RAG 评估
学习目标
完成本节后,你将能够:
- 理解为什么 RAG 不能只凭单次 Demo 判断好坏
- 分清检索评估和回答评估的不同目标
- 使用一个小型样例计算简单指标
- 建立“先做评估,再做优化”的工程习惯
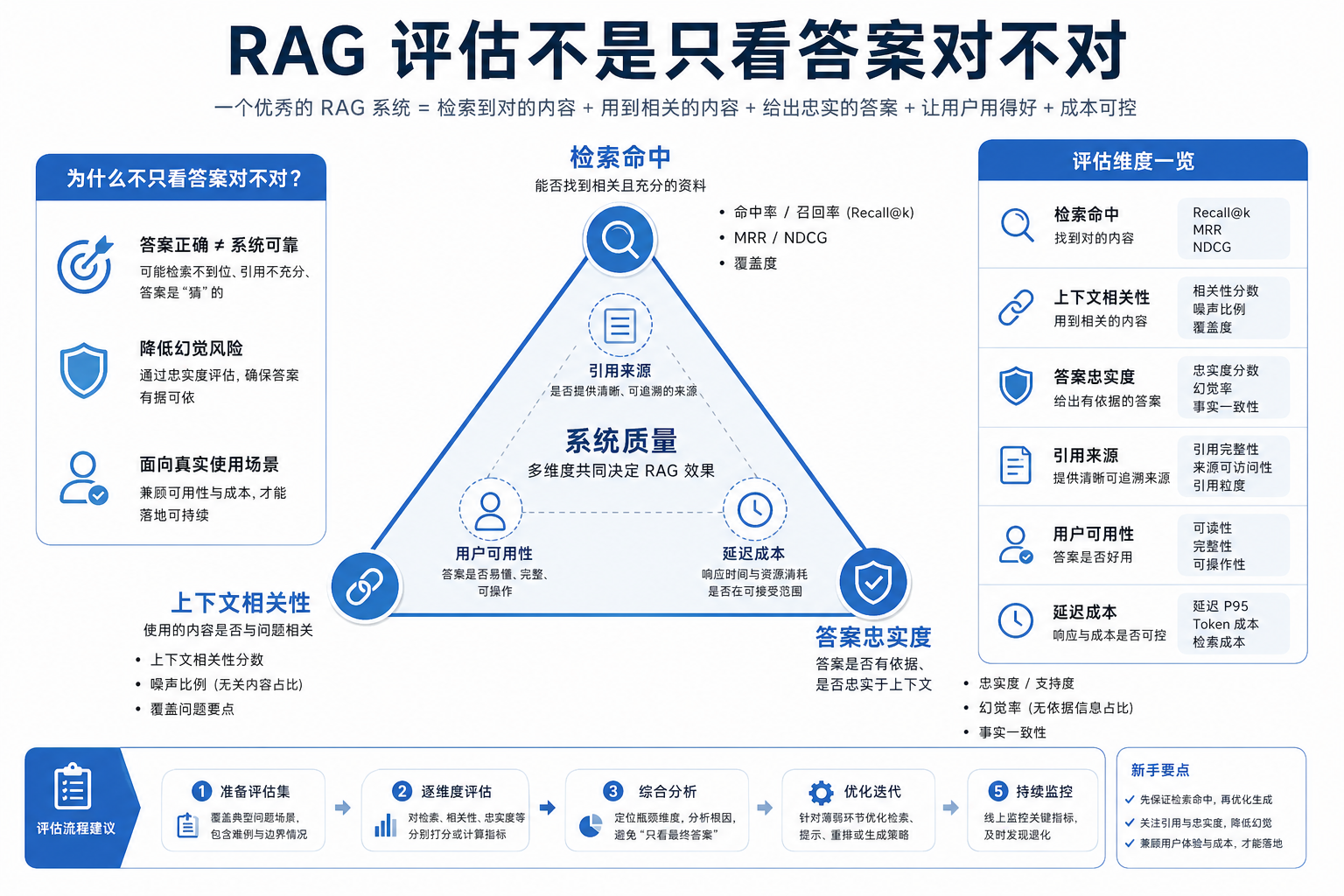
一、为什么 RAG 特别需要评估?
1.1 因为它不是单一模块
RAG 不是单个模型,而是至少包含:
- 文档处理
- 检索
- 上下文拼装
- 生成回答
任何一环出错,最终答案都可能变差。
1.2 所以不能只问“答对了吗”
你还得问:
- 是没检索到?
- 还是检索到了但没用好?
- 还是回答语言组织不好?
这就是为什么 RAG 评估必须分层看。
二、第一层:检索评估
2.1 最常见的直觉指标:Hit@k
Hit@k 的意思很简单:
正确证据有没有出现在前 k 个检索结果里?
如果用户问题的正确证据在 top-3 里,就算 hit。
2.2 为什么这个指标很重要?
因为如果正确资料根本没召回,后面的生成几乎不可能稳定答对。
所以:
检索评估是 RAG ��评估的地基。
三、第二层:回答评估
3.1 只看“语句通顺”远远不够
回答评估至少要关注:
- 答案对不对
- 有没有依据
- 有没有胡编
3.2 常见维度
| 维度 | 关注点 |
|---|---|
| Correctness | 答案事实是否正确 |
| Faithfulness | 是否基于给定资料 |
| Relevance | 是否回答了用户问题 |
| Completeness | 关键信息是否答全 |
在业务里,不同维度的重要性不一样。
四、一个最小评估数据集
下面我们手工构造一份迷你评估集。
dataset = [
{
"question": "多久内可以退款?",
"gold_doc": "退款政策",
"gold_answer": "课程购买后 7 天内可申请退款"
},
{
"question": "怎么获得证书?",
"gold_doc": "证书说明",
"gold_answer": "完成项目并通过测试后可获得证书"
}
]
predictions = [
{
"retrieved_docs": ["退款政策", "学习顺序"],
"answer": "课程购买后 7 天内可申请退款"
},
{
"retrieved_docs": ["学习顺序", "证书说明"],
"answer": "完成项目并通过测试后可获得证书"
}
]
print(dataset)
print(predictions)
五、计算一个简单的 Hit@k
5.1 可运行示例
dataset = [
{
"question": "多久内可以退款?",
"gold_doc": "退款政策"
},
{
"question": "怎么获得证书?",
"gold_doc": "证书说明"
}
]
predictions = [
{
"retrieved_docs": ["退款政策", "学习顺序"]
},
{
"retrieved_docs": ["学习顺序", "证书说明"]
}
]
hits = 0
for item, pred in zip(dataset, predictions):
if item["gold_doc"] in pred["retrieved_docs"]:
hits += 1
hit_at_2 = hits / len(dataset)
print("Hit@2 =", round(hit_at_2, 4))
如果正确文档都在前 2 个结果里,这个值就是 1.0。
5.2 这个指标的局限
它只能告诉你“有没有召回到”,却不能告诉你:
- 排在第几
- 回答是否真的正确
所以它只是第一步。
六、计算一个简单的答案正确率
6.1 最简单的 Exact Match 思路
在结构化短答案场景里,可以先用最朴素的方法:
dataset = [
{
"gold_answer": "课程购买后 7 天内可申请退款"
},
{
"gold_answer": "完成项目并通过测试后可获得证书"
}
]
predictions = [
{
"answer": "课程购买后 7 天内可申请退款"
},
{
"answer": "完成项目并通过测试后可获得证书"
}
]
correct = 0
for item, pred in zip(dataset, predictions):
if item["gold_answer"] == pred["answer"]:
correct += 1
exact_match = correct / len(dataset)
print("Exact Match =", round(exact_match, 4))
6.2 但真实场景往往没这么简单
因为同一个正确答案可能有很多不同表述方式。
所以线上系统常常还会引入:
- 语义匹配
- LLM-as-a-judge
- 人工抽检
七、Faithfulness:回答有没有根据?
7.1 这比“答得像不像”更重要
一个回答可能写得很流畅,但如果它不是基于检索资料得出的,风险就很高。
7.2 一个简化版检查思路
下面这个示例很粗糙,但能帮助你理解“回答是否被证据支持”的概念。
evidence = "课程购买后 7 天内可申请退款"
answer = "课程购买后 7 天内可申请退款"
faithful = answer in evidence or evidence in answer
print("是否被证据支持:", faithful)
真实系统里当然不会只用这种字符串判断,但思路是对的:
回答应该尽量能在检索证据里找到支撑。
八、评估集应该怎么构建?
8.1 最小可用评估集
至少包含:
- 用户问题
- 标准答案
- 正确证据文档或证据片段
8.2 评估集最好覆盖不同难度
比如:
- 简单事实问答
- 同义表达问法
- 跨段落问题
- 容易混淆的问题
如果评估集太单一,优化结果很容易失真。
九、线上评估也很重要
9.1 离线评估不能代表全部
线下数据集再好,也不可能完全覆盖真实用户问题。
9.2 常见线上信号
例如:
- 用户追问率
- 用户纠错率
- 点赞 / 点踩
- 人工质检抽样
一个成熟的 RAG 系统,通常是“离线评估 + 线上反馈”一起看。
十、如果你的目标是“知识库驱动的课件生成助手”,评估集应该多看什么?
这类项目和普通问答系统不太一样。
你不只是关心“答案像不像”,还要关心:
- 主题资料有没有找对
- 例题有没有抽对
- 最终栏目有没有放对位置
- 来源能不能回溯
所以更适合这类项目的评估表,��通常至少要多一层:
| 维度 | 更像在看什么 |
|---|---|
| 主题命中 | 这个主题的核心资料有没有找到 |
| 例题召回 | 适合作为讲解例题的材料有没有找到 |
| 结构正确性 | 概念、例题、练习有没有放进对的栏目 |
| 来源完整性 | 最终生成结果能不能回溯到原始资料 |
你可以先把它理解成:
课件生成项目的评估,不只是“答对”,而是“找对、放对、引对”。
十一、一个更像课件生成项目的最小评估样例
dataset = [
{
"topic": "折扣应用题",
"gold_concepts": ["折扣 = 原价 × 折扣率"],
"gold_examples": ["商品原价 100 元,打 8 折后价格是多少?"],
}
]
prediction = {
"concepts": ["折扣 = 原价 × 折扣率"],
"examples": ["商品原价 100 元,打 8 折后价格是多少?"],
"source_refs": [{"doc_id": "word_001", "page_or_slide": 3}],
}
print(dataset[0])
print(prediction)
这个例子虽然很小,但会帮助新人先建立一个评估直觉:
- 这类系统最终评估对象往往不是“单句答案”
- 而是一整个结构化结果
十二、初学者常见误区
12.1 只看一两个成功案例
Demo 可以激励人,但不能代替评估。
12.2 只评回答,不评检索
这样你很难定位问题究竟出在哪一层。
12.3 一边改系统,一边没固定评估集
没有固定评估集,就很难判断到底是优化还是随机波动。
RAG 项目评估指标总表
做 RAG 项目时,不要只看“回答像不像”。更稳的做法是把评估拆成检索、生成、引用和系统四层。
| 层级 | 指标 | 说明 |
|---|---|---|
| 检索层 | 命中率、Recall@K、MRR | 正确资料有没有被找出来,排得靠不靠前 |
| 生成层 | 答案正确率、完整性、一致性 | 模型有没有基于资料回答,是否遗漏关键条件 |
| 引用层 | 引用覆盖率、引用真实性 | 答案中的关键结论是否能追溯到来源 |
| 系统层 | 延迟、成本、失败率 | 能否稳定、可承受地服务真实用户 |
最小评估集建议先准备 20~50 个问题,每个问题都写上标准答案、应命中文档和关键引用。这样你优化 chunk、embedding、rerank、query rewrite 时,才知道是系统真的变好,还是只是个别样例看起来更顺眼。
分层失败归因表
评估的价值不只是算一个总分,而是帮助你知道下一步该改哪里。下面这张表可以放在实验记录里,每次失败都先归因到一层。
| 失败现象 | 归因层级 | 应该检查 | 下一步动作 |
|---|---|---|---|
| 正确文档没有进入 top-k | 检索层 | query、chunk、embedding、关键词匹配 | 调整切块、加混合检索或 query rewrite |
| 正确文档进了 top-k 但没进最终 context | 上下文层 | context packing、去重、长度限制 | 调整排序、压缩或打包策略 |
| context 里有证据但回答漏掉关键条件 | 生成层 | prompt、答案格式、模型是否按证据回答 | 要求逐条基于证据回答并保留限制条件 |
| 答案结论正确但引用不支持 | 引用层 | source_refs、引用片段、答案�句子 | 做引用真实性检查,禁止无证据引用 |
| 离线评估好但用户仍频繁追问 | 产品层 | 真实问题分布、评估集覆盖度 | 补充线上问题到评估集 |
如果你只看“最终答对率”,这些问题会被混在一起。分层归因能让优化动作更明确:检索错就不要先调 prompt,引用错就不要只看答案是否通顺。
一个可直接复制的评估记录模板
做 RAG 项目时,建议每次评估都保留一份固定格式。即使一开始只有十几条问题,也比只看单次 Demo 稳定得多。
| 字段 | 示例 | 用途 |
|---|---|---|
question | 课程多久内可以退款? | 用户问题 |
gold_doc | 退款政策 | 应该命中的资料 |
gold_answer | 课程购买后 7 天内可申请退款 | 标准答案或关键事实 |
retrieved_docs | 退款政策, 学习顺序 | 实际命中的文档 |
answer | 7 天内可申请退款 | 系统回答 |
citation_ok | true | 引用是否支持答案 |
failure_type | none / retrieval / generation / citation | 失败归因 |
notes | 命中正确,回答完整 | 人工备注 |
最小 CSV 可以长这样:
question,gold_doc,gold_answer,retrieved_docs,answer,citation_ok,failure_type,notes
课程多久内可以退款?,退款政策,课程购买后 7 天内可申请退款,"退款政策;学习顺序",课程购买后 7 天内可申请退款,true,none,命中正确且引用支持
怎么获得证书?,证书说明,完成项目并通过测试后可获得证书,"学习顺序;证书说明",完成项目后可获得证书,false,generation,漏掉通过测试这个关键条件
这个模板的重点不是字段多,而是每条样本都能回答三个问题:应该命中什么,实际命中了什么,最终答案有没有被证据支持。
课件生成 RAG 的验收 Rubric
如果项目目标是生成课件或学习材料,评估不能只停留在问答层。下面这个 rubric 可以作为作品集项目的验收表。
| 等级 | 检索要求 | 生成要求 | 引用要求 |
|---|---|---|---|
| 练习级 | 能命中主题相关资料 | 能生成基本回答或片段 | 能显示来源文件名 |
| 项目级 | 能按 topic 和 content_type 召回概念、例题、练习 | 能按固定栏目组织输出 | 每个关键栏目有来源 |
| 作品集级 | 有固定评估集和失败样本 | 能解释哪些失败来自检索、生成或模板 | 关键结论可逐条追溯到原文 |
| 面试级 | 能比较 baseline、混合检索、rerank 等策略 | 能说明质量、成本、延迟取舍 | 能做引用真实性抽检和改进记录 |
这个表可以直接放进项目 README。它会让别人看到:你不是只做了一个“能回答问题”的 Demo,而是在用工程方式评估一个知识库驱动系统。
小结
这一节最重要的认识是:
RAG 评估不是锦上添花,而是系统迭代的方向盘。
没有评估,你就只能凭感觉优化;
有了评估,你才能知道问题在哪、改动有没有真正带来收益。
练习
- 给评估集再加 3 条问题,自己手工写出
gold_doc和gold_answer。 - 修改
predictions,故意让一条回答错误,重新计算 Hit@k 和 Exact Match。 - 想一想:如果 Hit@k 很高,但最终答案依然经常错,说明问题更可能出在哪一层?