8.4.5 容器化与部署
很多项目到这里会卡住:
- 本地能跑
- 换台机器就不行
- 团队同事环境不一致
- 上线后依赖版本乱成一团
容器化的核心价值,就是让你的应用从:
“在我电脑上能跑”
走向:
“在约定环境里稳定可复制地运行”。
学习目标
- 理解为什么 LLM 应用特别适合容器化
- 看懂一个最小 Dockerfile 的关键结构
- 理解镜像、容器、端口、环境变量这些核心概念
- 看懂一个小型 Docker Compose 启动方式
- 理解容器化不是部署的终点,而是部署的起点
新人术语桥
Docker 一开始吓人,很多时候只是名词太多。先把这些词分开:
| 术语 | 新人理解 | 为什么重要 |
|---|---|---|
image | 镜像,打包好的运行模板,像“菜谱 + 食材包” | 先构建镜像,再从镜像启动容器 |
container | 容器,从镜像启动出来的运行实例 | 真正对外提供服务的是它 |
Dockerfile | 构建镜像的说明书 | 记录基础镜像、依赖、文件和启动命令 |
port | 服务接收请求的门口 | -p 8000:8000 是把宿主机端口映射到容器端口 |
environment variable | 环境变量,从代码外部注入的配置 | API key、模型名、运行模式不应该写死在代码里 |
Compose | 一次启动多个相关容器的工具 | 应用需要向量库、Redis、Postgres 时尤其有用 |
核心不是死记 Docker 命令,而是让运行环境可复现。
为什么要容器化?
本地脚本最大的隐患是什么?
你本地能跑通一个项目,往往依赖了很多隐含条件:
- Python 版本
- 包版本
- 系统依赖
- 环境变量
- 启动命令
这些条件一旦换人、换机器、换服务器,就很容易出问题。
容器化到底解决什么?
容器化的核心价值是:
把应用和它依赖的运行环境一起打包。
这样你就能更稳定地复现:
- 安装了什么
- 用了什么版本
- 用什么命令启动
这对 LLM 应用特别重要,因为它们经常依赖:
- Web 框架
- 模型服务
- 向量库
- 系统工具
镜像和容器到底是什么?
一个非常实用的类比
- 镜像(image):像菜谱 + 食材包
- 容器(container):按这个菜谱真正做出来的一锅菜
也就是说:
- 镜像是静态模板
- 容器是运行中的实例
为什么这个区分很重要?
因为部署时你通常会:
- 先构建镜像
- 再启动容器
如果这个顺序没想清楚,后面看 Docker 命令会一直晕。
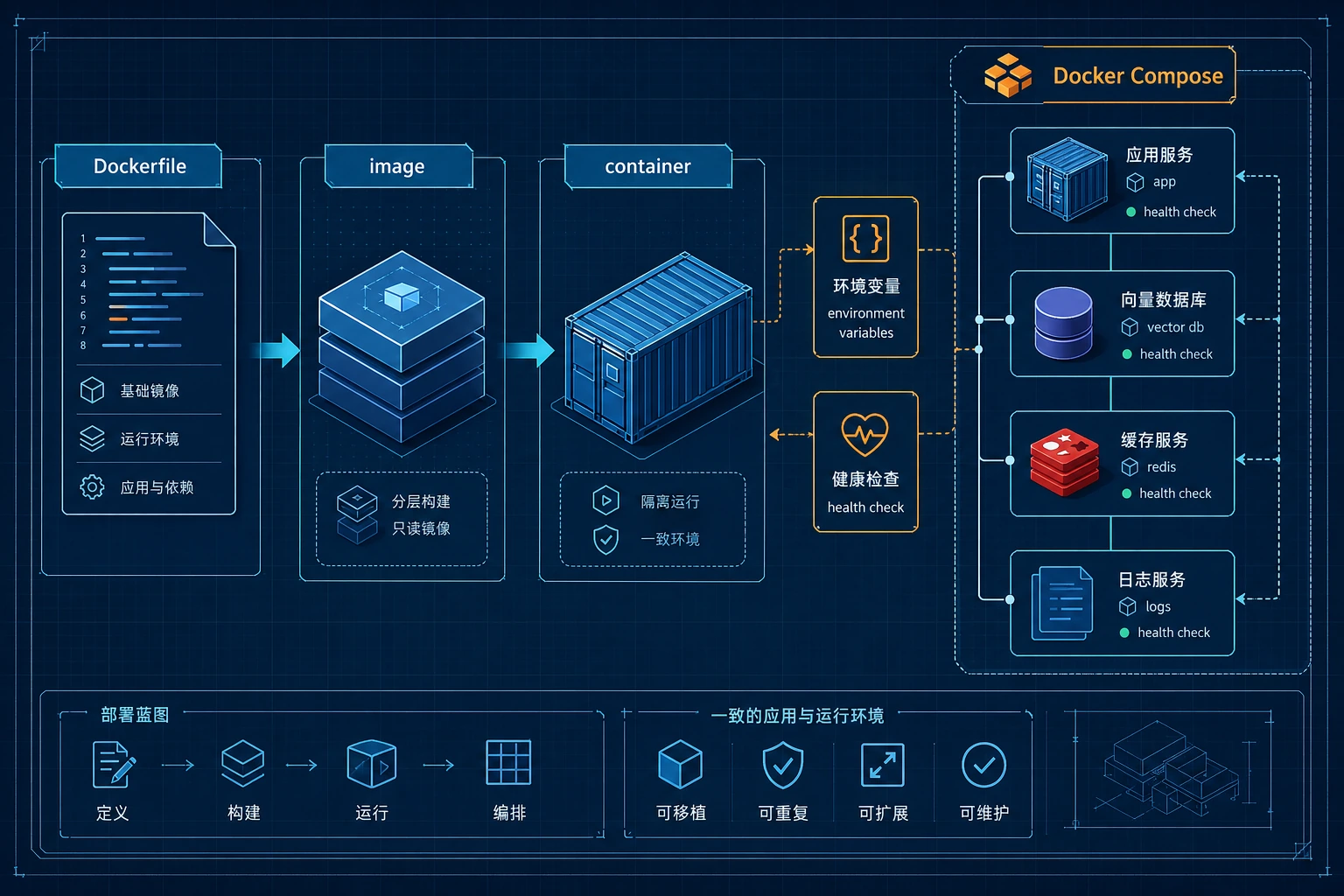
镜像是可复现的运行模板,容器是运行实例,Compose 负责把多个服务一起启动。对 LLM 应用来说,还要把环境变量、健康检查、向量库和日志纳入部署图。
一个最小 Dockerfile 到底长什么样?
先看完整示例
FROM python:3.14-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["python", "app.py"]
每一行在做什么?
-
FROM- 选择基础镜像
-
WORKDIR- 指定工作目录
-
COPY requirements.txt .- 把依赖文件拷进去
-
RUN pip install ...- 安装依赖
-
COPY . .- 再把项目代码拷进去
-
EXPOSE 8000- 说明服务对外监听的端口
-
CMD- 容器启动时默认执行的命令
这就是 Dockerfile 最核心的骨架。
本节使用 python:3.14-slim,这是本轮课程更新时的当前稳定 Python 版本线。如果你的项目依赖库还没完全适配,可以固定到经过测试的 python:3.13-slim 或 python:3.11-slim,但要在部署说明里写清楚原因。
先准备一个真正能跑的小应用
最小 Python 服务
为了让后面的 Docker 部署例子更具体,我们先写一个非常简单的 app.py。
# app.py
from http.server import BaseHTTPRequestHandler, HTTPServer
import json
class Handler(BaseHTTPRequestHandler):
def do_GET(self):
if self.path == "/health":
self.send_response(200)
self.send_header("Content-Type", "application/json")
self.end_headers()
self.wfile.write(json.dumps({"status": "ok"}).encode())
return
self.send_response(200)
self.send_header("Content-Type", "application/json")
self.end_headers()
self.wfile.write(json.dumps({"message": "hello from llm app"}).encode())
server = HTTPServer(("0.0.0.0", 8000), Handler)
print("serving on 8000")
server.serve_forever()
先在本地运行:
python app.py
再打开另一个终端测试服务:
curl http://localhost:8000/
curl http://localhost:8000/health
预期输出:
{"message": "hello from llm app"}
{"status": "ok"}
为什么先写这个?
因为容器化不是空讲 Dockerfile, 而是要围绕一个真正会运行的应用去理解。
再把它容器化
配套 requirements.txt
这个最小服务不依赖第三方包,所以可以是空文件,或者甚至不需要它。 但为了贴近真实项目,我们还是保留结构。
# requirements.txt
对应 Dockerfile
FROM python:3.14-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY app.py .
EXPOSE 8000
CMD ["python", "app.py"]
运行命令
docker build -t mini-llm-app .
docker run -p 8000:8000 mini-llm-app
然后你访问:
http://localhost:8000/http://localhost:8000/health
就能看到返回结果。
也可以用命令行验证:
curl http://localhost:8000/
curl http://localhost:8000/health
预期输出:
{"message": "hello from llm app"}
{"status": "ok"}
这就是最小容器化闭环。
环境变量为什么重要?
LLM 应用里经常有这些配置:
- API Key
- 模型名
- 向量库地址
- 运行模式
这些通常不应写死在代码里,而更适合走环境变量。
一个最小示例
import os
model_name = os.getenv("MODEL_NAME", "demo-model")
port = int(os.getenv("PORT", "8000"))
print("MODEL_NAME =", model_name)
print("PORT =", port)
不额外传环境变量时,预期输出:
MODEL_NAME = demo-model
PORT = 8000
Docker 里怎么传环境变量?
docker run -p 8000:8000 -e MODEL_NAME=qwen-demo mini-llm-app
这一步很关键,因为真实部署里几乎离不开配置注入。
如果想让服务返回配置,也可以在 app.py 里读取 MODEL_NAME 并从根接口返回。核心思想不变:代码保持稳定,配置在镜像外部变化。
为什么 Compose 很常用?
因为真实项目往往不止一个服务
一个 LLM 应用很可能还要搭配:
- Web 服务
- 向量数据库
- Redis
- Postgres
如果每个都手写 docker run,会很乱。
一个最小 Compose 示例
version: "3.9"
services:
app:
build: .
ports:
- "8000:8000"
environment:
MODEL_NAME: demo-model
启动方式:
docker compose up --build
这就是为什么 Compose 在本地开发和小型部署里非常实用。
容器化不等于部署完成
这是一个很常见的误解。
容器化解决的是“打包和运行环境”
但真正上线还要继续考虑:
- 日志
- 健康检查
- 资源限制
- 自动重启
- 灰度更新
- 反向代理
一个很重要的健康检查思路
像前面的:
/health
这种接口就很有价值。 因为部署系统通常要知道:
这个容器现在是不是活着、是不是能收请求。
初学者最常踩的坑
把所有东西都写进一个巨大镜像
镜像会变得很臃肿。
没有健康检查
服务坏了也不知道。
配置写死在代码里
一换环境就容易出问题。
以为容器化之后就自动可扩展
不是。 容器化只是第一步,后面还有编排、监控和运维。
忽略本地 Docker 磁盘占用
如果构建时报 no space left on device,先看 Docker 存储占用:
docker system df
docker builder prune
只清理你确认不再需要的内容。团队机器或 CI 环境里,通常先清构建缓存,比直接删镜像或 volume 更稳。
小结
这一节最重要的不是背 Docker 命令,而是理解:
容器化的核心价值,是把“应用 + 依赖 + 启动方式”一起标准化,让部署从个人电脑经验变成可复制流程。
这一步做稳了,后面的服务编排和线上运维才有基础。
练习
- 用本节的
app.py和 Dockerfile 在本地真正构建一个最小镜像。 - 给服务再加一个环境变量,比如
APP_MODE=dev。 - 想一想:为什么说
/health接口对部署系统很重要? - 用自己的话解释:为什么容器化是部署的起点,而不是终点?