LoRA 与 QLoRA
上一节已经把“为什么不是所有任务都该全量微调”讲清楚了。
这一节继续回答一个非常关键的问题:
如果不想重训整个模型,那到底该怎样低成本改它?
LoRA 和 QLoRA 正是最重要的两条现实答案。
学习目标
- 理解 LoRA 的低秩增量直觉
- 理解 QLoRA 在 LoRA 基础上又多做了什么
- 看懂一个最小矩阵增量示意
- 建立何时考虑 LoRA、何时考虑 QLoRA 的实用判断
先建立一张地图
LoRA / QLoRA 这节最适合新人的理解顺序不是“先记缩写”,而是先看清:
这节真正想解决的是:
- LoRA 到底在省什么
- QLoRA 又是在 LoRA 基础上多解决了什么
一个更适合新人的总类比
你可以把 LoRA / QLoRA 理解成:
- 不重做整台机器,只换一个小但关键的模块
全量微调更像:
- 把整台机器全部拆开重调
LoRA 更像:
- 只加一个可训练的小改装件
QLoRA 则是在此基础上再进一步:
- 先把原机器做得更省空间,再装这个改装件
一、为什么 LoRA 会变得这么重要?
因为全量微调在大模型上往往太贵:
- 参数太多
- 显存太高
- 训练和保存成本都高
于是人们自然会问:
能不能不改整个模型,只改一小部分真正有用的东西?
LoRA 就是在回答这个问题。
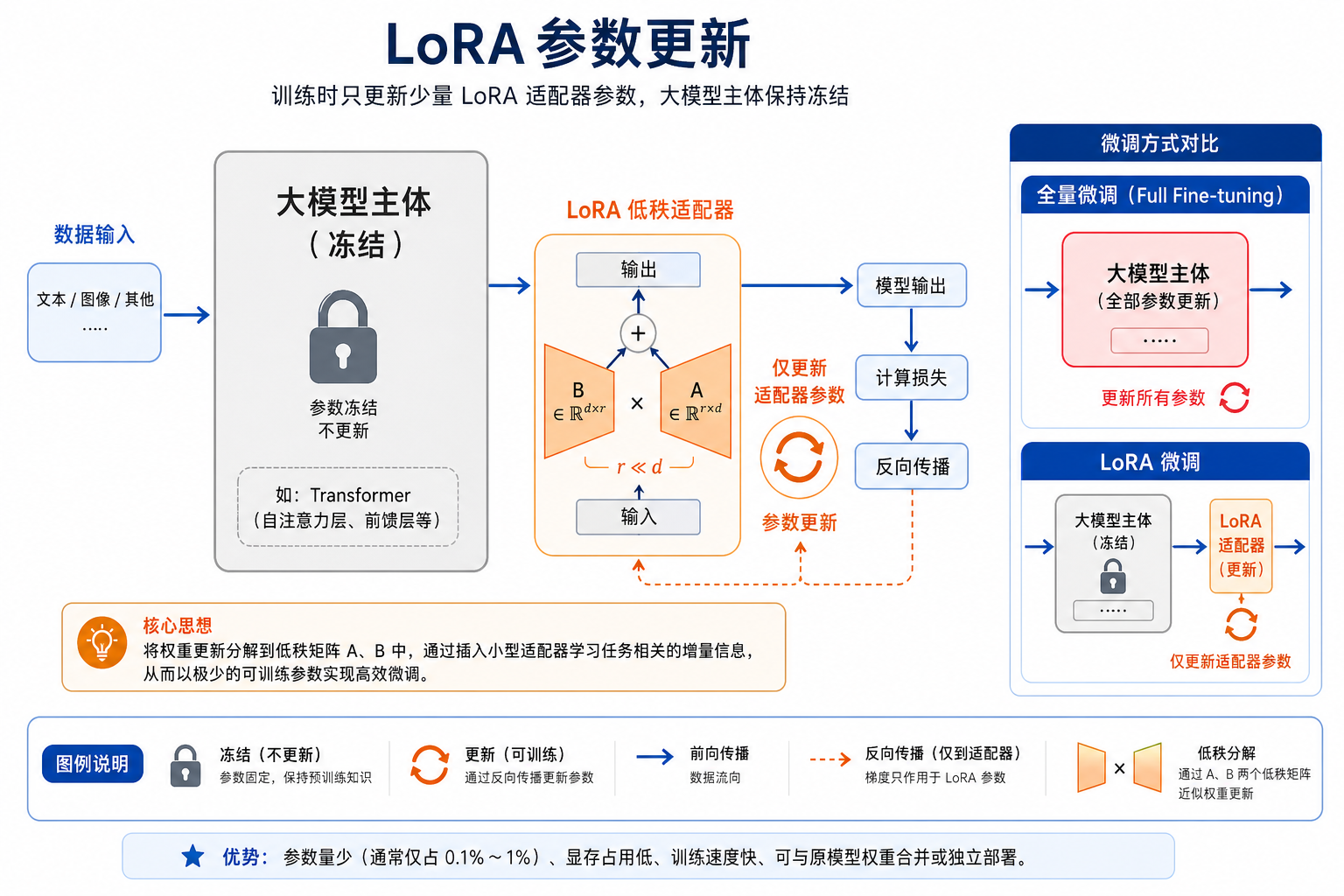
二、LoRA 最核心的直觉是什么?
2.1 不直接改整个权重矩阵
假设原来的权重矩阵是:
W
LoRA 的思路是:
不直接训练
W,而是学习一个增量ΔW
然后实际使用:
W + ΔW
2.2 为什么叫“低秩”?
因为这个增量不是直接学一个完整大矩阵,而通常写成:
ΔW = A @ B
其中:
A和B比原矩阵小很多
这就是“低秩”的核心来源。
三、一个最小 LoRA 矩阵示意
import torch
W = torch.randn(8, 8)
A = torch.randn(8, 2)
B = torch.randn(2, 8)
delta = A @ B
W_new = W + delta
print("W shape :", W.shape)
print("delta shape :", delta.shape)
print("W_new shape :", W_new.shape)
3.2 这段代码在教什么?
它在教你:
- LoRA 不重训整个权重
- 而是训练一个更小的增量结构
这就是它能省资源的根本原因。
3.3 一个很适合初学者先记的对比表
| 路线 | 最值得先记住的核心动作 |
|---|---|
| 全量微调 | 直接改原模型所有参数 |
| LoRA | 学一个小增量矩阵 |
| QLoRA | 学小增量 + 把基础模型量化 |
这个表很适合新人,因为它会把三个容易混掉的路线重新压缩成一句最关键的话。
四、为什么这能显著降低训练成本?
因为原始大矩阵如果全量训练,代价很高。
而低秩分解后的可训练部分小很多。
所以 LoRA 的核心工程价值可以先记成:
用更少的训练参数,换取足够好的任务适配能力。
这也是它为什么在实际项目中这么受欢迎。
五、QLoRA 又多解决了什么问题?
5.1 仅有 LoRA,为什么有时还不够?
即使只训练小增量参数,基础模型本体本身还是很大。
模型一加载进来,显存压力依然很高。
5.2 QLoRA 的关键点
它在 LoRA 的基础上又做了一步:
把基础模型量化到更低精度。
也就是说:
- 基础模型更省内存
- 增量适配层仍然可训练
5.3 一个最小直觉示意
config = {
"base_model_precision": "4bit",
"trainable_part": "LoRA adapters",
"goal": "在更低显存下做微调"
}
print(config)
这个示意最重要的意思是:
- LoRA:主要省训练参数
- QLoRA:在此基础上进一步省基础模型占用
5.4 再看一个最小“资源约束 -> 方案选择”示例
constraints = {
"gpu_memory_gb": 12,
"want_larger_model": True,
"task_boundary_clear": True,
}
def choose_peft_route(c):
if not c["task_boundary_clear"]:
return "先别急着微调,先把任务边界定清楚。"
if c["gpu_memory_gb"] <= 12 and c["want_larger_model"]:
return "优先考虑 QLoRA。"
return "可以先从 LoRA 开始。"
print(choose_peft_route(constraints))
这个示例很适合初学者,因为它会提醒你:
- 先看约束
- 再看方法
六、LoRA 和 QLoRA 分别更适合什么时候?
6.1 LoRA 更适合
- 资源还可以
- 不一定要把显存压到极限
- 想先快速做参数高效微调
6.2 QLoRA 更适合
- 显存很紧
- 想在更小机器上跑更大模型
也就是说:
QLoRA 更像“资源受限场景下的现实工程方案”。
6.3 第一次做项目时,怎么选更稳?
一个够实用的判断顺序是:
- 如果资源还可以,先从 LoRA 开始
- 如果显存已经明显吃紧,再优先考虑 QLoRA
- 如果你还没想清任务边界,先别急着进微调细节
6.4 如果把它做成项目或方案,最值得展示什么
最值得展示的通常不是:
- “我用了 LoRA/QLoRA”
而是:
- 你为什么没有选全量微调
- 你的资源约束是什么
- LoRA 或 QLoRA 分别解决了什么
- 这条路线在当前任务里为什么最现实
这样别人会更容易看出:
- 你理解的是微调方案选择
- 不只是知道几个缩写
七、为什么说它们改变了微调门槛?
在 LoRA / QLoRA 普及前,很多人一提大模型微调会直接想到:
- 只有大团队能做
- 机器要求极高
而它们的重要意义正在于:
把原本门槛很高的事情,拉到了更多团队和开发者可尝试的范围。
这不是小优化,而是工程可达性的变化。
八、最常见的误区
8.1 以为 LoRA / QLoRA 是“无代价增强”
它们很强,但并不是完全无代价。
8.2 以为上了 QLoRA 就不需要考虑资源了
只是更轻,不是无限轻。
8.3 只记方法名,不理解到底在改什么
真正要记住的是:
- LoRA:学增量
- QLoRA:学增量 + 基础模型量化
九、核心提醒
- LoRA 的核心是“少改参数”
- QLoRA 的核心是“少改参数 + 更省基础模型内存”
- 这两者重要,不是因为名字新,而是因为它们让微调在现实里更可做
小结
这一节最重要的不是背缩写,而是理解:
LoRA 用更少参数去做任务适配,QLoRA 则在此基础上进一步把大模型微调的资源门槛压低。
它们之所以重要,不只是因为“方法新”,而是因为它们真的改变了大模型微调的现实可行性。
练习
- 用自己的话解释:为什么 LoRA 不是“重训整个矩阵”?
- 为什么说 QLoRA 的关键新增点在于基础模型量化?
- 如果你显存有限但又想试更大模型,为什么 QLoRA 往往更值得优先考虑?
- 用自己的话总结:LoRA 和全量微调最本质的差别是什么?