从 TD-Gammon 到 AlphaGo:强化学习怎样影响 Agent
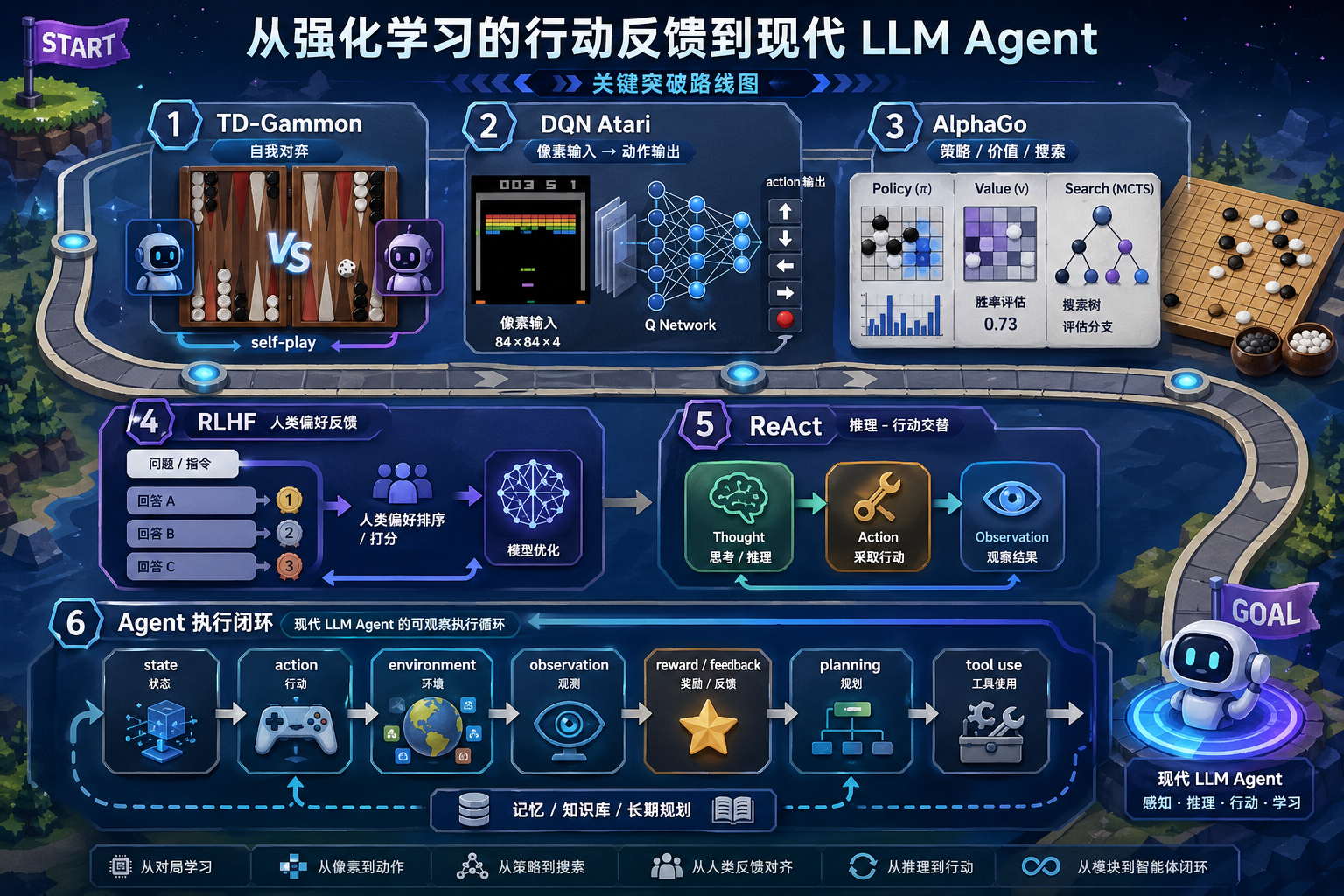
现代 LLM Agent 不等于强化学习,但 Agent 这个概念和强化学习历史有很深的关系。
这一节先抓住三个故事:
TD-Gammon 证明机器可以从自我对弈中变强,DQN 证明深度网络可以从像素和奖励中学策略,AlphaGo 证明学习、搜索和规划结合后可以打穿复杂博弈。
一、为什么 Agent 课程要补强化学习历史?
Agent 关心的是:
- 在环境里观察状态
- 决定下一步行动
- 根据反馈调整策略
- 为长期目标做规划
这和强化学习的基本问题高度相似。
| 强化学习语言 | Agent 系统语言 |
|---|---|
| state | 当前上下文、任务状态 |
| action | 工具调用、回复、计划步骤 |
| reward | 用户反馈、评估分数、任务是否完成 |
| policy | 决策策略、调用工具的规则 |
| environment | 外部系统、知识库、浏览器、代码仓库 |
所以强化学习历史不是旁支,它帮你理解 Agent 为什么要关心反馈、规划、试错和安全边界。
二、TD-Gammon:从自我对弈里学策略
1992 年左右,Gerald Tesauro 的 TD-Gammon 用时序差分学习在西洋双陆棋上达到很强水平。
它有一个很吸引人的点:
系统不只是模仿人类棋谱,而是通过大量自我对弈,从结果反馈里改进判断。
对新人来说,可以这样理解:
| 普通监督学习 | TD-Gammon 的味道 |
|---|---|
| 每一步都有标准答案 | 很多时候只有最后输赢反馈 |
| 重点是拟合标签 | 重点是学会长期策略 |
| 数据通常由人提供 | 系统可以通过自我对弈产生经验 |
这给后来的强化学习和博弈 AI 打开了一个重要想象:
如果系统能自己产生经验,它就不完全受限于人工标注数据。
三、DQN Atari:从像素到动作
2015 年,DeepMind 的 DQN 在 Atari 游戏上取得突破。
它的重要性在于把深度学习和强化学习结合起来:
- 输入是游戏画面像素
- 输出是下一步动作
- 反馈来自游戏得分
这件事很像让模型从“看屏幕”开始学玩游戏。
游戏画面 -> 神经网络 -> 动作 -> 分数反馈 -> 更新策略
它对现代 Agent 的启发是:
- Agent 不一定只处理静态文本
- Agent 可以在环境里连续行动
- 行动会改变后续状态
- 评价不一定每一步都立刻出现
这也是为什么 Agent 评估比普通问答评估更难。
四、AlphaGo:学习、搜索和规划合在一起
2016 年 AlphaGo 战胜李世石,让很多人第一次非常直观地感受到 AI 的突破。
AlphaGo 的关键不是“一个神经网络直接下棋”,而是多种能力组合:
| 能力 | 在 AlphaGo 里的角色 | 对 Agent 的启发 |
|---|---|---|
| 策略网络 | 判断下一步候选走法 | 生成可行动作 |
| 价值网络 | 估计局面好坏 | 评估当前计划 |
| 蒙特卡罗树搜索 | 向未来多走几步看结果 | 规划和搜索 |
| 自我对弈 | 产生更多训练经验 | 从反馈中改进 |
对 Agent 来说,这个启发非常重要:
强系统往往不是一个模型单点发力,而是模型、搜索、工具、反馈和约束一起工作。
五、这条线和 LLM Agent 有什么关系?
现代 LLM Agent 的核心不一定是 RL 算法,但它继承了强化学习的很多问题:
| 经典 RL 问题 | LLM Agent 版本 |
|---|---|
| 奖励怎么定义 | 任务成功、引用正确、用户满意怎样衡量 |
| 探索会不会危险 | 工具调用会不会误删文件、误发请求 |
| 长期目标怎么拆解 | 多步任务怎样规划、执行、纠错 |
| 策略怎么评估 | Agent benchmark、日志回放、人工审核 |
所以你后面学 ReAct、Plan-and-Execute、工具调用和 Agent 评估时,可以把它们看成:
语言模型时代对“行动、反馈、规划”这套老问题的新实现。
六、把历史节点分配到课程章节
| 历史节点 | 解决的问题 | 对应课程章节 |
|---|---|---|
| TD-Gammon | 从自我对弈和长期反馈中学习策略 | 9.1 Agent 历史背景、9.2 推理规划 |
| DQN / Atari | 深度网络从环境反馈中学习动作 | 9.8 Agent 评估、安全与环境交互 |
| AlphaGo | 把学习、搜索、规划结合成强系统 | 9.2 规划、9.7 多 Agent / 复杂系统 |
| RLHF | 用人类偏好调整模型行为 | 第 7 章对齐、9.8 安全评估 |
| ReAct | 让模型交替进行推理和行动 | 9.2 ReAct、9.3 工具调用 |
七、学完这一节应该形成的直觉
Agent 不是“让模型自由发挥”这么简单。
它更像一个不断在下面几件事之间平衡的系统:
- 目标
- 行动
- 环境
- 反馈
- 规划
- 安全约束
TD-Gammon、DQN 和 AlphaGo 的故事告诉我们:
真正强的智能系统,通常都不是只会回答问题,而是能在环境里行动,并根据反馈修正策略。