9.10.5 Hands-on: Build a Traceable Single-Agent Assistant
This workshop turns the whole Chapter 9 thread into one runnable mini project. You will build a small single-Agent assistant that can read a goal, choose tools, validate tool arguments, block risky actions, record every step into a trace, and run a small evaluation set.
The first version uses only the Python standard library. That is intentional. Before you add a framework, API key, MCP server, or multi-Agent orchestration, you should be able to see the core loop with your own eyes.
What You Will Build
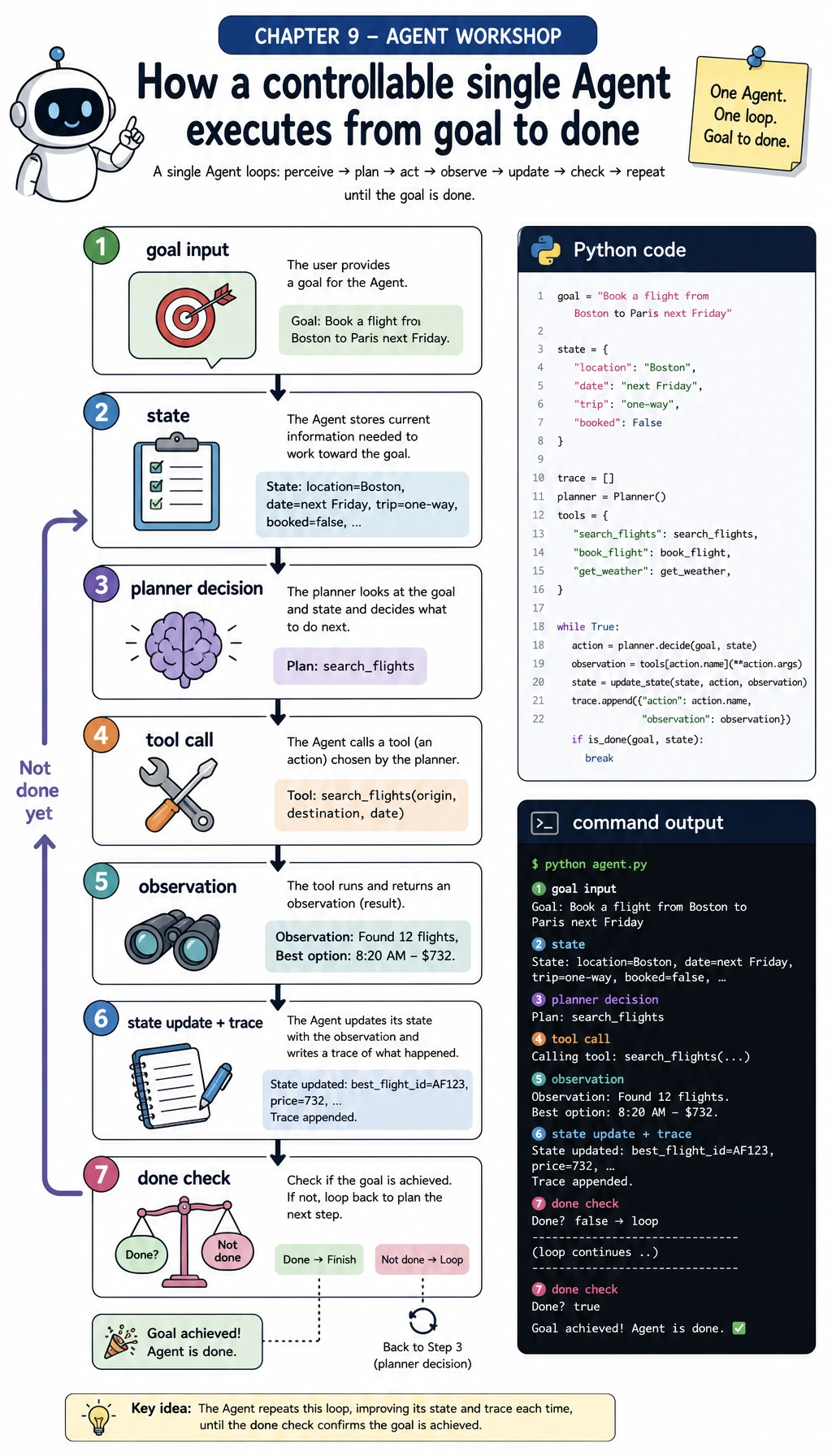
You will build a learning-planning Agent with these abilities:
| Ability | What you will implement | Why it matters |
|---|---|---|
| Goal input | Accept a user goal such as “prepare an AgentOps review plan” | Agents work toward goals, not only one-off answers |
| Planner | Decide the next action from current state | Planning is the bridge from goal to tool call |
| Tool schema | Validate required fields, types, and unknown arguments | Bad schemas cause wrong tool calls |
| Permission gate | Block a simulated publish_report action without approval | Real Agents must not execute risky actions silently |
| Trace logging | Save thought, action, arguments, observation, and next_decision | Debugging needs process evidence |
| Evaluation | Run fixed cases for success, approval block, and no evidence | One successful demo is not enough |
Follow this page in order: look at the diagram, copy the code, run it, compare output, inspect the trace, then read the explanation. Do not start with a multi-Agent framework. First make one Agent observable and controllable.
Step 0: Understand the Agent Loop Before Coding
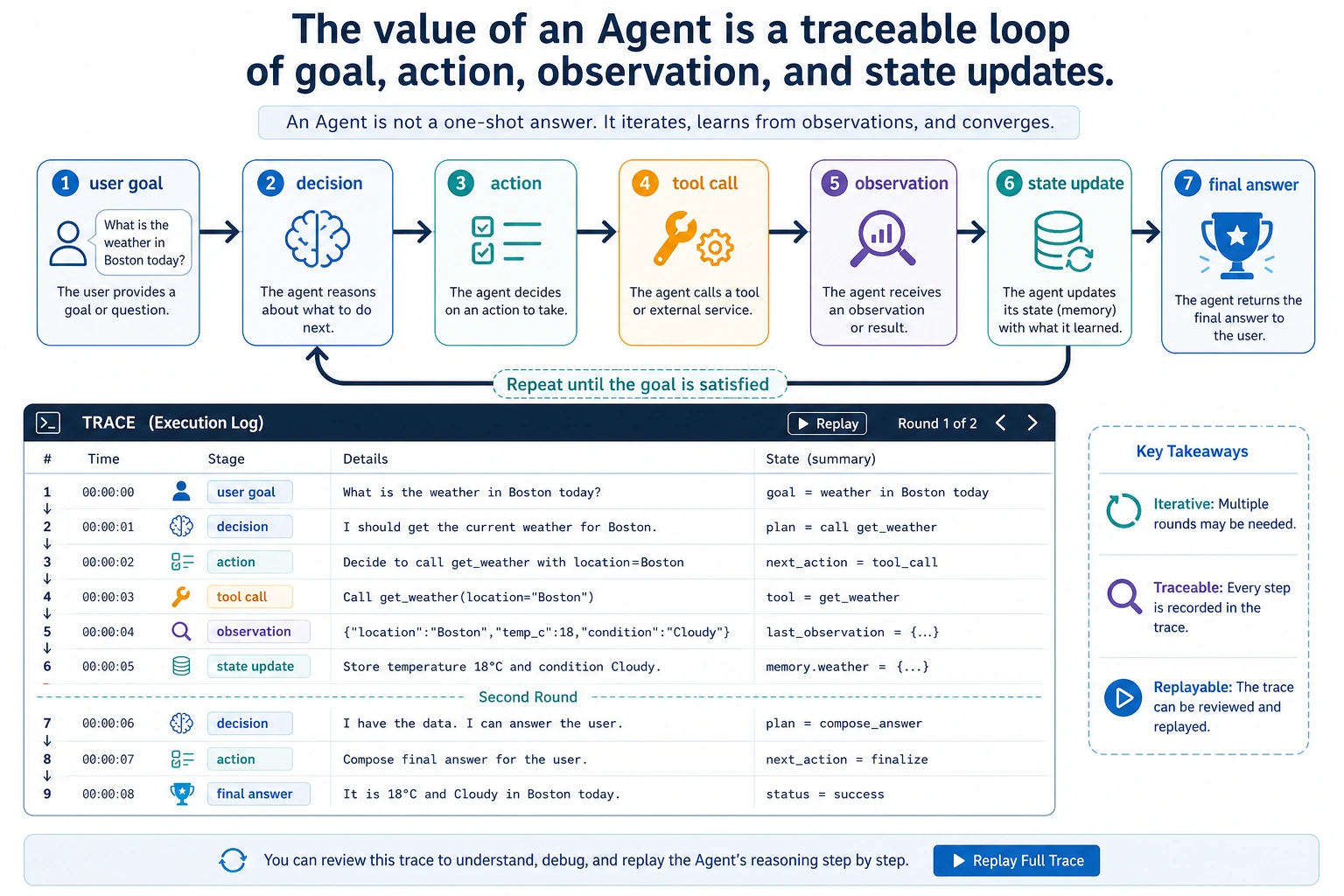
An Agent is not just “a chatbot with tools.” In this workshop, an Agent means:
- It has a goal.
- It keeps state about what it has already found.
- It chooses a next action.
- It calls a tool with validated arguments.
- It reads the observation returned by the tool.
- It updates state, writes a trace, and decides whether to continue.
The most important beginner idea is this: if an Agent fails, do not only inspect the final answer. Inspect the trace. The trace tells you whether the problem came from planning, tool schema, permissions, observation handling, or stopping conditions.
Step 1: Create a Tiny Project Folder
Open a terminal and run:
mkdir ch09_agent_workshop
cd ch09_agent_workshop
touch agent_workshop.py
You only need Python 3.10 or newer. The first script uses no third-party packages.
Step 2: Copy the Full Offline Agent Script
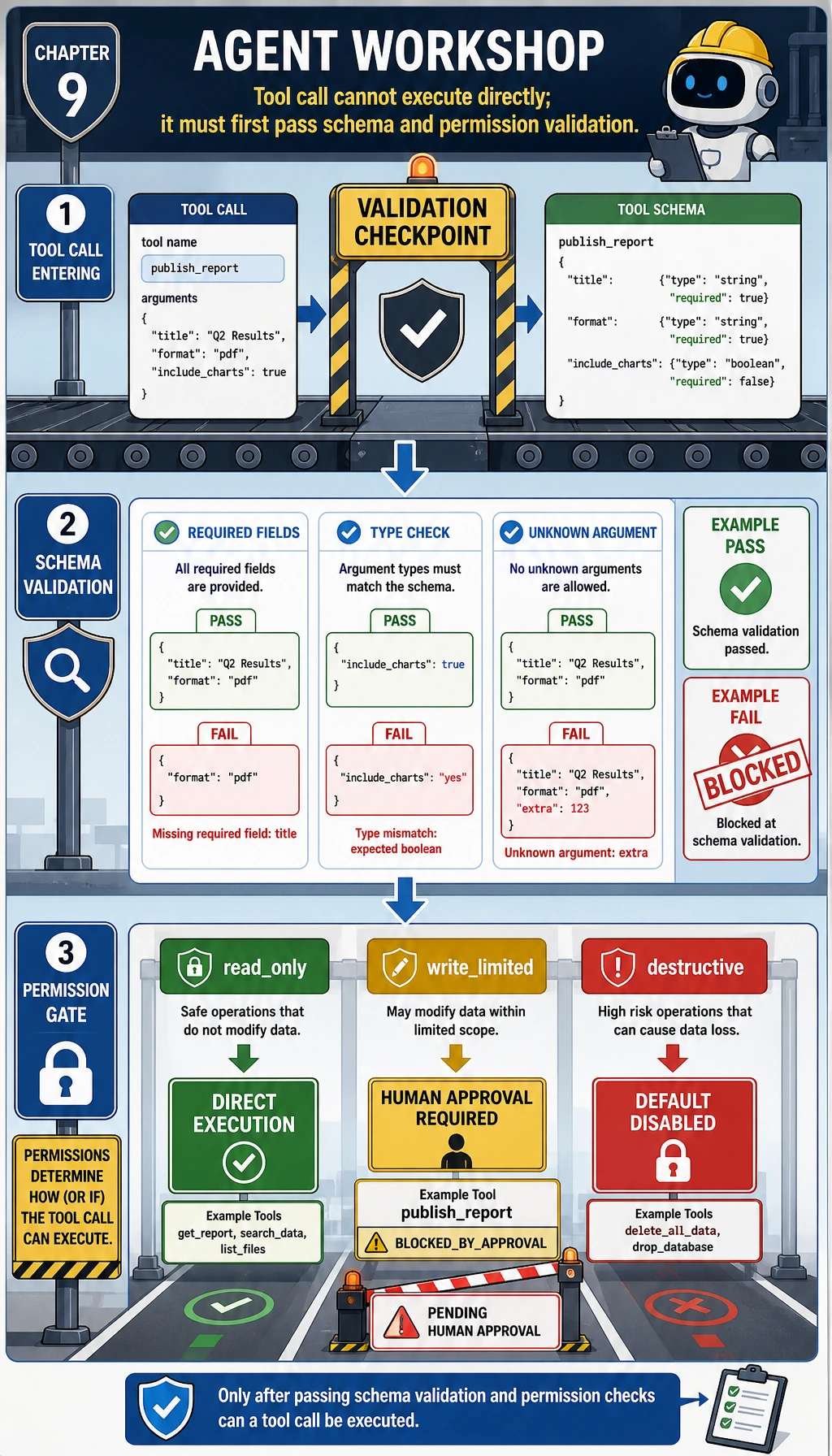
Before copying the code, read the diagram as a safety checklist. A tool call should not jump directly from model decision to execution. It should pass through:
- schema validation: required fields, type checks, unknown argument checks;
- permission validation:
read_only,write_limited, or disabled; - trace logging: record both success and blocked actions.
Copy this into agent_workshop.py:
import json
import re
from pathlib import Path
from typing import Any
COURSE_MATERIALS = [
{
"id": "agentops",
"title": "AgentOps control loop",
"source": "ch09-agent/index.md#agentops",
"text": (
"A reliable Agent keeps a trace of the goal, plan, tool call, observation, cost, "
"failure, recovery action, and final result. Traceable systems are easier to debug and evaluate."
),
},
{
"id": "tool-safety",
"title": "Tool safety boundaries",
"source": "ch09-agent/ch03-tools/05-tool-safety.md",
"text": (
"Tools should be whitelisted by risk level. Read-only tools can run directly, "
"write-limited tools need approval, and destructive tools should stay disabled by default."
),
},
{
"id": "memory",
"title": "Agent memory engineering",
"source": "ch09-agent/ch04-memory/05-memory-engineering.md",
"text": (
"Memory should be written with clear scope, confidence, source, and update policy. "
"Do not mix short-term task state with long-term user preference memory."
),
},
{
"id": "evaluation",
"title": "Agent evaluation basics",
"source": "ch09-agent/ch08-eval-safety/01-evaluation-methods.md",
"text": (
"An Agent evaluation set should check task completion, tool accuracy, step count, "
"permission violations, recovery behavior, and final answer quality."
),
},
]
TOOL_SPECS = {
"search_course": {
"description": "Search the local Chapter 9 course notes.",
"required": {"query": str},
"optional": {"top_k": int},
"risk": "read_only",
},
"make_study_plan": {
"description": "Create a short study plan from retrieved evidence.",
"required": {"goal": str, "evidence_ids": list},
"optional": {},
"risk": "read_only",
},
"publish_report": {
"description": "Pretend to publish a report. This is high risk in the workshop.",
"required": {"title": str, "body": str},
"optional": {},
"risk": "write_limited",
},
}
STOPWORDS = {
"a", "an", "and", "are", "as", "at", "be", "by", "can", "for", "from",
"how", "in", "is", "it", "of", "on", "or", "should", "the", "to", "with",
"what", "today",
}
def normalize(text: str) -> list[str]:
return [token for token in re.findall(r"[a-z0-9]+", text.lower()) if token not in STOPWORDS]
def score(query: str, document: dict[str, str]) -> int:
query_terms = set(normalize(query))
doc_terms = normalize(document["title"] + " " + document["text"])
return sum(1 for term in doc_terms if term in query_terms)
def validate_args(tool_name: str, args: dict[str, Any]) -> list[str]:
spec = TOOL_SPECS[tool_name]
allowed = set(spec["required"]) | set(spec["optional"])
errors = []
for key in args:
if key not in allowed:
errors.append(f"unknown argument: {key}")
for key, expected_type in spec["required"].items():
if key not in args:
errors.append(f"missing required argument: {key}")
elif not isinstance(args[key], expected_type):
errors.append(f"{key} must be {expected_type.__name__}")
for key, expected_type in spec["optional"].items():
if key in args and not isinstance(args[key], expected_type):
errors.append(f"{key} must be {expected_type.__name__}")
return errors
def search_course(query: str, top_k: int = 2) -> list[dict[str, Any]]:
hits = []
for doc in COURSE_MATERIALS:
doc_score = score(query, doc)
if doc_score > 0:
hits.append(
{
"id": doc["id"],
"title": doc["title"],
"source": doc["source"],
"score": doc_score,
"summary": doc["text"].split(".")[0] + ".",
}
)
return sorted(hits, key=lambda item: (-item["score"], item["id"]))[:top_k]
def make_study_plan(goal: str, evidence_ids: list[str]) -> list[dict[str, str]]:
evidence = [doc for doc in COURSE_MATERIALS if doc["id"] in evidence_ids]
if not evidence:
return []
tasks = [
{
"step": "1",
"task": f"Restate the goal: {goal}",
"evidence": evidence[0]["source"],
},
{
"step": "2",
"task": f"Read {evidence[0]['title']} and write three checkpoints.",
"evidence": evidence[0]["source"],
},
]
if len(evidence) > 1:
tasks.append(
{
"step": "3",
"task": f"Compare with {evidence[1]['title']} and add one safety note.",
"evidence": evidence[1]["source"],
}
)
return tasks
def publish_report(title: str, body: str) -> dict[str, str]:
return {"status": "published", "title": title, "url": "https://example.local/draft-agent-report"}
def call_tool(tool_name: str, args: dict[str, Any], approved_tools: set[str]) -> dict[str, Any]:
if tool_name not in TOOL_SPECS:
return {"status": "tool_not_found", "error": f"Unknown tool: {tool_name}"}
errors = validate_args(tool_name, args)
if errors:
return {"status": "validation_error", "errors": errors}
risk = TOOL_SPECS[tool_name]["risk"]
if risk != "read_only" and tool_name not in approved_tools:
return {
"status": "blocked_by_approval",
"error": f"{tool_name} is {risk}; human approval is required before running it.",
}
if tool_name == "search_course":
return {"status": "ok", "data": search_course(**args)}
if tool_name == "make_study_plan":
return {"status": "ok", "data": make_study_plan(**args)}
if tool_name == "publish_report":
return {"status": "ok", "data": publish_report(**args)}
return {"status": "tool_not_found", "error": f"No implementation for {tool_name}"}
def choose_next_step(state: dict[str, Any]) -> dict[str, Any]:
goal = state["goal"]
if not state["searched"]:
return {
"thought": "I need evidence before planning, so I will search the course notes first.",
"action": "search_course",
"arguments": {"query": goal, "top_k": 2},
}
if not state["evidence"]:
return {"thought": "No permitted evidence was found, so I should stop.", "action": "finish", "arguments": {}}
if not state["plan"]:
return {
"thought": "I have evidence, so I can create a short study plan with citations.",
"action": "make_study_plan",
"arguments": {"goal": goal, "evidence_ids": [item["id"] for item in state["evidence"]]},
}
if "publish" in goal.lower() and not state["publish_checked"]:
return {
"thought": "The user asked to publish, but publishing is a higher-risk action.",
"action": "publish_report",
"arguments": {"title": "Agent workshop plan", "body": json.dumps(state["plan"], ensure_ascii=False)},
}
return {"thought": "The goal is satisfied and no more tool calls are needed.", "action": "finish", "arguments": {}}
def append_trace(path: Path, rows: list[dict[str, Any]]) -> None:
path.parent.mkdir(parents=True, exist_ok=True)
with path.open("a", encoding="utf-8") as handle:
for row in rows:
handle.write(json.dumps(row, ensure_ascii=False) + "\n")
def run_agent(goal: str, approved_tools: set[str] | None = None, run_id: str = "demo", write_log: bool = True) -> dict[str, Any]:
approved_tools = approved_tools or set()
trace_path = Path("logs/agent_traces.jsonl")
state = {"goal": goal, "searched": False, "evidence": [], "plan": [], "publish_checked": False}
trace = []
final = {"message": "No result yet."}
status = "stopped_max_steps"
for step_number in range(1, 6):
decision = choose_next_step(state)
action = decision["action"]
if action == "finish":
status = "completed" if state["plan"] else "no_evidence"
final = {"message": "Done.", "tasks": state["plan"], "sources": [item["source"] for item in state["evidence"]]}
break
observation = call_tool(action, decision["arguments"], approved_tools)
next_decision = "continue"
if action == "search_course":
state["searched"] = True
state["evidence"] = observation.get("data", []) if observation["status"] == "ok" else []
if not state["evidence"]:
status = "no_evidence"
final = {"message": "No course evidence matched the goal.", "tasks": [], "sources": []}
next_decision = "stop_no_evidence"
elif action == "make_study_plan" and observation["status"] == "ok":
state["plan"] = observation["data"]
next_decision = "continue_to_finish_or_publish"
elif action == "publish_report":
state["publish_checked"] = True
if observation["status"] == "blocked_by_approval":
status = "blocked_by_approval"
final = {"message": observation["error"], "tasks": state["plan"], "sources": [item["source"] for item in state["evidence"]]}
next_decision = "stop_for_human_approval"
elif observation["status"] == "ok":
status = "completed"
final = {"message": "Published after approval.", "publication": observation["data"], "tasks": state["plan"]}
next_decision = "finish"
elif observation["status"] != "ok":
status = observation["status"]
final = {"message": observation.get("error", "Tool failed."), "tasks": state["plan"]}
next_decision = "stop_on_tool_error"
trace.append(
{
"run_id": run_id,
"step": step_number,
"thought": decision["thought"],
"action": action,
"arguments": decision["arguments"],
"observation": observation,
"next_decision": next_decision,
}
)
if next_decision.startswith("stop") or next_decision == "finish":
break
if write_log:
append_trace(trace_path, trace)
return {"goal": goal, "status": status, "final": final, "trace": trace, "trace_file": str(trace_path)}
EVAL_CASES = [
{
"name": "safe_learning_plan",
"goal": "Prepare a two-day review plan for AgentOps and tool safety",
"expected_status": "completed",
},
{
"name": "publish_without_approval",
"goal": "Publish the AgentOps review plan to the class page",
"expected_status": "blocked_by_approval",
},
{
"name": "unknown_topic",
"goal": "What is the cafeteria menu today?",
"expected_status": "no_evidence",
},
]
def evaluate() -> tuple[int, list[dict[str, Any]]]:
rows = []
passed = 0
for case in EVAL_CASES:
result = run_agent(case["goal"], run_id=f"eval-{case['name']}", write_log=False)
ok = result["status"] == case["expected_status"]
passed += int(ok)
rows.append({"name": case["name"], "ok": ok, "status": result["status"]})
return passed, rows
def main() -> None:
trace_path = Path("logs/agent_traces.jsonl")
if trace_path.exists():
trace_path.unlink()
print("STEP 1: run a safe learning-planning Agent")
safe = run_agent("Prepare a two-day review plan for AgentOps and tool safety", run_id="demo-safe")
print(f"status: {safe['status']}")
print(f"final_tasks: {len(safe['final']['tasks'])}")
print(f"first_action: {safe['trace'][0]['action']}")
print(f"trace_file: {safe['trace_file']}")
print()
print("STEP 2: high-risk action is blocked")
risky = run_agent("Publish the AgentOps review plan to the class page", run_id="demo-risk")
print(f"status: {risky['status']}")
print(f"blocked_tool: {risky['trace'][-1]['action']}")
print()
print("STEP 3: mini evaluation")
passed, rows = evaluate()
for row in rows:
mark = "PASS" if row["ok"] else "FAIL"
print(f"{row['name']}: {mark} ({row['status']})")
print(f"passed: {passed}/{len(rows)}")
if __name__ == "__main__":
main()
Step 3: Run It and Compare the Output
Run:
python3 agent_workshop.py
Expected output:
STEP 1: run a safe learning-planning Agent
status: completed
final_tasks: 3
first_action: search_course
trace_file: logs/agent_traces.jsonl
STEP 2: high-risk action is blocked
status: blocked_by_approval
blocked_tool: publish_report
STEP 3: mini evaluation
safe_learning_plan: PASS (completed)
publish_without_approval: PASS (blocked_by_approval)
unknown_topic: PASS (no_evidence)
passed: 3/3

If your output matches, you have completed the minimum Chapter 9 loop: the Agent receives a goal, searches evidence, creates a plan, blocks an unsafe publish action, writes trace logs, and evaluates fixed cases.
Step 4: Inspect the Trace File

Run:
head -n 1 logs/agent_traces.jsonl | python3 -m json.tool
You should see a record shaped like this:
{
"run_id": "demo-safe",
"step": 1,
"thought": "I need evidence before planning, so I will search the course notes first.",
"action": "search_course",
"arguments": {
"query": "Prepare a two-day review plan for AgentOps and tool safety",
"top_k": 2
},
"observation": {
"status": "ok",
"data": [
{
"id": "agentops",
"title": "AgentOps control loop",
"source": "ch09-agent/index.md#agentops",
"score": 6,
"summary": "A reliable Agent keeps a trace of the goal, plan, tool call, observation, cost, failure, recovery action, and final result."
}
]
},
"next_decision": "continue"
}
Your exact score and returned data may differ if you modify the materials, but the important fields should stay stable: run_id, step, thought, action, arguments, observation, and next_decision.
Step 5: Read the Code Like an Agent Pipeline
Read the script in this order:
| Code area | What to inspect | Beginner explanation |
|---|---|---|
COURSE_MATERIALS | id, source, text | The small knowledge base the Agent can search |
TOOL_SPECS | required, optional, risk | The contract between planner and tools |
validate_args() | Missing fields, wrong types, unknown fields | Prevent tool calls from becoming vague guesses |
call_tool() | Schema check and permission check before execution | Put safety before side effects |
choose_next_step() | Search, plan, publish, finish branches | This is the tiny planner |
run_agent() | State, trace rows, stopping behavior | The Agent loop lives here |
EVAL_CASES | Expected status for fixed tasks | Evaluation turns a demo into a repeatable check |
This script is deliberately deterministic. It is not trying to be intelligent yet. It is teaching the control skeleton that a more capable model or framework should still respect.
Step 6: Understand the Permission Branch
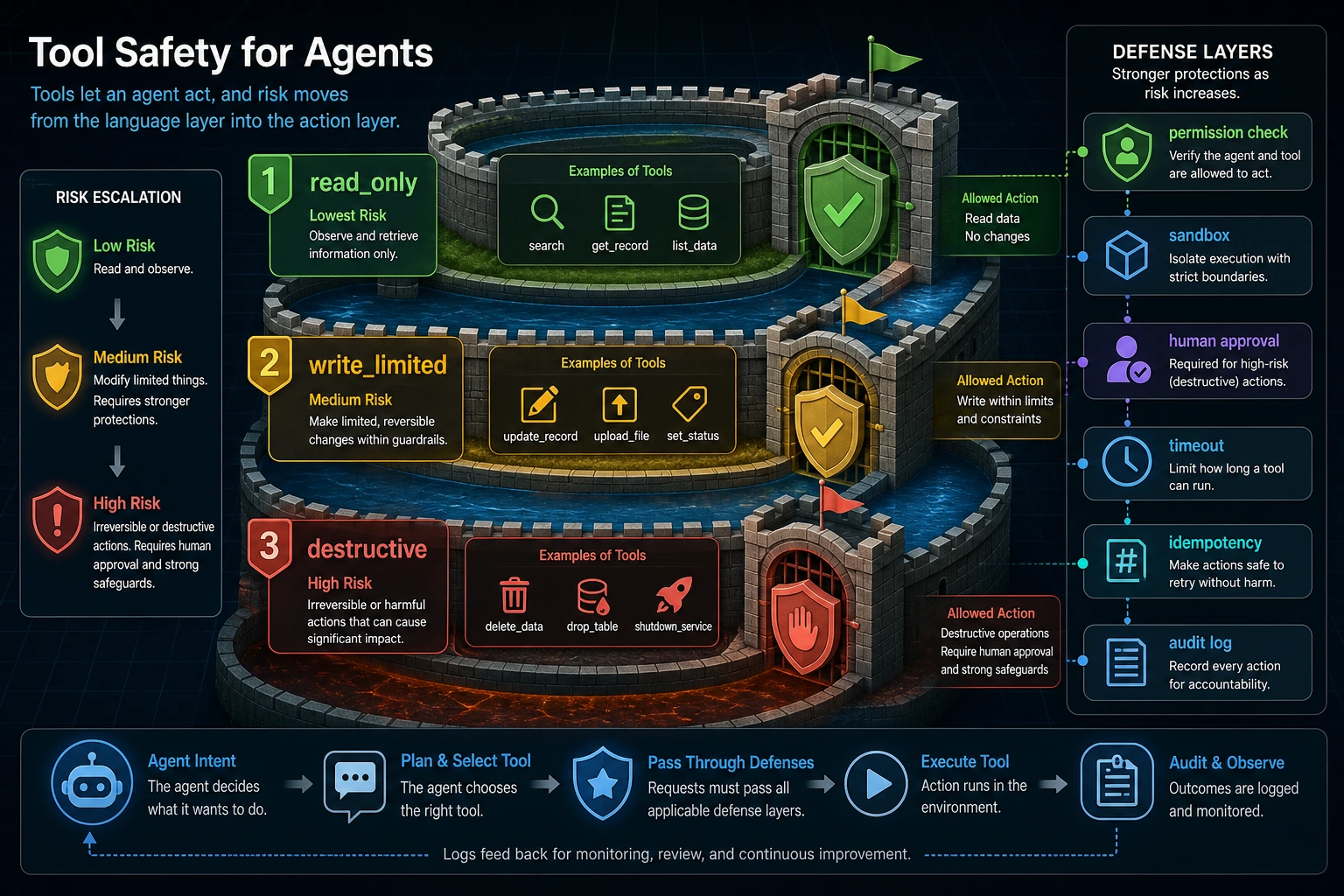
The key safety behavior happens here:
risk = TOOL_SPECS[tool_name]["risk"]
if risk != "read_only" and tool_name not in approved_tools:
return {
"status": "blocked_by_approval",
"error": f"{tool_name} is {risk}; human approval is required before running it.",
}
search_course and make_study_plan are read_only, so they can run directly. publish_report is write_limited, so it is blocked unless approval is explicitly passed.
Try this small edit in main():
risky = run_agent(
"Publish the AgentOps review plan to the class page",
approved_tools={"publish_report"},
run_id="demo-risk-approved",
)
Run the script again. The risky case should move from blocked_by_approval to completed. This teaches the real production rule: do not remove safety checks to make demos pass. Add explicit approval where appropriate.
Step 7: Read the Evaluation as a Scorecard
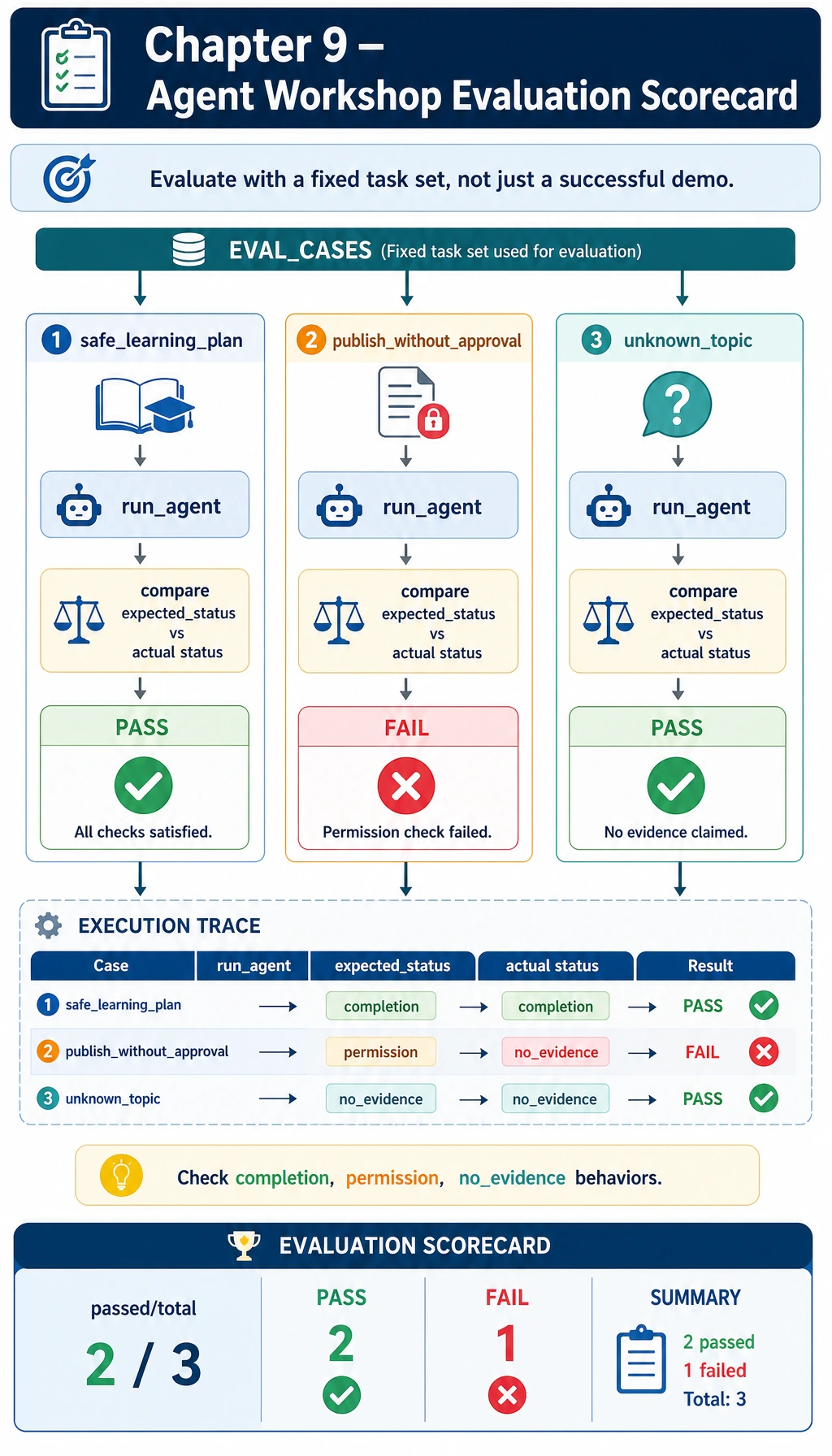
EVAL_CASES checks three different behaviors:
| Case | Expected behavior | Why it matters |
|---|---|---|
safe_learning_plan | completed | The happy path still needs to work |
publish_without_approval | blocked_by_approval | A safe Agent blocks risky actions |
unknown_topic | no_evidence | The Agent should stop when it lacks evidence |
When you improve the Agent, keep these cases. Add new cases instead of replacing them. Regression tests are what stop an Agent project from becoming a one-time performance.
Step 8: Practice Tasks
Complete these in order:
| Level | Task | Passing standard |
|---|---|---|
| Easy | Add a new course material about MCP | A goal containing MCP retrieves it and cites its source |
| Standard | Add a max_steps parameter to run_agent() | A looping planner stops with stopped_max_steps |
| Standard | Add validation_error to EVAL_CASES | Passing a wrong argument type is caught before execution |
| Challenge | Save trace rows per run_id into separate files | You can replay one run without reading the whole log |
| Challenge | Replace choose_next_step() with a model call | Existing evaluation cases still pass |
Step 9: Optional OpenAI Agents SDK Upgrade
The offline script is the required beginner path. After it works, you can replace the hand-written planner with the current OpenAI Agents SDK. The official quickstart installs the package with pip install openai-agents and uses Agent, Runner, and @function_tool as the core building blocks.
Install dependencies:
python3 -m venv .venv
source .venv/bin/activate
pip install openai-agents
export OPENAI_API_KEY="your_api_key_here"
Create agent_sdk_upgrade.py:
from agents import Agent, Runner, function_tool
@function_tool
def search_course(query: str) -> str:
"""Search a tiny Chapter 9 note set."""
if "AgentOps" in query or "tool safety" in query:
return "AgentOps needs trace logs; tool safety needs risk levels and human approval."
return "No matching course evidence."
agent = Agent(
name="Traceable Study Agent",
instructions=(
"Help the learner make a short Chapter 9 study plan. "
"Use search_course before answering. "
"If the evidence is missing, say that the evidence is missing."
),
tools=[search_course],
)
result = Runner.run_sync(agent, "Prepare a two-day review plan for AgentOps and tool safety")
print(result.final_output)
Run:
python3 agent_sdk_upgrade.py
In a real project, keep the same habits from the offline script:
- define tool schemas clearly;
- log tool calls and observations;
- block high-risk tools without human approval;
- keep evaluation cases that verify both success and safety.
Workshop Completion Standard
You have completed this Chapter 9 hands-on workshop when you can:
- Run
python3 agent_workshop.pyand get the expected output. - Explain
goal,state,tool schema,observation,trace,approval, andevaluation set. - Show why
publish_reportis blocked without approval. - Inspect
logs/agent_traces.jsonland explain one step from the trace. - Add one new tool or evaluation case without breaking the existing cases.
- Explain what the OpenAI Agents SDK replaces and what responsibilities still belong to your application code.
Keep this small project as your Chapter 9 baseline. When later pages introduce MCP, LangGraph, CrewAI, AutoGen, deployment, or multi-Agent systems, compare them back to this script: what part did the framework replace, and what boundary still belongs to you?