8.1.7 高级 RAG 架构
学习目标
完成本节后,你将能够:
- 理解基础 RAG 在复杂场景下为什么会不够用
- 认识路由式、多跳式、Agentic RAG 等常见架构
- 跑通一个“多知识库路由”的玩具示例
- 知道什么时候该升级 RAG 架构,什么时候不该
一、为什么基础 RAG 迟早会遇到上限?
基础 RAG 适合“单次问题 -> 单次检索 -> 单次回答”
这对很多 FAQ 和简单问答已经够用。 但当问题变复杂时,就会出现瓶颈。
例如:
- 需要跨多个知识库
- 需要先查制度,再查具体产品文档
- 需要拆成多个子问题
常见复杂场景
比如用户问:
“这个学员能不能退款?如果不能,还有没有延期方案?”
这其实隐含了多个动作:
- 查退款政策
- 判断当前条件是否满足
- 再查延期方案
这时“只检索一次”往往不够。
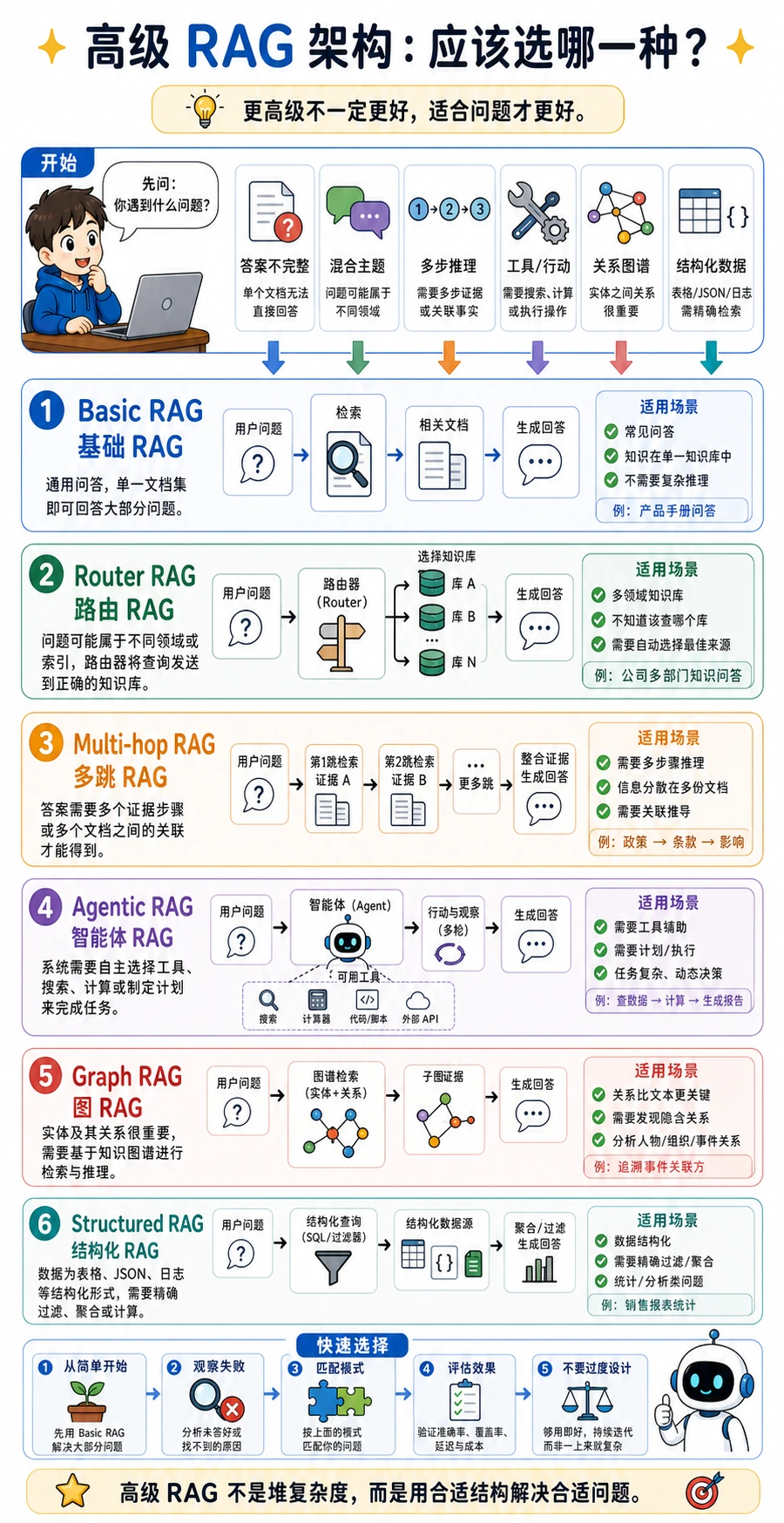
这张图的核心意思很简单:先用最轻的架构解决真正的失败点,而不是一上来就堆最复杂的方案。
二、路由式 RAG:先决定去哪里查
一个知识库不够时,先做路由
很多系统不是只有一个文档库,而是有:
- 政策库
- 产品库
- 技术文档库
- FAQ 库
如果所有查询都进同一个库,噪声会很大。 这时更好的做法是:
先判断问题属于哪个库,再去查。
一个可运行的多库路由示例
policy_docs = [
"退款政策:课程购买后 7 天内可申请退款。",
"证书政策:通过测试后可获得证书。"
]
tech_docs = [
"登录失败时请先检查账号密码和网络连接。",
"API 调用报 401 通常表示鉴权失败。"
]
def route_query(query):
query_lower = query.lower()
if "退款" in query_lower or "证书" in query_lower:
return "policy"
if "登录" in query_lower or "api" in query_lower or "401" in query_lower:
return "tech"
return "default"
def retrieve_simple(query, docs):
query_lower = query.lower()
keywords = []
if "退款" in query_lower:
keywords.extend(["退款", "退款政策"])
if "证书" in query_lower:
keywords.extend(["证书", "证书政策"])
if "登录" in query_lower or "401" in query_lower or "api" in query_lower:
keywords.extend(["登录", "401", "api"])
if not keywords:
keywords = query_lower.split()
return [doc for doc in docs if any(keyword in doc.lower() for keyword in keywords)]
queries = ["怎么退款", "401 报错怎么处理"]
for q in queries:
route = route_query(q)
if route == "policy":
hits = retrieve_simple(q, policy_docs)
elif route == "tech":
hits = retrieve_simple(q, tech_docs)
else:
hits = []
print(q, "-> 路由到", route, "->", hits)
预期输出:
怎么退款 -> 路由到 policy -> ['退款政策:课程购买后 7 天内可申请退款。']
401 报错怎么处理 -> 路由到 tech -> ['API 调用报 401 通常表示鉴权失败。']
这就是最简版的“Router RAG”。 它本身不等于“更聪明的检索”。它的价值是先缩小搜索范围,让 retriever 少和无关材料打架。
三、多跳 RAG:问题要分解成多步
有些问题本来就不是一步能答完
例如:
“这个人完成了哪些条件,还差什么才能拿证?”
这类问题往往需要:
- 查拿证规则
- 查用户完成情况
- 再做对比
多跳 RAG 更像“做题”
不是一次把资料全找出来,而是:
- 先解决第一个子问题
- 再根据中间结果继续查
这会更接近 Agent 的味道。
四、Agentic RAG:让检索不再是固定流水线
它和普通 RAG 的区别是什么?
普通 RAG 更像固定流程:
- 检索
- 拼上下文
- 回答
Agentic RAG 则可能会:
- 判断需不需要检索
- 决定检索几次
- 决定改写查询还是切换数据源
- 再决定是否继续行动
优势与代价
优势:
- 更灵活
- 能处理复杂任务
代价:
- 更难调试
- 更慢
- 成本更高
所以不是所有 RAG 都应该 agent 化。
五、结构化检索:不是所有知识都应该放进纯文本库
当数据本身有结构时
例如:
- 订单表
- 用户状态
- 工单系统
- 成绩表
这类数据很多时候更适合:
- SQL 查询
- API 查询
- 图数据库
而不是先把它们硬转成纯文本再检索。
一个常见的升级思路
真实系统可能会混用:
- 非结构化文档 RAG
- 结构化数据库查询
- 工具调用
这也是“高级 RAG”常常会和 Agent 融在一起的原因。
六、Graph RAG 和知识图谱类思路
它解决什么问题?
当知识点之间存在明显关系时,纯文本切块可能不够。
比如:
- 人物关系
- 公司组织结构
- 产品依赖关系
这时图结构更容易表达“节点之间的连接”。
什么时候值得考虑?
当你的问题经常需要:
- 跨多实体跳转
- 查关系链
- 做结构化推理
可以考虑图式检索思路。
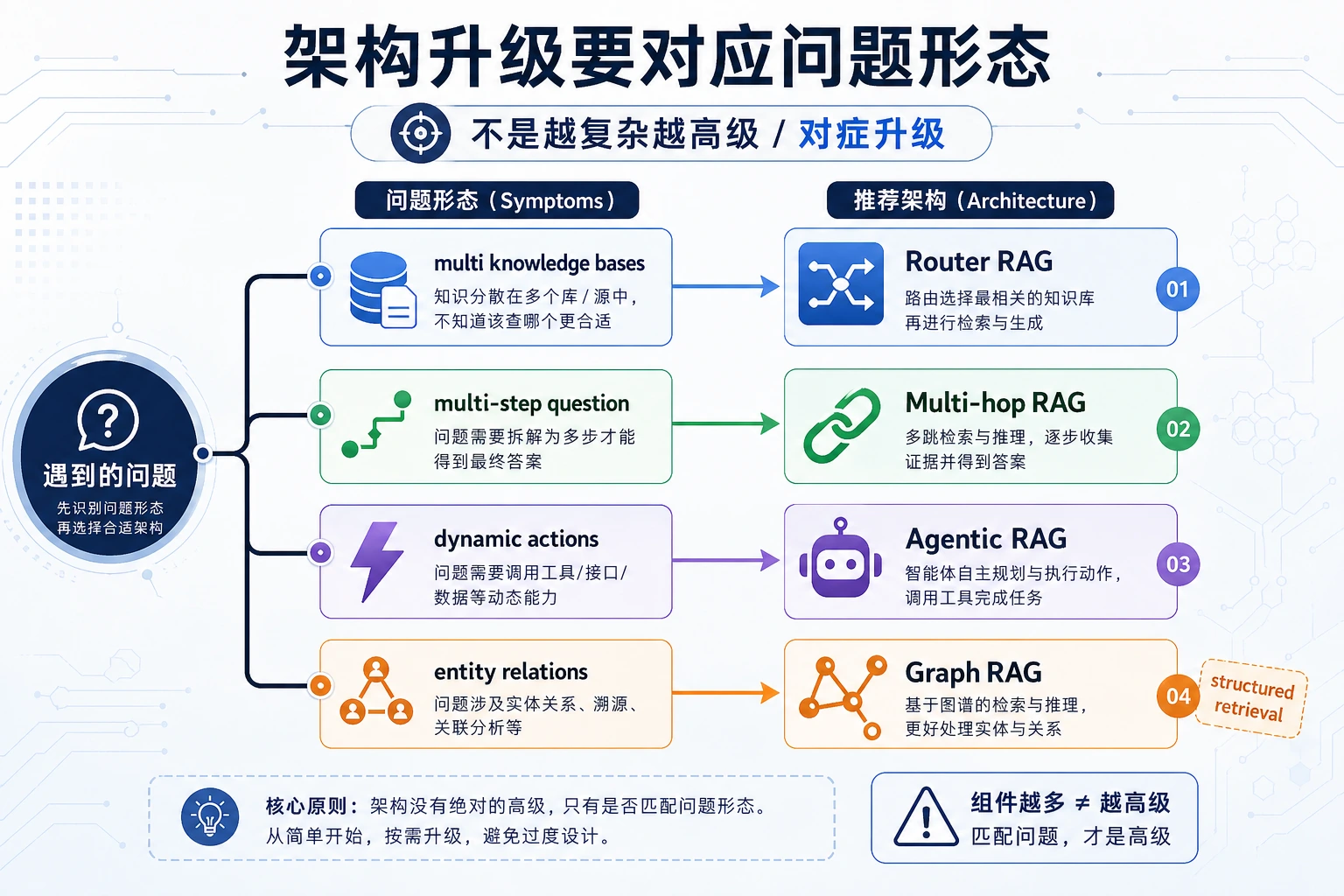
先从问题形态选架构:多知识库干扰先考虑 Router RAG,多步问题考虑 Multi-hop RAG,需要自主决策再考虑 Agentic RAG,关系链明显时再考虑 Graph RAG。
七、什么时候该升级到高级 RAG?
值得升级的信号
如果你已经遇到这些问题:
- 多知识库互相干扰
- 单次检索经常不够
- 需要结构化数据协同
- 问题明显要分步骤才能答
说明可以考虑升级架构。
不值得升级的信号
如果你现在连基础 RAG 都还没打稳:
- chunk 不合理
- 评估集没有
- top-k 都没调过
那先别急着上高级架构。
八、初学者常见误区
一看到复杂任务就想上 Agentic RAG
很多时候,先把路由和检索策略做好,已经能解决大半问题。
把“高级”理解成“组件越多越高级”
组件变多不等于系统更好,可能只是更难维护。
不做评估就盲目升级架构
没有评估,你无法知道升级是真优化还是“看起来更复杂”。
小结
这一节最重要的认识是:
高级 RAG 不是为了炫技,而是在基础 RAG 无法覆盖复杂问题时,给系统增加更聪明的检索组织方式。
先把简单架构打磨稳,再决定要不要升级,通常是更成熟的工程路线。
练习
- 给路由示例再增加一个“课程内容库”,扩展
route_query()规则。 - 想一想:你自己的项目里,有没有哪些数据其实更适合 SQL / API 查询,而不是纯文本检索?
- 试着举一个必须多跳检索才能回答的问题。