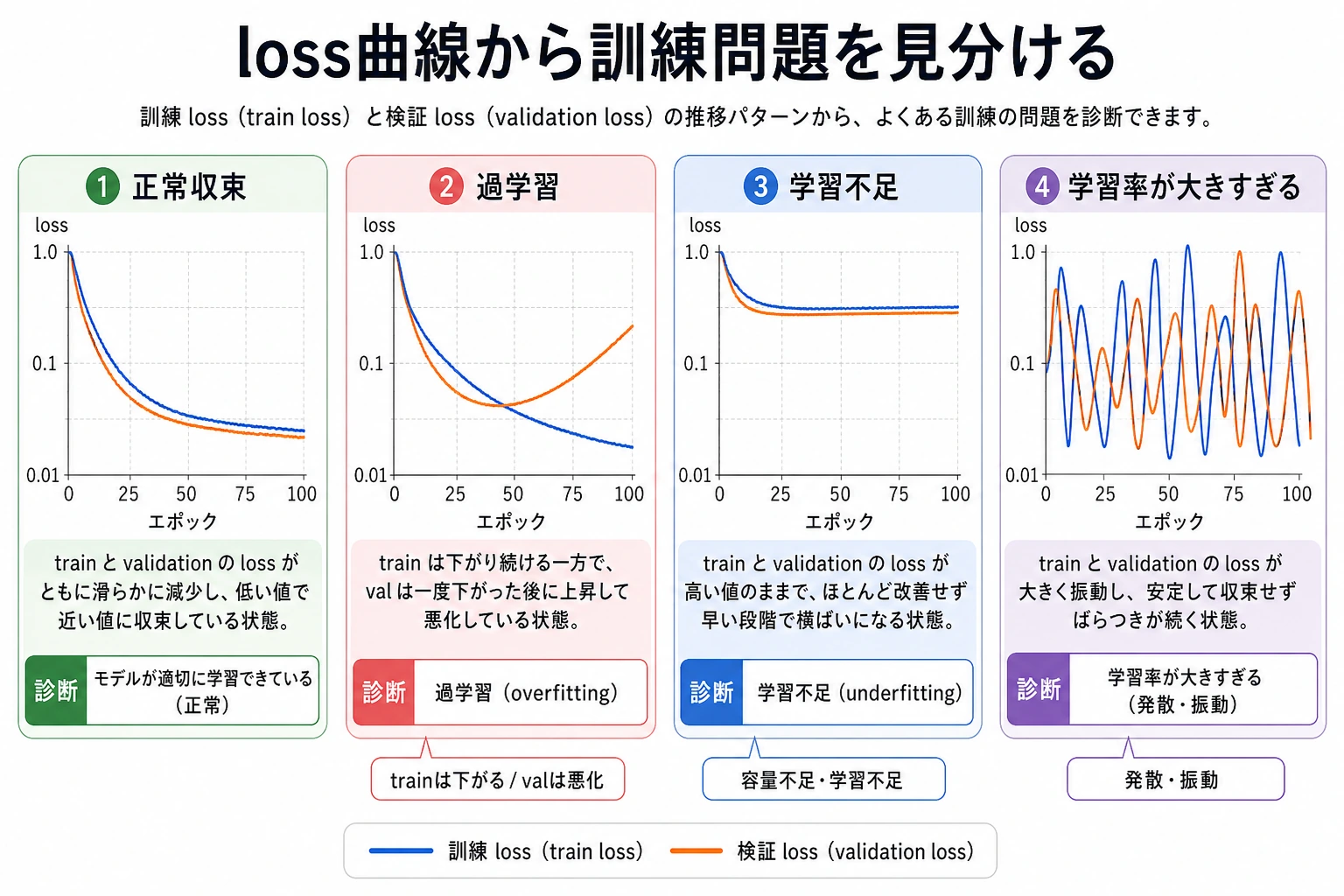
最初の質問は「どのモデルに変えるか」ではありません。
訓練 evidence には、どんな症状が見えているか?
| 症状 | ありそうな方向 | 最初に見るもの |
|---|---|---|
| train も val も悪い | underfitting | learning rate、model capacity、data quality |
| train は良いが val が悪化する | overfitting | regularization、data split、augmentation |
| loss が上下に跳ねる | instability | learning rate、batch size、gradients |
| prediction がほぼ 1 class | collapse または data issue | labels、class balance、output layer |
| metric が急に変わる | pipeline bug または distribution shift | data loader、preprocessing、validation split |
実験 1:カーブパターンを分類する
histories = {
"underfit_case": ([1.20, 1.08, 0.99, 0.94], [1.25, 1.13, 1.04, 1.02]),
"overfit_case": ([0.90, 0.55, 0.31, 0.18], [0.92, 0.63, 0.68, 0.82]),
"unstable_case": ([0.80, 1.65, 0.72, 1.48], [0.85, 1.70, 0.79, 1.55]),
}
def diagnose(train, val):
train_drop = train[0] - train[-1]
val_best = min(val)
if max(train) - min(train) > 0.8:
return "possible_lr_too_high_or_unstable_batches"
if train[-1] > 0.8 and val[-1] > 0.8:
return "possible_underfitting"
if train_drop > 0.3 and val[-1] > val_best + 0.1:
return "possible_overfitting"
return "need_more_signals"
print("curve_diagnosis")
for name, (train, val) in histories.items():
print(name, "->", diagnose(train, val))
期待される出力:
curve_diagnosis
underfit_case -> possible_underfitting
overfit_case -> possible_overfitting
unstable_case -> possible_lr_too_high_or_unstable_batches
この code は人の判断を置き換えるためのものではありません。最初に、見えている症状を分類してから system を変える、という習慣を作るためのものです。
実験 2:勾配と予測分布を確認する
loss だけでは不十分です。loss がそこそこに見えても、すべての sample を同じ class と予測していることがあります。
import torch
from torch import nn
torch.manual_seed(5)
X = torch.randn(12, 3)
y = torch.tensor([0, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0])
model = nn.Sequential(nn.Linear(3, 4), nn.ReLU(), nn.Linear(4, 2))
loss_fn = nn.CrossEntropyLoss()
logits = model(X)
loss = loss_fn(logits, y)
loss.backward()
grad_norm = 0.0
for p in model.parameters():
if p.grad is not None:
grad_norm += p.grad.pow(2).sum().item()
grad_norm = grad_norm**0.5
preds = logits.argmax(dim=1)
counts = torch.bincount(preds, minlength=2)
confidence = torch.softmax(logits, dim=1).max(dim=1).values.mean().item()
print("training_signals")
print("loss:", round(loss.item(), 3))
print("grad_norm:", round(grad_norm, 3))
print("pred_counts:", counts.tolist())
print("avg_confidence:", round(confidence, 3))
期待される出力:
training_signals
loss: 0.687
grad_norm: 0.445
pred_counts: [0, 12]
avg_confidence: 0.69

重要な signal は pred_counts: [0, 12] です。この初期 model はすべての sample を class 1 と予測しています。実際の訓練でこの pattern が続く場合、class imbalance、labels、output layer shape、loss setup を確認してください。
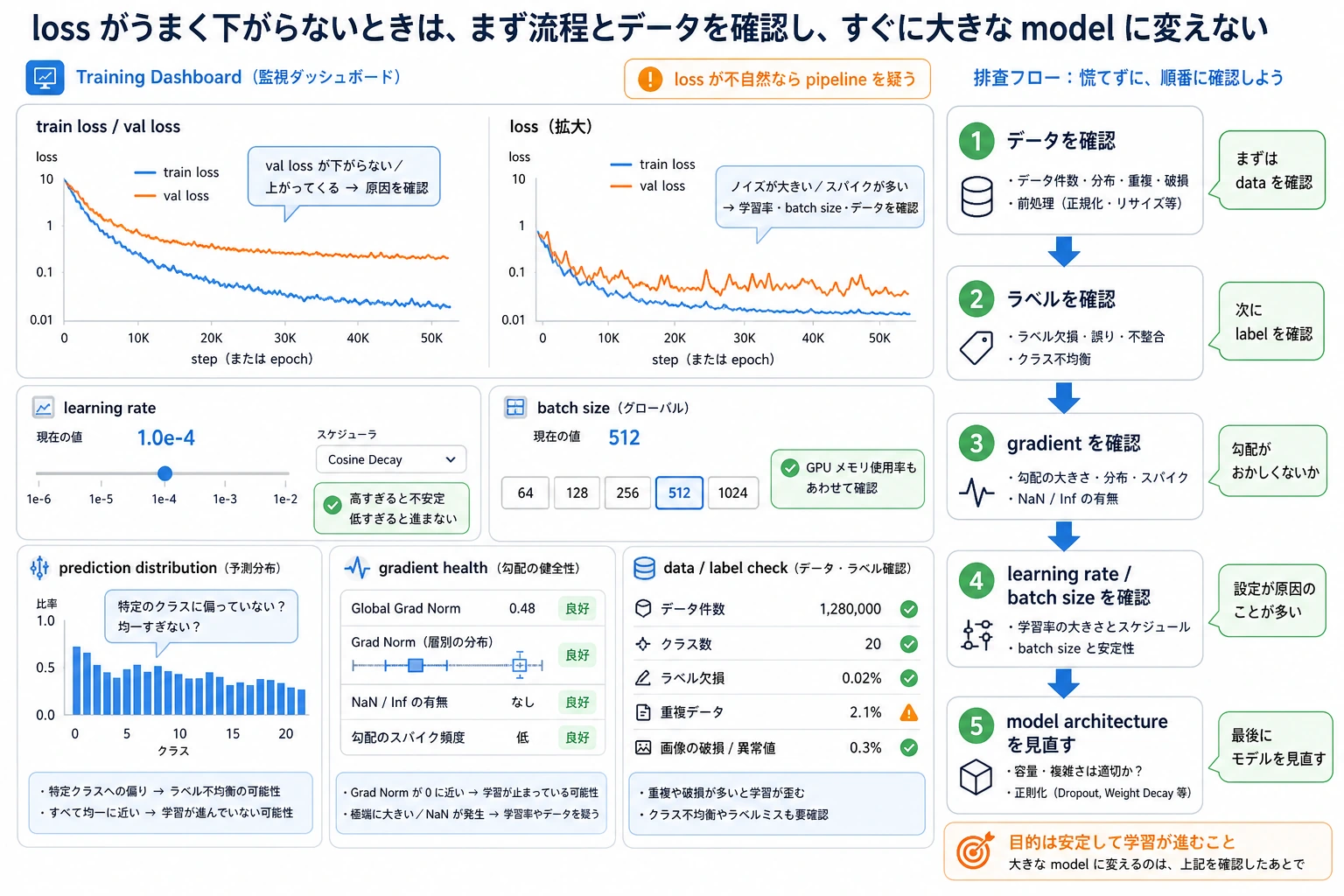
Troubleshooting Order
architecture を変える前に、この順番で確認します。
- Curves:train/val loss と metrics。
- Predictions:class counts、confidence、best/worst examples。
- Gradients:norm、NaN/Inf、exploding または near-zero updates。
- Data:labels、leakage、split、preprocessing、augmentation。
- Hyperparameters:learning rate、batch size、regularization。
- Model:capacity、architecture、initialization。
この順番は地味です。だからこそ効きます。
訓練中に保存するもの
| Artifact | 保存する理由 |
|---|---|
| train/val curves | trend と overfitting を診断する |
| config and seed | run を再現する |
| best checkpoint | retrain なしで比較する |
| prediction samples | failure を直接見る |
| gradient statistics | instability を早く見つける |
| data split version | leakage や drift を検出する |
診断から Action へ
| Diagnosis | 最初の action |
|---|---|
| possible underfitting | LR を適度に上げる、長く訓練する、capacity を増やす、labels を確認する |
| possible overfitting | early stopping、強めの regularization、data 追加、augmentation |
| unstable training | LR を下げる、batch を増やす、gradient clipping |
| prediction collapse | class balance、target encoding、output shape、loss function を確認する |
| data pipeline issue | sample batch を表示し、preprocessing と split を確認する |
よくある間違い
| 間違い | 直し方 |
|---|---|
| 最終 accuracy だけを見る | full curves と best epoch を保存する |
| data 確認前に model を変える | sample batch と labels を先に見る |
| prediction distribution を無視する | class counts や output summary を表示する |
| train loss が低ければ成功だと思う | validation と failure cases を比較する |
| 複数の修正を同時に入れる | 1 つの action を選び、結果を検証する |
練習
- train と val が両方改善する
good_casehistory を追加してください。 - 実験 2 を 3 class にしてください。
torch.bincountはどう変わりますか。 has_nan_gradを報告する check を追加してください。- 実験 1 の各 diagnosis について、次の action を 1 つ書いてください。
epoch,train_loss,val_loss,val_acc形式の CSV 風 log を保存してください。
まとめ
- 症状は根本原因ではありません。
- カーブは最初の診断画面です。
- 予測と勾配は、loss が隠す失敗を見せてくれます。
- data check は architecture change より先です。
- 良い診断は、最後に 1 つの targeted next experiment へ落ちます。