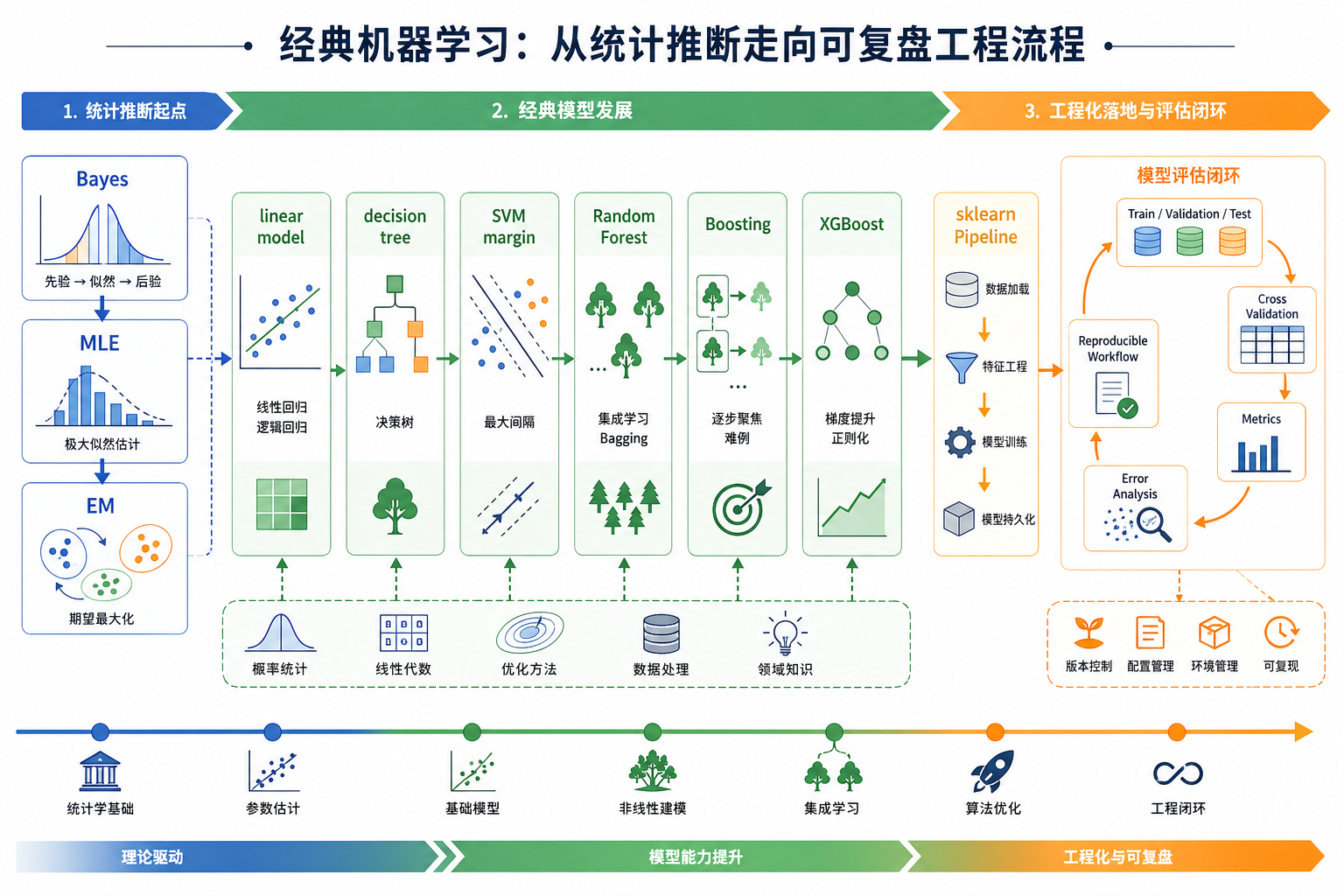
机器学习历史突破主线
这一节不是让你背年份,而是帮你看懂:
- 每一次机器学习突破之前,�大家卡在哪里
- 新方法到底解决了什么问题
- 它应该放到本章哪个位置学习
- 做项目时,这个历史节点会变成什么工程能力
一、先用一句话抓住机器学习历史主线
机器学习的历史可以先理解成一条从“人工写规则”走向“用数据学习规律”的路线。
早期 AI 很依赖人工规则。人类专家把知识写成 if-else 或符号规则,系统按规则推理。这个思路在规则清楚的场景里有用,但一旦任务变复杂,规则就会爆炸。比如判断一封邮件是不是垃圾邮件,你很难把所有规则提前写完。
机器学习的关键转向是:不要直接手写规则,而是准备数据、定义目标、选择模型,让模型自己从案例里学规律。第 5 章要训练的不是“背算法名”,而是这套建模思维:
| 历史变化 | 对应本章能力 |
|---|---|
| 从规则到数据 | 知道什么时候该用机器学习 |
| 从单次拟合到评估 | 学会 train/test、指标和泛化 |
| 从单模型到模型族 | 能比较 baseline、树模型、集成方法 |
| 从手写流程到工程化 | 用 sklearn、Pipeline 和报告复盘项目 |
二、突破一:贝叶斯、最大似然和 EM 让“不确定性”可以被建模
在很多真实问题里,数据不是绝对确定的。用户会犹豫,传感器会有噪声,样本会缺失,标签也可能不完美。
这时机器学习需要回答一个问题:
在信息不完整、带噪声的情况下,怎样做出最合理的判断?
贝叶斯法则提供了“看到新证据后更新判断”的方式。最大似然估计让我们可以根据观测数据反推最可能的参数。EM 算法则处理更麻烦的情况:数据里有隐藏变量或缺失信息时,先估计隐藏部分,再更新参数,反复迭代。
对新人来说,可以这样类比:
| 方法 | 生活类比 | 本章连接 |
|---|---|---|
| Bayes | 侦探看到新证据后更新嫌疑人概率 | 概率直觉、朴素贝叶斯选修 |
| MLE | 根据过去销量反推最可能的需求规律 | 损失函数、参数估计 |
| EM | 拼一张缺了几块的拼图,先猜缺块,再修正整体 | 聚类、隐变量模型背景 |
这一组方法不一定都在第 5 章主线里深入推导,但它们解释了机器学习为什么离不开概率、损失和参数估计。
建议对应学习:
| 对应位置 | 你要带走什么 |
|---|---|
| 第 4 章概率统计 | 概率不是考试题,而是表达不确定性的语言 |
| 本章 1.5 数学如何真正流到机器学习 | 参数、损失和优化如何接到训练循环 |
| 选修模块经典 ML | 朴素贝叶斯、LDA 等传统方法如何使用概率思想 |
三、突破二:线性模型把“预测”变成可训练的 baseline
线性回归和逻辑回归看起来简单,但它们在机器学习里非常重要,因为它们让新人第一次看到完整的训练结构:
- 输入特征
- 计算预测
- 衡量误差
- 调整参数
- 用测试集评估
线性回归解决连续值预测,逻辑回归解决分类概率。它们不是“过时算法”,而是很多复杂模型的骨架。神经网络也可以理解成很多线性变换加非线性激活堆起来。
建议对应学习:
| 对应位置 | 历史突破带来的学习重点 |
|---|---|
| 2.2 线性回归 | 第一次看懂“模型、损失、参数更新” |
| 2.3 逻辑回归 | 从连续预测走向分类概率和决策边界 |
| 第 6 章神经网络 | 理解神经元为什么像“可训练的线性模型 + 激活函数” |
四、突破三:决策树让机器学习结果变得更像人能读懂的规则
线性模型很稳,但它经常不够直观,也不擅长表达复杂的非线性规则。决策树的突破在于:
把学习到的规律组织成一串可解释的判断。
你可以把决策树想成“20 个问题”游戏。模型每次选择一个特征做分裂,让节点里的样本越来越纯。CART 等方法把分类树和回归树系统化,让树模型成为机器学习里最容易解释的一类模型。
但单棵树也有明显问题:太容易长得很深,把训练集噪声也记住。这就自然引出随机森林和 Boosting。
建议对应学习:
| 对应位置 | 历史突破带来的学习重点 |
|---|---|
| 2.4 决策树 | 规则分裂、纯度、剪枝和可解释性 |
| 4.3 偏差方差 | 为什么树太深会过拟合 |
| 5.5 Pipeline | 如何把树模型放进完整建模流程 |
五、突破四:SVM 把“分界线要稳”这件事讲得很清楚
SVM 的核心故事很适合新人理解分类边界。
如果两条线都能把样本分开,哪条更好?SVM 的答案是:
选离两类样本都尽量远的那条边界。
这就是最大间隔思想。它让模型不要贴着训练样本做危险切分,而是尽量留出安全距离。核方法又进一步让 SVM 可以处理非线性边界。
SVM 在今天不一定是每个项目的首选,但它在历史上非常重要,因为它把“泛化边界”和“稳定分类”讲得很漂亮。
建议对应学习:
| 对应位置 | 历史突破带来的学习重点 |
|---|---|
| 选修模块:SVM | 最大间隔、支持向量、核方法 |
| 本章模型评估 | 训练分数高不一定代表边界稳 |
| 本章特征工程 | SVM 对特征缩放很敏感 |
六、突破五:随机森林和 Boosting 把弱模型组合成强模型
单棵树容易过拟合,但树有一个巨大优点:它能处理非线性和特征交互。于是机器学习进入了一个很重要的阶段:
不再迷信单个模型,而是组合多个模型。
随机森林用 Bagging 思想让多棵树并行训练,再投票或平均,降低单棵树不稳定的问题。Boosting 则按顺序训练模型,每一步关注前面做错的样本,逐步纠错。
这条路线非常影响工业机器学习,尤其是表格数据任务。XGBoost、LightGBM、CatBoost 等工具让 Boosting 在真实项目和比赛里成为强 baseline。
建议对应学习:
| 对应位置 | 历史突破带来的学习重点 |
|---|---|
| 2.5 集成学习 | Bagging 和 Boosting 的差异 |
| 4.1 指标选择 | 强模型也必须放到正确指标下比较 |
| 6.4 Kaggle 入门 | 为什么表格数据项目常从 XGBoost 类模型开始 |
七、突破六:sklearn 把经典机器学习变成统一工程流程
算法突破很重要,但工程化同样重要。scikit-learn 的价值不只是提供很多模型,而是把经典机器学习统一成一套非常稳定的接口:
model.fit(X_train, y_train)
pred = model.predict(X_test)
score = metric(y_test, pred)
这让新人可以先学统一流程,再逐步理解不同模型的差异。它也让项目更容易复现、比较和组织。
建议对应学习:
| 对应位置 | 历史突破带来的学习重点 |
|---|---|
| 1.4 Scikit-learn 框架入门 | fit / predict / score 的统一心智 |
| 5.5 Pipeline | 防止数据泄漏和流程散乱 |
| 6 阶段项目 | 把训练、评估、报告形成可复现项目 |
八、把历史突破分配到第 5 章学习路径
你可以按下面这张表回到具体章节学习:
| 历史突破 | 解决的问题 | 本课程对应章节 |
|---|---|---|
| Bayes / MLE / EM | 不确定性、参数估计、隐变量 | 第 4 章概率统计、本章 1.5、选修经典 ML |
| 线性回归 | 连续值预测的最小可训练模型 | 2.2 线性回归 |
| 逻辑回归 | 分类概率和线性决策边界 | 2.3 逻辑回归 |
| CART / 决策树 | 可解释规则和非线性分裂 | 2.4 决策树 |
| SVM | 最大间隔和稳定分类边界 | 选修模块经典 ML |
| Random Forest | 多棵树投票降低方差 | 2.5 集成学习 |
| AdaBoost / GBDT / XGBoost | 串行纠错提升表格 baseline | 2.5 集成学习、6.4 Kaggle |
| sklearn / Pipeline | 把算法组织成可复现工程流程 | 1.4 sklearn、5.5 Pipeline |
九、学完这一节应该形成的直觉
机器学习历史不是“老算法列表”,而是一串问题被逐步解决的过程:
| 老问题 | 新突破 | 你现在要练的能力 |
|---|---|---|
| 人写规则写不完 | 从数据学习规律 | 定义任务和准备数据 |
| 单次分数不可信 | train/test 与交叉验证 | 判断模型是否泛化 |
| 单模型不稳定 | 集成学习 | 比较 baseline 和强模型 |
| 流程容易混乱 | sklearn / Pipeline | 做可复现建模项目 |
学完这一节后,再去看线性回归、决策树、集成学习和评估,你会更容易明白:这些技术不是突然出现的名词,而是在解决机器学习历史上反复出现的真实问题。