3.2.1 NumPy 概要
学習目標
- NumPy とは何か、そして Python エコシステムの中での位置づけを理解する
- ndarray と Python list の違いを理解する
- NumPy をインストールして最初のコードを実行する
- NumPy の性能の強みを直感的に感じる
NumPy とは?
NumPy(Numerical Python)は、Python で科学計算を行うための中核ライブラリです。Python を車にたとえるなら、NumPy はそのエンジンです。データサイエンスや AI に関するほとんどのライブラリは、NumPy の上に成り立っています。
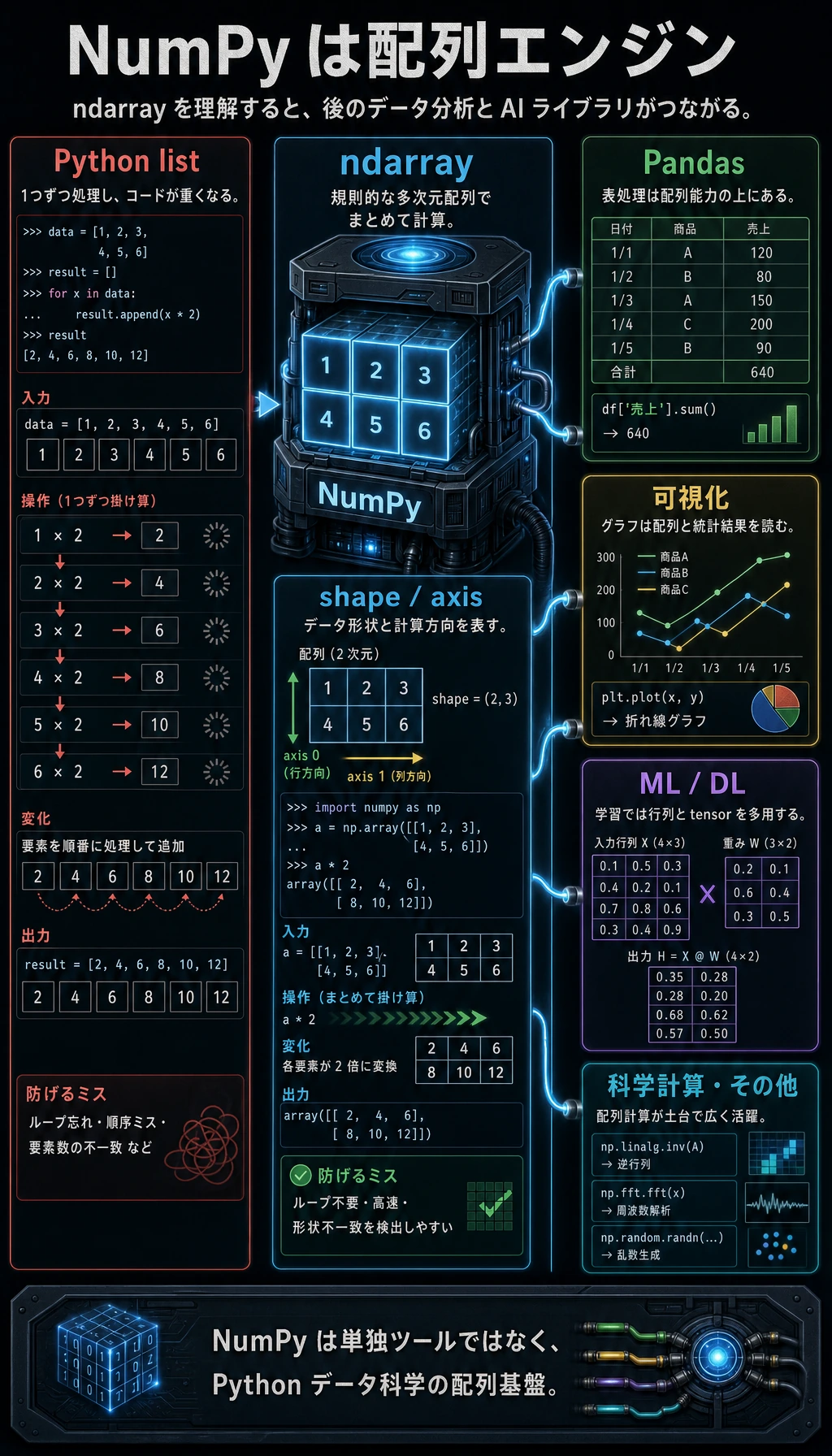
簡単に言うと、データ分析と AI を学ぶなら、NumPy は必ず通る最初の入口です。
なぜ NumPy が必要なの?
第 1 章のウォームアップ練習では、純粋な Python でデータを処理し、たくさんの不便さに出会いました。では NumPy は、何を解決してくれるのでしょうか?
Python list の限界
思い出してみましょう。数字の並びをすべて 2 倍にしたいとき:
# 純粋な Python:ループを書く必要がある
numbers = [1, 2, 3, 4, 5]
result = []
for n in numbers:
result.append(n * 2)
print(result) # [2, 4, 6, 8, 10]
# あるいは list 内包表記を使う
result = [n * 2 for n in numbers]
2 つのデータの対応する位置の和を計算したいとき:
a = [1, 2, 3, 4, 5]
b = [10, 20, 30, 40, 50]
result = [a[i] + b[i] for i in range(len(a))]
print(result) # [11, 22, 33, 44, 55]
こうした操作はよくありますが、毎回ループを書くのは面倒で、しかも遅いです。
NumPy の解決策
import numpy as np
# NumPy:配列全体にそのまま操作できる。ループは不要!
numbers = np.array([1, 2, 3, 4, 5])
result = numbers * 2
print(result) # [ 2 4 6 8 10]
# 2 つのデータを足す
a = np.array([1, 2, 3, 4, 5])
b = np.array([10, 20, 30, 40, 50])
result = a + b
print(result) # [11 22 33 44 55]
ループ不要で 1 行でできる! これが NumPy の中心的な力、ベクトル化演算です。
NumPy のインストール
Miniconda / Anaconda を使っている場合、NumPy はたいてい最初から入っています。もし入っていなければ、次のようにインストールできます。
# pip でインストール
python -m pip install --upgrade numpy
# または conda でインストール
conda install numpy
インストール確認:
import numpy as np
print(np.__version__) # 例: 1.26.4
print("NumPy のインストールに成功しました!")
import numpy as np は慣習的な書き方です。データサイエンスの世界では、ほとんどの人が NumPy を np と短く書きます。これからもこの講座では np を使います。
ndarray vs Python list
NumPy の中心は ndarray(N-dimensional array、N 次元配列)です。Python の list と何が違うのでしょうか?
見た目の比較
import numpy as np
# Python list
py_list = [1, 2, 3, 4, 5]
print(type(py_list)) # <class 'list'>
print(py_list) # [1, 2, 3, 4, 5]
# NumPy ndarray
np_array = np.array([1, 2, 3, 4, 5])
print(type(np_array)) # <class 'numpy.ndarray'>
print(np_array) # [1 2 3 4 5] ← カンマがないことに注意!
主な違い
| 特性 | Python list | NumPy ndarray |
|---|---|---|
| データ型 | 混在可能(整数、文字列、オブジェクトなどを一緒に入れられる) | すべての要素は同じ型である必要がある |
| 計算方法 | ループで 1 つずつ処理する必要がある | ベクトル化演算に対応し、まとめて処理できる |
| メモリ配置 | 要素が分散して保存される | 要素が連続して保存され、よりコンパクト |
| 速度 | 遅い(Python インタプリタが 1 つずつ処理する) | 速い(内部で C 言語により最適化されている) |
| 用途 | 汎用コンテナ | 数値計算向けに設計され、多くの数学関数を備える |
なぜ同じ型が重要なの?
# Python list は混在可能
mixed = [1, "hello", 3.14, True] # ✅ 問題なし
# NumPy 配列は同じ型が必要
arr = np.array([1, 2, 3]) # すべて整数 → int64
arr2 = np.array([1, 2.5, 3]) # 小数を含む → 自動で float64 になる
print(arr.dtype) # int64
print(arr2.dtype) # float64
すべての要素の型が同じだからこそ、NumPy は内部の C コードを使って効率よくまとめて計算できます。Python list のように 1 つずつ型を確認する必要がありません。
性能比較:見てわかる速さ
言葉だけではなく、実際に NumPy がどれくらい速いのか測ってみましょう。
import numpy as np
import time
# 100 万個の数字を準備
size = 1_000_000
py_list = list(range(size))
np_array = np.arange(size)
# Python list:ループで各値を 2 倍にする
start = time.time()
result_py = [x * 2 for x in py_list]
time_py = time.time() - start
print(f"Python list: {time_py:.4f} 秒")
# NumPy:そのままベクトル化演算
start = time.time()
result_np = np_array * 2
time_np = time.time() - start
print(f"NumPy array: {time_np:.4f} 秒")
# 速度比較
print(f"\nNumPy は約 {time_py / time_np:.0f} 倍速いです!")
典型的な出力:
Python list: 0.0580 秒
NumPy array: 0.0008 秒
NumPy は約 72 倍速いです!
NumPy の内部は C 言語で書かれていて、CPU の SIMD 命令(Single Instruction, Multiple Data)も活用しています。これにより、複数のデータを一度に処理できます。一方、Python の for ループは 1 回で 1 要素しか扱えず、そのたびに Python インタプリタの型チェックも通ります。
たとえるなら、Python list は 1 個ずつ手で運ぶ作業、NumPy はショベルカーでまとめて運ぶ作業です。
まずは体験:NumPy で何ができるの?
詳しく学ぶ前に、NumPy のよくある操作を少しだけ体験してみましょう。
配列を作る
import numpy as np
# list から作る
a = np.array([1, 2, 3, 4, 5])
# すべて 0 の配列を作る
zeros = np.zeros(5)
print(zeros) # [0. 0. 0. 0. 0.]
# すべて 1 の配列を作る
ones = np.ones(3)
print(ones) # [1. 1. 1.]
# 等差数列を作る
seq = np.arange(0, 10, 2) # 0 から 10 まで、刻み幅 2
print(seq) # [0 2 4 6 8]
# 均等な数列を作る
lin = np.linspace(0, 1, 5) # 0 から 1 まで、等間隔に 5 点
print(lin) # [0. 0.25 0.5 0.75 1. ]
数学計算
a = np.array([1, 2, 3, 4, 5])
print(a + 10) # [11 12 13 14 15] 各要素に 10 を足す
print(a ** 2) # [ 1 4 9 16 25] 各要素を 2 乗する
print(np.sqrt(a)) # [1. 1.41 1.73 2. 2.24] 各要素の平方根を求める
統計計算
scores = np.array([85, 92, 78, 95, 88, 72, 90, 85])
print(f"平均点: {np.mean(scores):.1f}") # 85.6
print(f"最高点: {np.max(scores)}") # 95
print(f"最低点: {np.min(scores)}") # 72
print(f"標準偏差: {np.std(scores):.1f}") # 7.3
print(f"中央値: {np.median(scores):.1f}") # 86.5
多次元配列
# 3×3 の 2 次元配列(行列)を作る
matrix = np.array([
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
])
print(matrix)
# [[1 2 3]
# [4 5 6]
# [7 8 9]]
print(f"形状: {matrix.shape}") # (3, 3)
print(f"次元数: {matrix.ndim}") # 2
print(f"総要素数: {matrix.size}") # 9
AI における NumPy の活用
「NumPy と AI はどう関係するの?」と思うかもしれません。実はとても深い関係があります。
| AI シーン | NumPy の役割 |
|---|---|
| 画像処理 | 1 枚の画像は 3 次元配列(高さ × 幅 × 色チャネル)として表される |
| データ前処理 | 正規化、標準化、欠損値補完などに NumPy を使う |
| 特徴量計算 | 平均、分散、相関係数などの統計量を計算する |
| ニューラルネットワーク | PyTorch の Tensor と NumPy の ndarray はスムーズに変換できる |
| 単語ベクトル | NLP の埋め込み表現は、NumPy ベクトルの集まりとして扱える |
| 行列演算 | 機械学習の中心は、行列積と勾配計算 |
例として、RGB のカラー画像はコンピュータの中では NumPy 配列です。
import numpy as np
# 4×4 のカラー画像を疑似的に作る(実際の画像は 1920×1080×3 など)
rng = np.random.default_rng(seed=42)
image = rng.integers(0, 256, size=(4, 4, 3), dtype=np.uint8)
print(f"画像の形状: {image.shape}") # (4, 4, 3) → 4 行 × 4 列 × 3 色チャネル(RGB)
print(f"総ピクセル値: {image.size}") # 48 個の数字
まとめ
| 要点 | 説明 |
|---|---|
| NumPy とは | Python 科学計算の中核ライブラリで、ほぼすべての AI/データ関連ライブラリが依存している |
| 中心データ構造 | ndarray(N 次元配列)、すべての要素が同じ型 |
| なぜ速いのか | 内部の C 実装 + 連続メモリ + ベクトル化演算 |
| Python list との違い | 何十倍〜何百倍も速く、計算もずっと便利 |
| インポートの慣習 | import numpy as np |
次の節では、NumPy 配列の作り方と基本属性を詳しく学びます。ここが、この先のすべての操作の土台になります。
手を動かしてみよう
練習 1:インストールと確認
自分の環境に NumPy が入っていることを確認し、バージョン番号を表示してみましょう。
練習 2:性能比較
性能比較コードを実際に動かしてみて、データ量を 500 万、1000 万に変えると速度差がどう変わるか試してみましょう。
練習 3:最初の体験
1 から 100 までの整数をすべて含む NumPy 配列を作り、次のことをしてみましょう。
- すべての数字の合計を求める
- 平均値を求める
- 最大値と最小値を見つける
- すべての数字の 2 乗和を計算する
import numpy as np
arr = np.arange(1, 101) # 1 から 100
total = arr.sum()
average = arr.mean()
max_val = arr.max()
min_val = arr.min()
square_sum = (arr ** 2).sum()
print("total =", total)
print("average =", average)
print("max =", max_val)
print("min =", min_val)
print("square_sum =", square_sum)