8.2.4 统一 API 接口
一旦你的系统不只接一个模型,问题很快就会冒出来:
- 不同 provider 的参数名不一样
- 返回结构不一样
- 错误处理不一样
这时真正有价值的就不是“再接一个模型”,而是:
先把模型调用入口统一起来。
学习目标
- 理解为什么多模型系统需要统一 API 层
- 理解统一 API 接口在工程上到底省了什么
- 看懂一个最小 provider 抽象示例
- 明白统一 API 不等于“所有模型都完全一样”
先建立一张地图
如果你已经学过本地模型运行和推理服务,这一节最自然的续接就是:
- 前面你已经知道模型怎样被加载和服务化
- 这一节开始回答:一旦系统接多个模型 / 多个 provider,怎样不让上层业务代码变乱
所以统一 API 这一节真正重要的不是“再包一层接口”,而是:
- 给多模型系统建立一个稳定入口层
统一 API 这节最适合新人的理解顺序不是“再包一层接口”,而是先看清:
所以这节真正想解决的是:
- 为什么多模型系统一定会自然长出一层抽象
- 为什么业务代码不该到处知道 provider 差异
一个更适合新人的总类比
你可以把统一 API 理解成:
- 给很多不同品牌的插头做一个统一转接头
如果没有这层转接头, 上层业务代码就会变成:
- 这里适配 A 厂商
- 那里适配 B 厂商
- 再另一处适配本地模型
最后系统会越来越碎。 统一 API 最重要的价值,就是把这些差异收拢在一层里。
一、为什么统一 API 会变得重要?
当你只有一个模型时,还不明显
如果你的项目里只有一个模型,一个简单 client 往往就够了。
一旦开始多模型 / 多 provider
你就会面对这些问题:
- A 模型叫
messages - B 模型叫
prompt - 有的返回
content - 有的返回
output_text - 有的 token 统计字段也不同
这时业务代码会迅速变得很乱。
所以统一 API 的核心价值可以先记成:
把 provider 差异收拢到一层,而不是让业务层到处知道这些差异。
第一次学统一 API,最该先抓住什么?
最该先抓住的不是“抽象得多漂亮”,而是这句:
统一 API 的核心价值,是把模型差异隔离掉,让业务层面对稳定接口。
这句话一旦稳住,后面你看:
- provider 适配
- 路由
- fallback
- 统一日志
都会更自然地知道它们为什么会长在这一层。
二、统一 API 最常见的目标是什么?
通常至少包括:
- 统一请求结构
- 统一响应结构
- 统一错误处理
- 统一日志与 trace
一个最小统一请求结构
request = {
"provider": "demo_provider",
"model": "demo-chat-model",
"query": "退款政策是什么?"
}
print(request)
预期输出:
{'provider': 'demo_provider', 'model': 'demo-chat-model', 'query': '退款政策是什么?'}
一个最小统一响应结构
response = {
"provider": "demo_provider",
"model": "demo-chat-model",
"answer": "课程购买后 7 天内且学习进度低于 20% 可退款。",
"usage": {
"prompt_tokens": 24,
"completion_tokens": 18
}
}
print(response)
预期输出:
{'provider': 'demo_provider', 'model': 'demo-chat-model', 'answer': '课程购买后 7 天内且学习进度低于 20% 可退款。', 'usage': {'prompt_tokens': 24, 'completion_tokens': 18}}
这样做的好处是:
- 上层业务逻辑只面对一套稳定结构
一个很适合初学者先记的统一表
| 层 | 这一层最该统一什么 |
|---|---|
| 请求 | query / model / provider / 参数格式 |
| 响应 | answer / usage / error |
| 日志 | trace_id / provider / latency / token |
| 错误 | error_code / message / retryable |
这个表很适合新人,因为它能把“统一 API”从一个抽象名词重新拉回成几类可见对象。
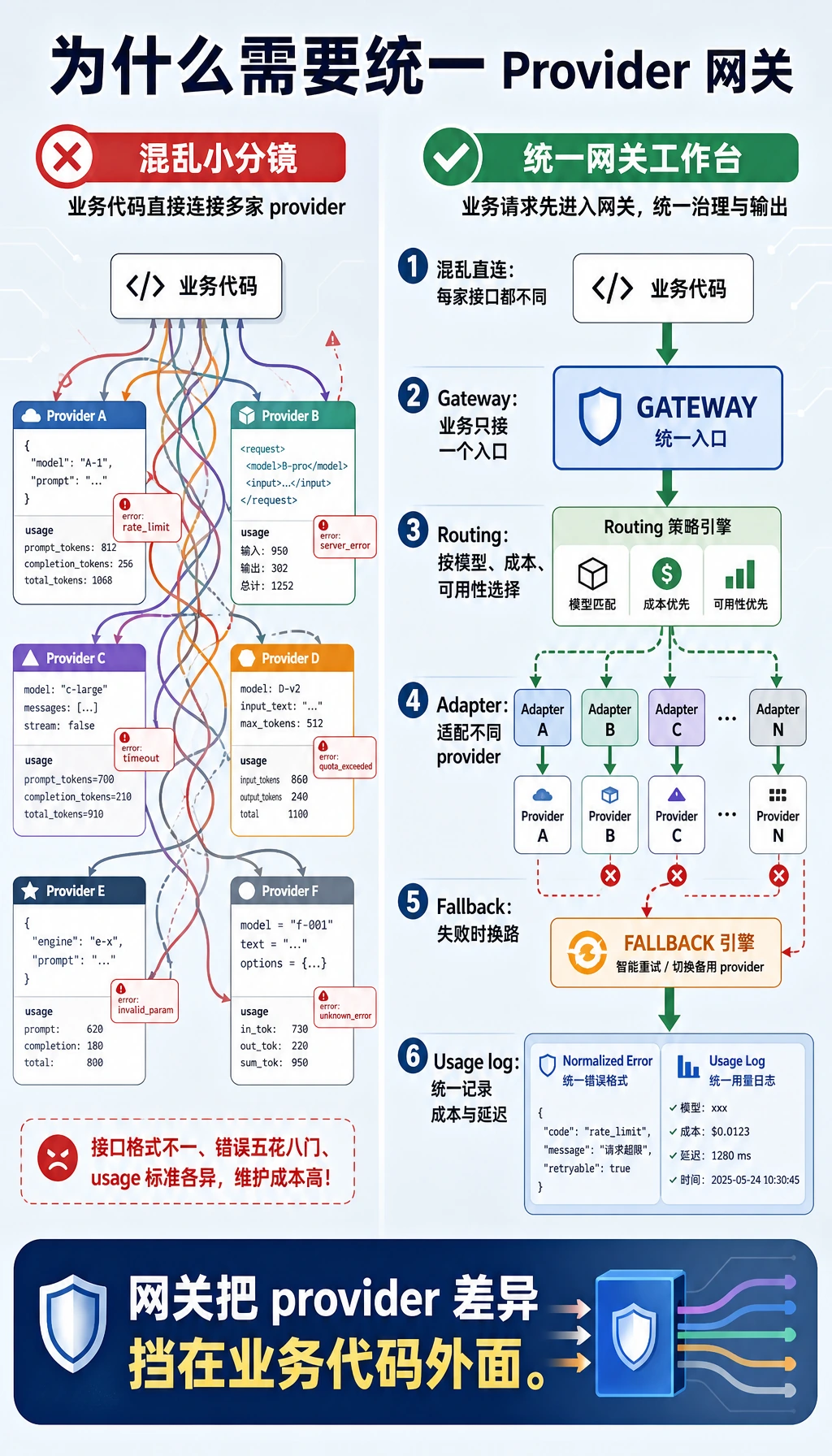
统一 API 层像模型网关:上层业务只发统一请求,网关内部再处理 provider 适配、模型路由、fallback、usage 统计和统一错误结构。
三、一个最小 provider 抽象示例
class ProviderA:
def chat(self, query, model):
return {
"text": f"A-provider reply: {query}",
"tokens": 30
}
class ProviderB:
def generate(self, prompt, model_name):
return {
"output_text": f"B-provider reply: {prompt}",
"usage": {"total_tokens": 28}
}
如果你直接让业务代码分别去调这两个 provider,代码会越来越碎。
四、统一适配层到底在做什么?
把不同 provider 翻译成同一种结构
class ProviderA:
def chat(self, query, model):
return {
"text": f"A-provider reply: {query}",
"tokens": 30
}
class ProviderB:
def generate(self, prompt, model_name):
return {
"output_text": f"B-provider reply: {prompt}",
"usage": {"total_tokens": 28}
}
class UnifiedClient:
def __init__(self):
self.providers = {
"provider_a": ProviderA(),
"provider_b": ProviderB()
}
def chat(self, provider, query, model):
if provider == "provider_a":
raw = self.providers[provider].chat(query=query, model=model)
return {
"provider": provider,
"model": model,
"answer": raw["text"],
"usage": {"total_tokens": raw["tokens"]}
}
if provider == "provider_b":
raw = self.providers[provider].generate(prompt=query, model_name=model)
return {
"provider": provider,
"model": model,
"answer": raw["output_text"],
"usage": raw["usage"]
}
return {"error": "unknown_provider"}
client = UnifiedClient()
print(client.chat("provider_a", "退款政策是什么?", "demo-1"))
print(client.chat("provider_b", "退款政策是什么?", "demo-2"))
预期输出:
{'provider': 'provider_a', 'model': 'demo-1', 'answer': 'A-provider reply: 退款政策是什么?', 'usage': {'total_tokens': 30}}
{'provider': 'provider_b', 'model': 'demo-2', 'answer': 'B-provider reply: 退款政策是什么?', 'usage': {'total_tokens': 28}}
这段代码真正重要的不是语法,而是分层
它在告诉你:
- provider 差异应该尽量收拢在统一适配层
- 上层业务代码最好只看到统一接口
这就是“统一 API”最实际的工程价值。
为什么这层特别适合承担日志、统计和路由?
因为它天然站在“所有请求都会经过”的入口位置。 所以像这些能力都很适合长在这里:
- token / 成本统计
- trace 和日志
- provider fallback
- 模型路由
再看一个最小“统一错误结构”示例
def normalize_error(provider, error_type, message):
return {
"provider": provider,
"ok": False,
"error": {
"type": error_type,
"message": message,
"retryable": error_type in {"timeout", "rate_limit"},
},
}
print(normalize_error("provider_a", "timeout", "request timed out"))
预期输出:
{'provider': 'provider_a', 'ok': False, 'error': {'type': 'timeout', 'message': 'request timed out', 'retryable': True}}
这个示例很适合初学者,因为它会帮助你意识到:
- 真正难维护的常常不是成功返回
- 而是不同 provider 出错时怎么还能对上层保持同一种契约
五、为什么统一 API 不等于“所有模型完全一样”?
这是一个特别容易误解的点。
统一 API 的目标不是假装所有模型没有区别,而是:
把共性抽出来,把差异控制在有限边界内。
例如不同模型仍然可能在这些方面有差异:
- 上下文长度
- 支持的工具调用能力
- 多模态能力
- 输出格式约束能力
所以统一 API 更像:
- 统一入口
- 不是统一能力
六、为什么路由(routing)会自然出现在这一层?
一旦有统一 API 层,接下来很自然就会问:
- 哪类请求该去哪个模型?
- 便宜模型够不够?
- 高风险请求要不要走更强模型?
一个简单路由示例
def route_model(query):
if "总结" in query or "改写" in query:
return "provider_a", "cheap-model"
return "provider_b", "strong-model"
for q in ["帮我总结这段话", "退款政策是什么?"]:
print(q, "->", route_model(q))
预期输出:
帮我总结这段话 -> ('provider_a', 'cheap-model')
退款政策是什么? -> ('provider_b', 'strong-model')
统一 API 层很适合承担这种“模型路由入口”角色。
七、统一 API 层最常见的工程收益
更容易切模型
你不用每个业务模块都改一遍。
更容易打日志和做成本统计
因为所有请求都经过同一入口。
更容易做灰度和 fallback
例如:
- 主模型失败后切备用模型
- 特定请求走便宜模型
这都是统一入口特别容易发挥价值的地方。
一个很适合初学者先记的选择表
| 系统现象 | 统一 API 层更适合先补什么 |
|---|---|
| provider 越来越多 | 请求 / 响应统一 |
| 日志越来越难看懂 | trace 和统一日志 |
| 成本不好统计 | usage 统一 |
| 模型切换太痛苦 | 路由和 fallback |
这个表很适合新人,因为它会把“为什么要做统一 API”直接和真实工程痛点对应起来。
新人第一次做多模型系统时,最稳的顺序
更稳的顺序通常是:
- 先把请求结构统一
- 再把响应结构统一
- 再统一错误和日志
- 最后再谈模型路由
这样接口层会比一开始就做复杂路由更稳定。
九、最常见的误区
以为统一 API 就能抹平所有模型差异
不会。 差异依然在,只是你把它们组织得更可控了。
过早设计得太重
如果项目只有一个 provider,过度抽象反而可能是负担。
统一了输入输出,却没统一错误结构和日志
这样后面排障还是会痛苦。
小结
这一节最重要的不是写出一个 UnifiedClient,而是理解:
统一 API 层的核心价值,在于把多 provider 差异收敛到有限边界里,让上层业务面对稳定契约。
这一步做稳之后,多模型路由、fallback、成本优化这些工程能力才更容易做起来。
这节最该带走什么
- 统一 API 是工程分层,不是语法包装
- 它的价值在于把差异压缩到一层
- 多模型、多 provider 一旦出现,这层几乎一定会自然出现
如果把它做成项目或系统设计,最值得展示什么
最值得展示的通常不是:
- “我写了一个 UnifiedClient”
而是:
- 统一前和统一后的调用差异
- 请求 / 响应 / 错误结构是怎么被收拢的
- 路由和 fallback 为什么会自然长在这一层
- 这层如何帮助成本统计和日志治理
这样别人会更容易看出:
- 你理解的是统一入口层的系统价值
- 不只是封装了一个类
练习
- 给
UnifiedClient再加一个统一错误结构。 - 想一想:为什么说统一 API 是“统一入口”,而不是“统一能力”?
- 如果你的系统暂时只接一个模型,为什么不一定要过早做很重的统一抽象?
- 用自己的话解释:为什么统一 API 层很适合承接模型路由和 fallback?