7.0 学习检查表:大模型原理、Prompt 与微调
这页当成可打印检查表使用。需要完整讲解时,回到 第 7 章入口页。
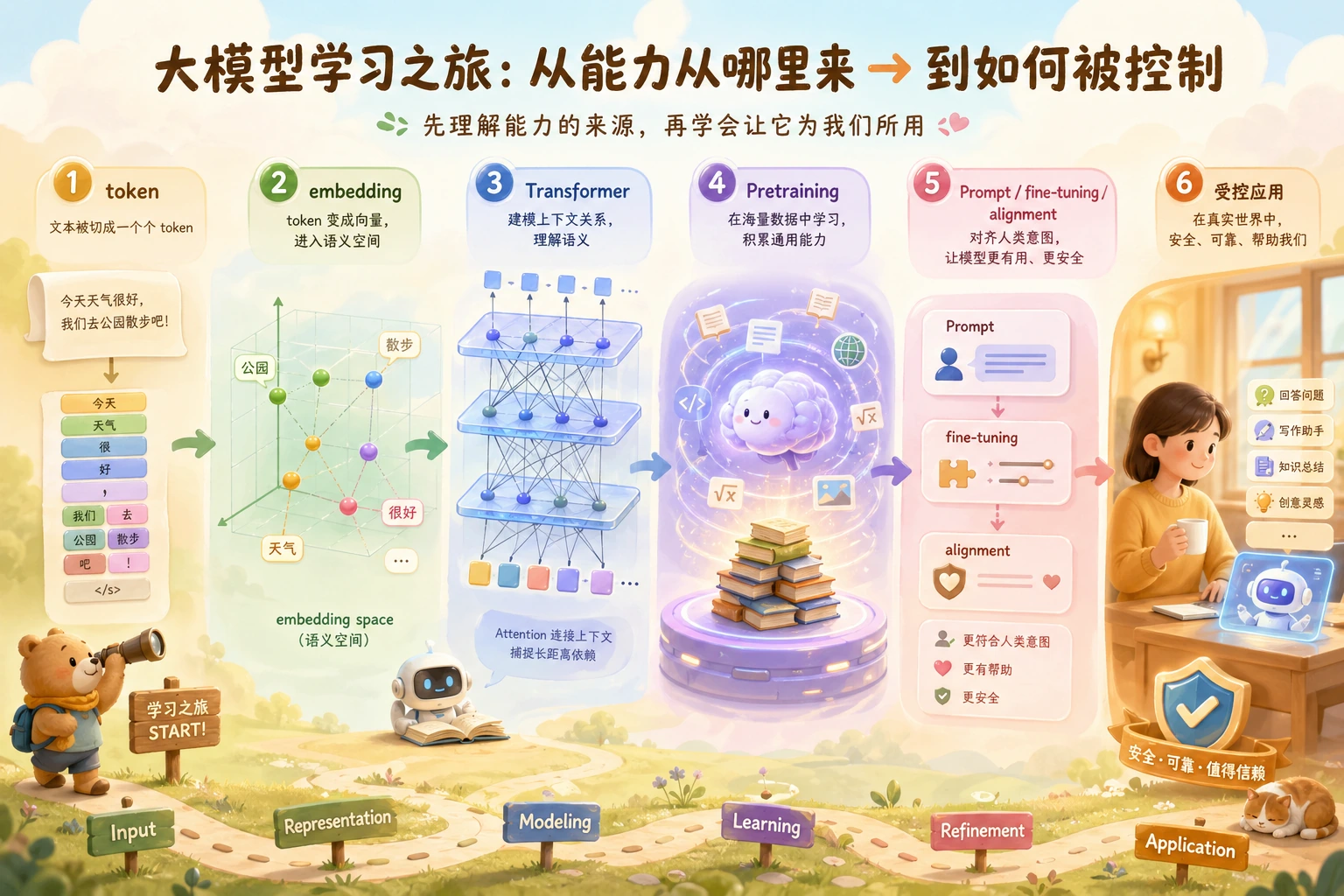
两小时快速通读
| 时间 | 做什么 | 能说出这句话就停 |
|---|---|---|
| 20 分钟 | 看入口页的“Token 到答案”图 | “文本会变成 token、向量、上下文,再进行下一个 token 预测。” |
| 25 分钟 | 浏览 7.1,并运行一个 tokenizer 示例 | “Token 数量会影响成本和上下文限制。” |
| 25 分钟 | 浏览 7.2 和大模型发展史 | “规模、数据、Transformer 和对齐改变了模型能力。” |
| 30 分钟 | 运行入口页的 Prompt 测试脚本 | “我能用固定样本比较 Prompt 版本。” |
| 20 分钟 | 阅读方案选择表 | “在检查 Prompt、RAG、工具和校验前,不该急着微调。” |
必须留下的证据
| 证据 | 最小版本 |
|---|---|
prompts/ | 同一个任务的三个 Prompt 版本 |
prompt_eval_cases.csv | 至少五条固定输入和一个简单分数字段 |
structured_output_schema.json | 必填字段和允许的数据类型 |
failure_cases.md | 至少三个失败输出和可能原因 |
llm_stage_workshop_output.txt | 7.8.4 实操:第 7 章完整工作坊 的输出 |
README.md | 如何运行、哪些通过、哪些失败、下一步怎么试 |
质量闸门
| 闸门 | 通过条件 |
|---|---|
| Prompt 对比 | 同一批样本、只改一个变量、保存输出和分数。 |
| 结构化输出 | 解析器会拒绝缺字段或类型错误。 |
| 失败分析 | 每个失败都有可能原因:指令、输入、schema、缺少知识或安全边界。 |
| 方法选择 | 决策表能解释为什么先用 Prompt、RAG、微调、工具或 Agent。 |
离章问题
- 你能不照抄定义,解释 token、embedding、attention、上下文窗口、预训练、Prompt、微调和对齐吗?
- 你能每次只改一个 Prompt 变量,并用同一组输入比较结果吗?
- 你能校验 JSON 输出,而不是相信“看起来像 JSON”的文本吗?
- 你能说明什么时候缺少信息应该用 RAG,而不是继续加长 Prompt 吗?
- 你能说明什么时候“长期行为适配”才可能值得微调吗?
如果答案都是可以,就进入第 8 章。第 8 章会把这些概念接到真实 LLM 应用和 RAG 系统里。