项目二:客户流失预测(分类问题)
项目定位
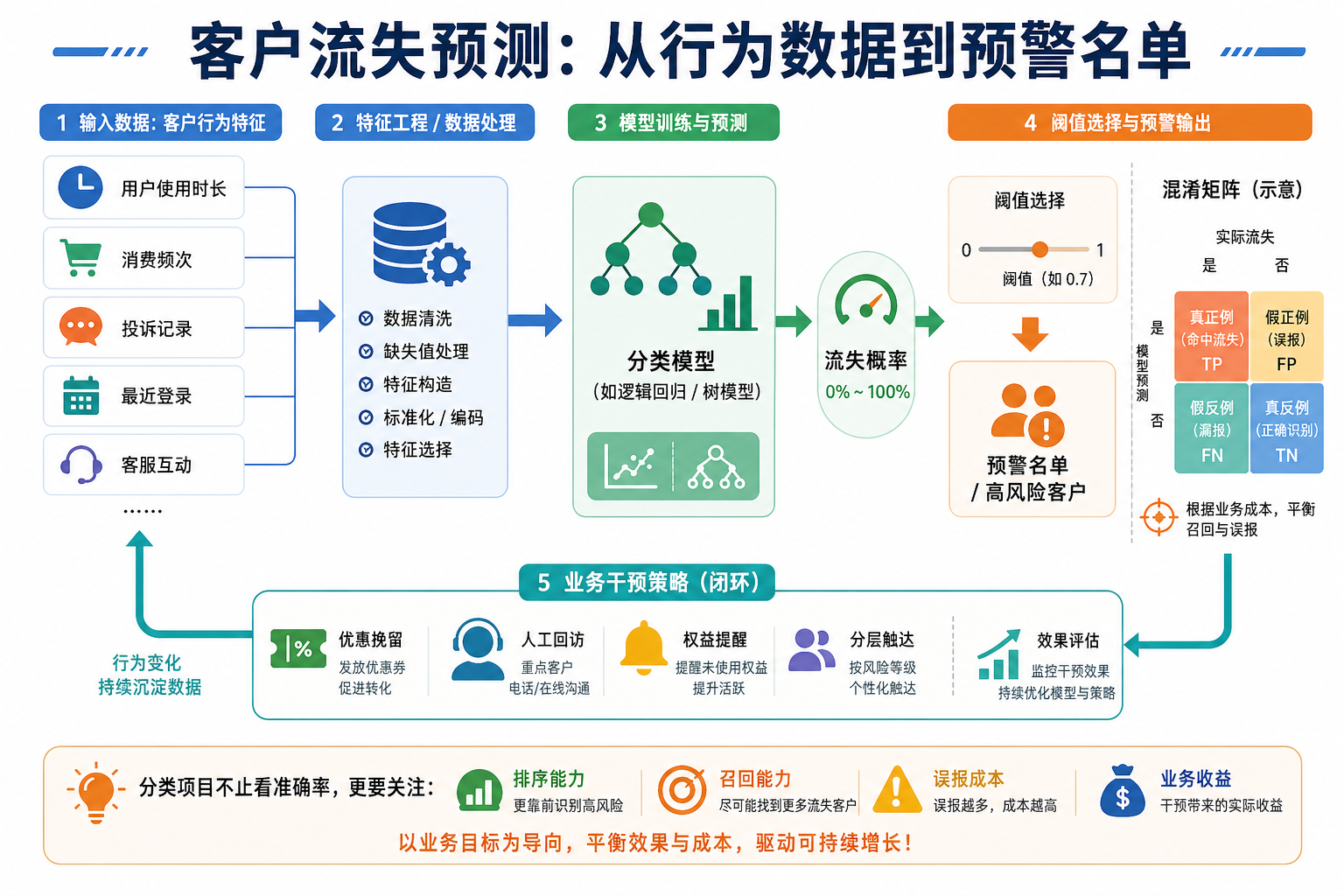
客户流失预测是最经典的商业 ML 应用之一。本项目重点练习:不平衡数据处理、业务指标理解、从模型结果中提取业务洞�察。
项目概览
| 信息 | 说明 |
|---|---|
| 任务类型 | 二分类(流失/留存) |
| 核心挑战 | 数据不平衡(流失客户远少于留存) |
| 评估指标 | F1、AUC、召回率 |
| 涉及技能 | 不平衡处理、Pipeline、业务分析 |
先说一个很重要的学习预期
这题很容易让新人一上来就掉进“模型比较”里:
- 逻辑回归
- 随机森林
- SMOTE
- AUC
但更适合第一遍先练会的,其实不是谁分数更高,而是:
面对不平衡分类问题时,怎样把业务代价、指标选择、阈值决策和模型结果真正串起来。
只要这条线先立住,这题才会像真实项目,而不是“再做一道分类题”。
先建立一张地图
这题最有价值的地方,不是“做一个二分类器”,而是第一次真正面对:
- 数据不平衡
- 阈值选择
- 业务代价不同
所以这题真正��练的是“怎么做分类决策”,不是单纯“怎么跑分类模型”。
这题你真正要练什么
这个项目的核心不是“把分类器跑起来”,而是练习:
- 不平衡数据时为什么不能只看准确率
- 怎样在召回率、精确率和业务代价之间取舍
- 怎样把模型结果翻译成业务洞察
这题第一版最该先讲清什么
第一次做这题时,最该先说明的不是模型名字,而是:
- 流失客户占比多少
- 为什么不能只看准确率
- 如果业务更怕漏掉将流失客户,应该偏向哪个指标
把这三件事说清楚,后面所有模型和阈值选择才有意义。
一个更适合新人的类比
你可以先把这题想成:
- 在客户真的离开之前,尽早拉一张“高风险名单”
这张名单的价值不在于:
- 每个人都判断得绝对完美
而在于:
- 你能不能在可接受的误报成本下,尽量少漏掉真正会流失��的人
这就是为什么这题从一开始就不能只盯着准确率。
推荐推进顺序
- 先做一个不处理不平衡的 baseline
- 再做类别权重
- 再尝试 SMOTE 等方法
- 最后再比较 ROC、AUC、F1 和业务解释
这样你才知道“提升”到底来自哪里。
第一次做这题时,最稳的默认顺序
如果你第一次做客户流失预测,建议按这个顺序:
- 先把业务目标说清楚
- 先看类别分布
- 先做原始 baseline
- 再做
class_weight - 最后再试 SMOTE
- 再决定阈值应该往召回率还是精确率偏
这样你会更清楚每一步提升到底来自:
- 模型
- 采样
- 还是阈值策略
Step 1:模拟数据
import pandas as pd
import numpy as np
from sklearn.datasets import make_classification
# 生成不平衡的客户数据
X, y = make_classification(
n_samples=5000, n_features=15, n_informative=8,
n_redundant=3, weights=[0.85, 0.15], # 85% 留存, 15% 流失
random_state=42
)
feature_names = ['月消费', '通话时长', '流量使用', '客服通话次数', '合同时长',
'账单争议', '套餐等级', '家庭成员数', '在网时长', '上月投诉',
'流量超限次数', '国际漫游', '增值服务数', '账户余额', '设备更换']
df = pd.DataFrame(X, columns=feature_names)
df['流失'] = y
print(f"数据形状: {df.shape}")
print(f"流失比例: {df['流失'].mean():.1%}")
print(f"流失客户: {df['流失'].sum()}, 留存客户: {(1-df['流失']).sum():.0f}")
Step 2:不平衡数据处理
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, roc_auc_score
import matplotlib.pyplot as plt
X = df.drop('流失', axis=1)
y = df['流失']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# 方法1: 类别权重
rf_weighted = RandomForestClassifier(n_estimators=100, class_weight='balanced', random_state=42)
rf_weighted.fit(X_train, y_train)
y_pred = rf_weighted.predict(X_test)
print("带类别权重的随机森林:")
print(classification_report(y_test, y_pred, target_names=['留存', '流失']))
print(f"AUC: {roc_auc_score(y_test, rf_weighted.predict_proba(X_test)[:,1]):.4f}")
Step 2.1 为什么不要一开始就上 SMOTE
更稳的顺序通常是:
- 先做原始 baseline
- 再试
class_weight - 最后再试
SMOTE
因为这样你才能分清:
- 提升是来自模型本身
- 还是来自采样策略
- 还是来自阈值调整
SMOTE 过采样
# pip install imbalanced-learn
try:
from imblearn.over_sampling import SMOTE
from imblearn.pipeline import Pipeline as ImbPipeline
smote_pipe = ImbPipeline([
('smote', SMOTE(random_state=42)),
('classifier', RandomForestClassifier(n_estimators=100, random_state=42)),
])
smote_pipe.fit(X_train, y_train)
y_pred_smote = smote_pipe.predict(X_test)
print("\nSMOTE + 随机森林:")
print(classification_report(y_test, y_pred_smote, target_names=['留存', '流失']))
except ImportError:
print("请安装 imbalanced-learn: pip install imbalanced-learn")
Step 3:特征重要性与业务洞察
# 特征重要性
importance = rf_weighted.feature_importances_
sorted_idx = np.argsort(importance)
plt.figure(figsize=(8, 8))
plt.barh(range(len(sorted_idx)), importance[sorted_idx], color='coral')
plt.yticks(range(len(sorted_idx)), np.array(feature_names)[sorted_idx])
plt.xlabel('特征重要性')
plt.title('客户流失预测——特征重要性')
plt.grid(axis='x', alpha=0.3)
plt.tight_layout()
plt.show()
# 业务建议
print("\n业务洞察:")
top3 = np.array(feature_names)[np.argsort(importance)[-3:]]
for i, feat in enumerate(reversed(top3), 1):
print(f" {i}. {feat} 对流失预测最重要")
Step 4:ROC 对比
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, roc_auc_score
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
models = {
'逻辑回归': make_pipeline(StandardScaler(), LogisticRegression(class_weight='balanced', max_iter=1000)),
'随机森林': RandomForestClassifier(n_estimators=100, class_weight='balanced', random_state=42),
}
plt.figure(figsize=(8, 6))
for name, model in models.items():
model.fit(X_train, y_train)
proba = model.predict_proba(X_test)[:, 1]
fpr, tpr, _ = roc_curve(y_test, proba)
auc = roc_auc_score(y_test, proba)
plt.plot(fpr, tpr, linewidth=2, label=f'{name} (AUC={auc:.4f})')
plt.plot([0, 1], [0, 1], 'k--', alpha=0.5)
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.title('客户流失预测 ROC 对比')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
Step 4.1 这一步最值得再补什么
如果想把这题做得更像真实业务项目,最值得补的是:
- 一张混淆矩阵
- 一张阈值 vs Precision / Recall / F1 曲线
- 一段“如果召回率优先,我会把阈值调到哪里”的解释
因为很多真实留存项目,重点不是默认阈值 0.5 下谁分数高,而是:
- 在可接受的误报成本内,尽量多抓高风险客户
项目交付时最好补上的内容
- 一张类别分布图
- 一张混淆矩阵
- 一张 ROC 曲线
- 一段“如果目标是尽量召回流失客户,我会怎么调阈值”的说明
一个更像真实项目的复盘顺序
你可以用下面这个顺序来写项目复盘:
- 数据分布和业务目标
- baseline 模型结果
- 不平衡处理后的变化
- 指标权衡和阈值调整
- 特征重要性和业务建议
- 下一步如果上线,应该怎么监控
如果继续把这个项目往上��做,最值得补什么
更值得优先补的通常是:
- 阈值调优页
- 误判客户案例分析
- 不同业务目标下的指标切换说明
这样项目会从“一个分类任务”变成“一个更像真实业务决策系统”的作品。
做成作品集时,最值得展示什么
- 类别分布和任务目标
- baseline 与改进版的对比
- ROC 或 PR 曲线
- 一张阈值解释图
- 一段可执行的客户运营建议
项目检查清单
- 分析数据不平衡程度
- 尝试至少 2 种不平衡处理方法(类别权重、SMOTE)
- 用 F1 和 AUC 评估(不只看准确率)
- 分析特征重要性,给出业务建议
- ROC 曲线多模型对比
版本路线建议
| 版本 | 目标 | 交付重点 |
|---|---|---|
| 基础版 | 跑通最小闭环 | 能输入、能处理、能输出,并保留一组示例 |
| 标准版 | 形成可展示项目 | 增加配置、日志、错误处理、README 和截图 |
| 挑战版 | 接近作品集质量 | 增加评估、对比实验、失败样本分析和下一步路线 |
建议先完成基础版,不要一开始就追求大而全。每提升一个版本,都要把“新增了什么能力、怎么验证、还有什么问题”写进 README。