HMM、CRF 与序列标注历史主线
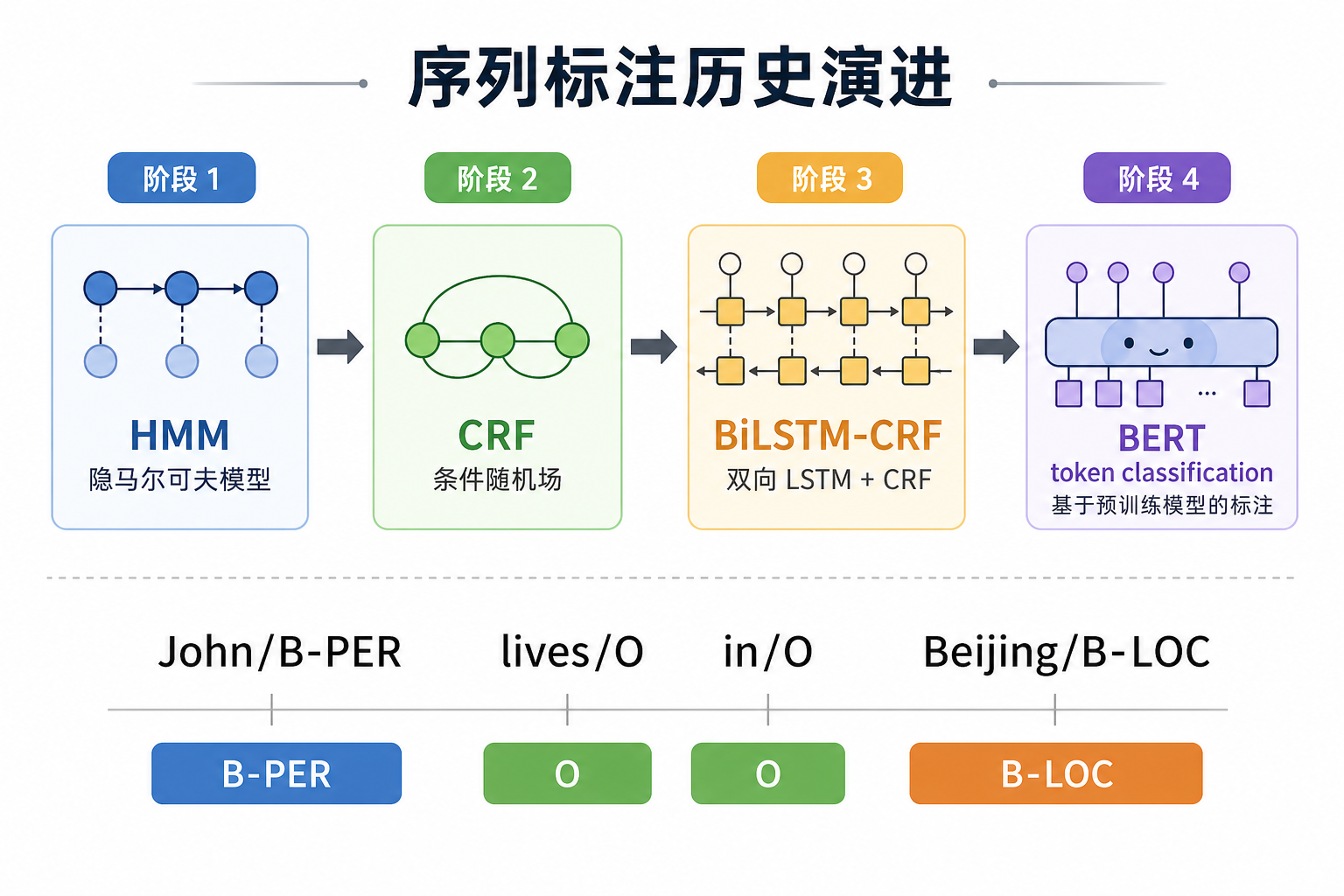
如果你只看现代 BERT token classification,很容易觉得序列标注就是“给每个 token 分类”。
但 NLP 历史上,这条线很早就开始了:
HMM 先把词性标注做成统计序列问题,CRF 强化了标签之间的约束,BiLSTM-CRF 加入上下文表示,BERT 又把上下文表示做得更强。
一、序列标注到底难在哪里?
序列标注不是给整句话一个标签,而是给每个位置一个标签。
例如命名实体识别:
乔布斯 创立 苹果
B-PER O B-ORG
难点在于:每个位置的标签不是完全独立的。
比如:
I-PER通常不能凭空出现在句首B-ORG后面可能接I-ORG- 中文分词、词性标注、NER 都依赖上下文
所以这条历史线一直在解决同一个问题:
怎样既看当前 token,又看前后文,还让整串标签合理?
二、HMM:早期统计序列建模的经典起点
HMM 可以理解成一个“隐藏状态生成观测词”的模型。
在词性标注里:
- 隐藏状态:词性标签,例如名词、动词、形容词
- 观测结果:真实出现的词
它会问两个问题:
| 问题 | HMM 里的名字 |
|---|---|
| 某个词性后面接哪个词性更可能? | 转移概率 |
| 某个词性生成某个词更可能吗? | 发射概率 |
最经典的解码方式是 Viterbi:
不是每个位置单独选最大概率,而是找整句话最可能的标签路径。
三、CRF:更直接地为“整条标签路径”打分
HMM 很经典,但它有比较强的生成式假设。
CRF 更像是直接回答:
给定这句话,哪一整串标签最合理?
这对 NER 很重要,因为标签之间有约束。
比如:
B-PER -> I-PER 合理
O -> I-PER 通常不合理
CRF 的价值就在于:
它不只是看“这个 token 像不像实体”,还会看“整条标签链是否合法、是否顺滑”。
四、BiLSTM-CRF:上下文表示 + 标签约束
后来深度学习进入 NLP 后,BiLSTM 负责读上下文,CRF 负责选择整体标签路径。
可以把它理解成分工:
| 模块 | 负责什么 |
|---|---|
| Embedding | 把词变成向量 |
| BiLSTM | 同时看左边和右边上下文 |
| CRF | 选择最合理的标签序列 |
这就是为什么很多早期 NER 系统会使用 BiLSTM-CRF。
五、BERT 之后,HMM/CRF 还值得学吗?
值得。原因不是你一定要在项目里手写 HMM,而是:
- HMM 帮你理解“序列状态”和“路径解码”
- CRF 帮你理解“标签之间有约束”
- BiLSTM-CRF 帮你理解“上下文表示 + 结构化输出”
- BERT token classification 帮你理解“更强表示可以替换一部分特征工程”
现代项目里,BERT 往往能直接做出很强的 token 表示。
但当数据少、标签规则严格、边界容易错时,CRF 思想仍然有价值。
六、把历史节点分配到课程章节
| 历史节点 | 解决的问题 | 对应课程章节 |
|---|---|---|
| HMM 词性标注 | 用隐藏状态和转移概率建模标签序列 | 4.5 本节、4.2 序列标注任务 |
| Viterbi 解码 | 找整句最可能标签路径 | 4.5 本节、4.3 BiLSTM + CRF |
| CRF | 给定输入后直接建模整条标签路径 | 4.3 BiLSTM + CRF |
| BiLSTM-CRF | 上下文表示与标签约束结合 | 4.3 BiLSTM + CRF、4.4 NER 实战 |
| BERT token classification | 用预训练上下文表示做 token 级任务 | 6.3 BERT、7 大模型基础 |
七、一个最小直觉示例
下面不是完整 HMM,只是帮你看懂“转移约束”的感觉:
labels = ["B-PER", "I-PER", "O"]
allowed = {
"B-PER": ["I-PER", "O"],
"I-PER": ["I-PER", "O"],
"O": ["B-PER", "O"],
}
path = ["O", "I-PER"]
if path[1] not in allowed[path[0]]:
print("这条标签路径不合理")
else:
print("这条标签路径可以接受")
这段代码想表达的是:
序列标注不是每个 token 各判各的,标签之间也有“语法”。
八、学完这一节应该形成的直觉
序列标注历史不是从 BERT 开始的。
它大致经历了:
HMM / Viterbi -> CRF -> BiLSTM-CRF -> BERT token classification
每一代都在回答同一个问题:
怎样让每个位置的标签既符合上下文,又让整条标签序列合理?