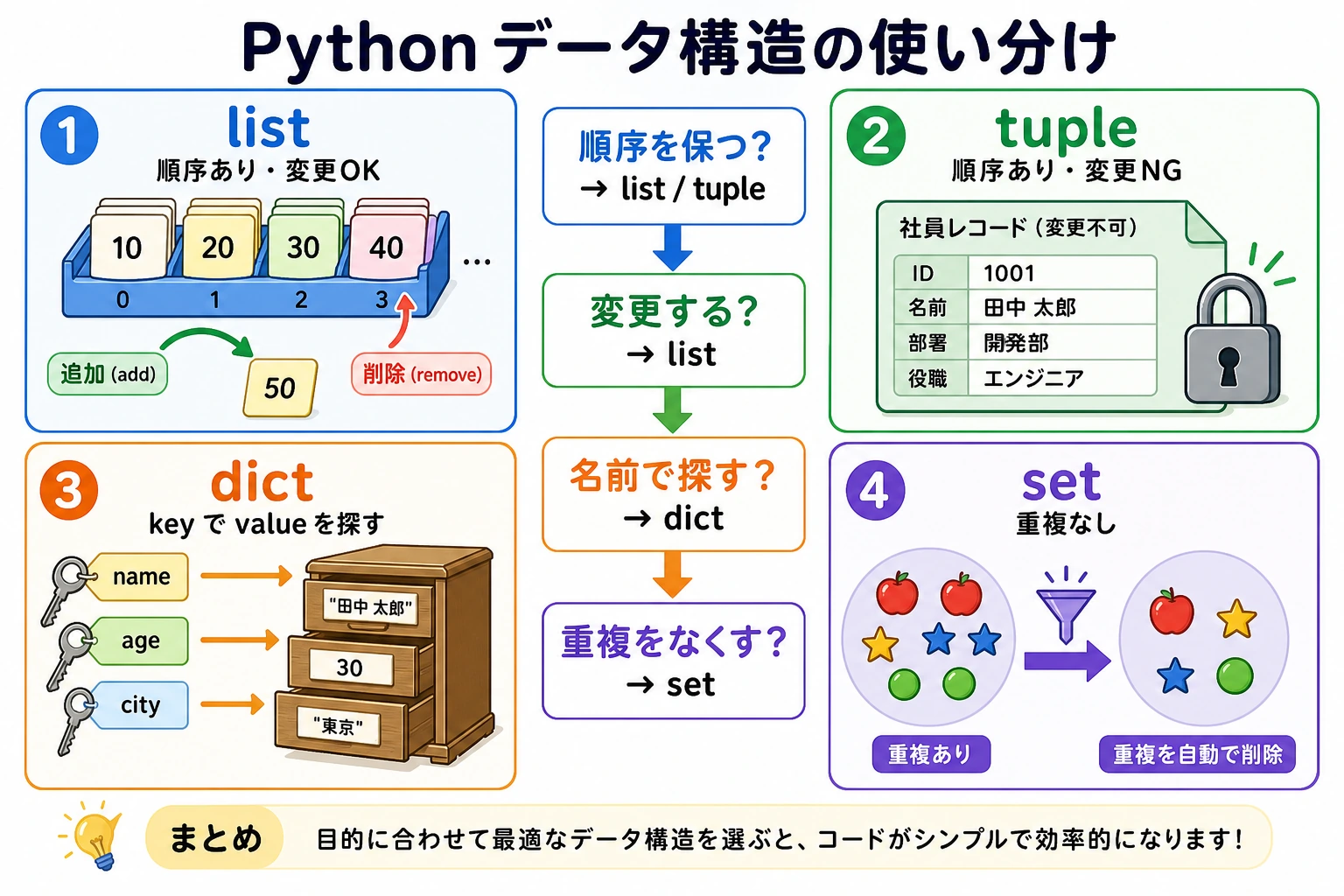
2.1.6 データ構造
この節の位置づけ
この節では、ひとまとまりのデータをどう整理するかを学びます。リスト、タプル、辞書、集合は、この先のクローラー、データ分析、機械学習のサンプル処理、API レスポンスの解析までずっと使います。大事なのは、それぞれの構造が何を入れるのに向いているか、どんなときにどれを使うかを知ることです。
学習目標
- リスト(list)の作成と基本操作を理解する
- タプル(tuple)の特徴と使いどころを理解する
- 辞書(dict)のキー・バリュー操作を身につける
- 集合(set)の重複削除と集合演算を知る
- 場面に応じて適切なデータ構造を選べるようになる
なぜデータ構造が必要なの?
ここまで学んだ変数は、1つの値しか入れられません。でも実際の場面では、ひとまとまりのデータを扱うことがよくあります。
- 100人の学生の成績
- あるモデルのすべてのパラメータ
- ユーザーの個人情報(名前、年齢、メールアドレス……)
データ構造は、複数のデータを整理して保存するための入れ物です。
Python には 4 種類の組み込みデータ構造があります。
| データ構造 | 記号 | 順序あり | 可変 | 重複可 | 典型的な用途 |
|---|---|---|---|---|---|
| リスト list | [] | ✅ | ✅ | ✅ | 順序のあるデータの集合 |
| タプル tuple | () | ✅ | ❌ | ✅ | 変更しないデータ |
| 辞書 dict | {} | ✅ | ✅ | キーは重複不可 | キー・バリューの対応 |
| 集合 set | {} | ❌ | ✅ | ❌ | 重複削除、集合演算 |
リスト(list)—— 最もよく使うデータ構造
リストは、伸び縮みする引き出しのようなものです。中にいろいろなものを入れられて、いつでも追加・削除・変更できます。
リストを作る
# リストを作成
scores = [85, 92, 78, 95, 88]
names = ["山田太郎", "佐藤花子", "鈴木一郎"]
mixed = [1, "hello", 3.14, True] # 型を混ぜることもできる(おすすめはしない)
empty = [] # 空のリスト
print(type(scores)) # <class 'list'>
print(len(scores)) # 5
要素にアクセスする(インデックス)
fruits = ["りんご", "バナナ", "オレンジ", "ぶどう", "スイカ"]
# 0 1 2 3 4
# -5 -4 -3 -2 -1
print(fruits[0]) # りんご(最初)
print(fruits[2]) # オレンジ(3番目)
print(fruits[-1]) # スイカ(最後)
print(fruits[-2]) # ぶどう(後ろから2番目)
スライス
numbers = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(numbers[2:5]) # [2, 3, 4](インデックス 2 から 4)
print(numbers[:3]) # [0, 1, 2](最初の3つ)
print(numbers[7:]) # [7, 8, 9](インデックス 7 から最後まで)
print(numbers[::2]) # [0, 2, 4, 6, 8](1つおきに取り出す)
print(numbers[::-1]) # [9, 8, 7, 6, 5, 4, 3, 2, 1, 0](逆順)
要素を変更する
scores = [85, 92, 78, 95, 88]
# 1つの要素を変更
scores[2] = 80
print(scores) # [85, 92, 80, 95, 88]
# 複数の要素を変更(スライスを使う)
scores[1:3] = [90, 85]
print(scores) # [85, 90, 85, 95, 88]
要素を追加する
fruits = ["りんご", "バナナ"]
# 末尾に追加
fruits.append("オレンジ")
print(fruits) # ['りんご', 'バナナ', 'オレンジ']
# 指定した位置に挿入
fruits.insert(1, "ぶどう")
print(fruits) # ['りんご', 'ぶどう', 'バナナ', 'オレンジ']
# 複数の要素を追加
fruits.extend(["スイカ", "いちご"])
print(fruits) # ['りんご', 'ぶどう', 'バナナ', 'オレンジ', 'スイカ', 'いちご']
要素を削除する
fruits = ["りんご", "バナナ", "オレンジ", "ぶどう", "スイカ"]
# 値で削除(最初に一致したものを削除)
fruits.remove("オレンジ")
print(fruits) # ['りんご', 'バナナ', 'ぶどう', 'スイカ']
# インデックスで削除
deleted = fruits.pop(1) # インデックス 1 の要素を削除して返す
print(deleted) # バナナ
print(fruits) # ['りんご', 'ぶどう', 'スイカ']
# 最後の要素を削除
last = fruits.pop()
print(last) # スイカ
# インデックスで削除(返り値は不要)
del fruits[0]
print(fruits) # ['ぶどう']
リストでよく使う操作
numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5]
# ソート
numbers.sort()
print(numbers) # [1, 1, 2, 3, 4, 5, 5, 6, 9]
# 降順ソート
numbers.sort(reverse=True)
print(numbers) # [9, 6, 5, 5, 4, 3, 2, 1, 1]
# 元のリストを変更しないソート
original = [3, 1, 4, 1, 5]
sorted_list = sorted(original)
print(original) # [3, 1, 4, 1, 5](元のリストは変わらない)
print(sorted_list) # [1, 1, 3, 4, 5]
# 反転
numbers = [1, 2, 3, 4, 5]
numbers.reverse()
print(numbers) # [5, 4, 3, 2, 1]
# 検索
print(numbers.index(3)) # 2(要素 3 のインデックス)
print(numbers.count(5)) # 1(要素 5 の出現回数)
print(3 in numbers) # True
# 集計
scores = [85, 92, 78, 95, 88]
print(len(scores)) # 5
print(sum(scores)) # 438
print(max(scores)) # 95
print(min(scores)) # 78
print(sum(scores) / len(scores)) # 87.6(平均点)
リスト内包表記(とても Python らしい書き方!)
リスト内包表記は、新しいリストを簡潔に作る方法です。
# ふつうの書き方
squares = []
for i in range(1, 6):
squares.append(i ** 2)
print(squares) # [1, 4, 9, 16, 25]
# リスト内包表記(一行で書ける!)
squares = [i ** 2 for i in range(1, 6)]
print(squares) # [1, 4, 9, 16, 25]
# 条件付きのリスト内包表記
even_squares = [i ** 2 for i in range(1, 11) if i % 2 == 0]
print(even_squares) # [4, 16, 36, 64, 100]
# 実践例:データをまとめて処理する
names = [" Alice ", "BOB", " charlie "]
clean_names = [name.strip().lower() for name in names]
print(clean_names) # ['alice', 'bob', 'charlie']
[式 for 変数 in イテラブル if 条件]
日本語にすると、「条件を満たす各要素について式を計算して、新しいリストに入れる」という意味です。
タプル(tuple)—— 変更できないリスト
タプルとリストはほとんど同じですが、違いは1つです。タプルは作成後に変更できません。
タプルを作る
# 丸括弧で作成
point = (3, 4)
colors = ("赤", "緑", "青")
single = (42,) # 要素が1つだけのときは、カンマが必要!
empty = ()
# 実は丸括弧は省略できる
coordinates = 3, 4 # これもタプル
print(type(coordinates)) # <class 'tuple'>
タプルの操作
colors = ("赤", "緑", "青", "黄", "紫")
# アクセス(リストと同じ)
print(colors[0]) # 赤
print(colors[-1]) # 紫
print(colors[1:3]) # ('緑', '青')
# 走査
for color in colors:
print(color)
# 検索
print(len(colors)) # 5
print("赤" in colors) # True
print(colors.count("赤")) # 1
print(colors.index("青")) # 2
# ただし変更はできない!
# colors[0] = "黒" # エラー!TypeError: 'tuple' object does not support item assignment
タプルのアンパック
# タプルの値をそれぞれ別の変数に代入する
point = (10, 20)
x, y = point
print(f"x={x}, y={y}") # x=10, y=20
# 関数が複数の値を返すとき、実際にはタプルが返っている
def get_name_and_age():
return "小明", 25
name, age = get_name_and_age()
print(f"{name}, {age}歳") # 小明, 25歳
# * を使って余った値をまとめる
first, *rest = [1, 2, 3, 4, 5]
print(first) # 1
print(rest) # [2, 3, 4, 5]
いつタプルを使う?
- データを変更されたくないとき(例:座標、RGB の色の値)
- 辞書のキーに使いたいとき(リストは辞書のキーにできないが、タプルはできる)
- 関数で複数の値を返したいとき
辞書(dict)—— キー・バリューで保存する
辞書は、Python のとても重要なデータ構造の1つです。キー(key) で 値(value) を探します。まるで実際の辞書で、単語から意味を引くようなものです。
辞書を作る
# 波括弧で作成
student = {
"name": "小明",
"age": 20,
"city": "北京",
"scores": [85, 92, 78]
}
# 空の辞書
empty = {}
# dict() で作成
config = dict(learning_rate=0.001, epochs=100, batch_size=32)
print(config) # {'learning_rate': 0.001, 'epochs': 100, 'batch_size': 32}
print(type(student)) # <class 'dict'>
値にアクセスする
student = {"name": "小明", "age": 20, "city": "北京"}
# 方法1:[] でアクセス
print(student["name"]) # 小明
# print(student["phone"]) # エラー!KeyError: 'phone'
# 方法2:.get() でアクセス(より安全)
print(student.get("name")) # 小明
print(student.get("phone")) # None(存在しないときは None を返し、エラーにならない)
print(student.get("phone", "未入力")) # 未入力(存在しないときはデフォルト値を返す)
キーがあるか分からないときは、[] よりも .get() のほうが安全です。プログラムが止まるのを防げます。
追加と変更
student = {"name": "小明", "age": 20}
# 新しいキー・バリューを追加
student["city"] = "北京"
student["email"] = "[email protected]"
# 既存の値を変更
student["age"] = 21
print(student)
# {'name': '小明', 'age': 21, 'city': '北京', 'email': '[email protected]'}
# まとめて更新
student.update({"age": 22, "phone": "13800000000"})
print(student)
削除
student = {"name": "小明", "age": 20, "city": "北京"}
# 指定したキーを削除
del student["city"]
print(student) # {'name': '小明', 'age': 20}
# pop:削除して値を返す
age = student.pop("age")
print(age) # 20
print(student) # {'name': '小明'}
辞書を走査する
scores = {"国語": 85, "数学": 92, "英語": 78}
# キーを走査
for subject in scores:
print(subject)
# 値を走査
for score in scores.values():
print(score)
# キー・バリューを走査(最もよく使う)
for subject, score in scores.items():
print(f"{subject}: {score} 点")
# 出力:
# 国語: 85 点
# 数学: 92 点
# 英語: 78 点
辞書内包表記
# 数字から平方への対応表を作る
squares = {x: x**2 for x in range(1, 6)}
print(squares) # {1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
# 辞書を絞り込む
scores = {"張三": 85, "李四": 45, "王五": 92, "趙六": 58}
passed = {name: score for name, score in scores.items() if score >= 60}
print(passed) # {'張三': 85, '王五': 92}
実践例:文字の出現回数を数える
text = "hello world"
char_count = {}
for char in text:
if char in char_count:
char_count[char] += 1
else:
char_count[char] = 1
print(char_count)
# {'h': 1, 'e': 1, 'l': 3, 'o': 2, ' ': 1, 'w': 1, 'r': 1, 'd': 1}
集合(set)—— 重複削除の強い味方
集合は、順序がなく、重複しない要素の集まりです。
集合を作る
# 波括弧で作成
fruits = {"りんご", "バナナ", "オレンジ", "りんご"} # 重複は自動で削除される
print(fruits) # {'バナナ', 'オレンジ', 'りんご'}(順序は変わることがある)
# リストから作成(重複を削除!)
numbers = [1, 2, 2, 3, 3, 3, 4, 4, 4, 4]
unique = set(numbers)
print(unique) # {1, 2, 3, 4}
# 注意:空の集合は set() を使う。{} ではない
empty_set = set() # 空集合
empty_dict = {} # これは空の辞書!
print(type(fruits)) # <class 'set'>
集合の操作
a = {1, 2, 3, 4, 5}
b = {4, 5, 6, 7, 8}
# 積集合(両方にあるもの)
print(a & b) # {4, 5}
print(a.intersection(b))
# 和集合(まとめて、重複なし)
print(a | b) # {1, 2, 3, 4, 5, 6, 7, 8}
print(a.union(b))
# 差集合(a にはあるが b にはないもの)
print(a - b) # {1, 2, 3}
print(a.difference(b))
# 対称差集合(それぞれにしかないもの)
print(a ^ b) # {1, 2, 3, 6, 7, 8}
実践での使い方
# 例:2つの授業の両方を受けている学生を探す
math_students = {"張三", "李四", "王五", "趙六"}
english_students = {"李四", "王五", "銭七", "孫八"}
both = math_students & english_students
print(f"両方の授業を受けている: {both}") # {'李四', '王五'}
only_math = math_students - english_students
print(f"数学だけ受講: {only_math}") # {'張三', '趙六'}
all_students = math_students | english_students
print(f"すべての受講者: {all_students}")
データ構造の選び方ガイド
| 目的 | おすすめ | 理由 |
|---|---|---|
| 順序のある集合で、追加・削除・変更をしたい | リスト | いちばん汎用的な入れ物 |
| データを変更したくない | タプル | 変更不可で安全 |
| キーで値を探したい | 辞書 | O(1) で高速に検索できる |
| 重複を取り除きたい | 集合 | 自動で重複を削除する |
| 出現回数を数えたい | 辞書 | キーを要素、値をカウントにできる |
| 要素が存在するか調べたい | 集合/辞書 | リストよりずっと速い |
実践練習
練習 1:成績集計
scores = [85, 92, 78, 95, 88, 76, 90, 82, 97, 73]
# 1. 最高点、最低点、平均点を計算する
# 2. 90点以上の成績をすべて取り出す(リスト内包表記を使う)
# 3. 成績を高い順に並べる
練習 2:連絡先帳
辞書を使って、簡単な連絡先帳を作ってみましょう。
contacts = {}
# 1. 3人分の連絡先を追加する(名前 → 電話番号)
# 2. ある人の電話番号を調べる
# 3. ある人の電話番号を変更する
# 4. 1人分の連絡先を削除する
# 5. すべての連絡先を表示する
練習 3:単語の出現回数を数える
text = "the quick brown fox jumps over the lazy dog the fox"
# それぞれの単語が何回出てくるかを数える
# ヒント:まず split() でリストに分けてから、辞書で数える
練習 4:リストの重複削除(順序を保つ)
numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# 重複を取り除くが、元の順序は保つ
# 期待する出力: [3, 1, 4, 5, 9, 2, 6]
# ヒント:すでに出てきた要素を集合で記録する
まとめ
| データ構造 | 作り方 | 特徴 | よくある場面 |
|---|---|---|---|
| リスト | [1, 2, 3] | 順序あり、可変、重複可 | ひとまとまりの同種データを保存する |
| タプル | (1, 2, 3) | 順序あり、変更不可 | 座標、複数の戻り値 |
| 辞書 | {"a": 1} | キー・バリュー、キー重複不可 | 設定、対応関係 |
| 集合 | {1, 2, 3} | 順序なし、重複なし | 重複削除、集合演算 |
データ構造を選ぶのは、収納道具を選ぶのと似ています。リストは引き出し(順番に並べる)、辞書はラベル付きの棚(ラベルで探す)、集合はふるい(自動で重複を取る)、タプルは密封袋(入れたあとに変更しない)です。道具を正しく選べば、作業はぐっと楽になります。