注意力机制
如果说 RNN 是“按顺序边读边记”,那注意力机制就是另一种思路:
读当前词时,直接回头看整句里最相关的部分。
这就是 Transformer 能崛起的根部原因之一。
学习目标
- 理解为什么序列建模需要注意力机制
- 用直觉理解 Query / Key / Value
- 手算一个最小注意力例子
- 理解 self-attention、multi-head �和 mask 的作用
- 看懂 PyTorch 里的
MultiheadAttention
新人先掌握 / 进阶再理解
如果你是新人,这一节先抓住一句话:注意力是在当前词需要理解自己时,回头看整句话里哪些词最相关。先别急着背 Q/K/V 公式,先理解“相关性打分 -> softmax 权重 -> 加权汇总”这条链。
如果你已经有经验,可以进一步关注:Q/K/V 的矩阵形状、为什么要除以 sqrt(d_k)、mask 如何防止偷看未来、多头注意力为什么能从多个子空间看关系。
历史背景:Transformer 来自哪篇论文?
这一节最值得知道的历史节点是:
| 年份 | 论文 | 关键作者 | 它最重要地解决了什么 |
|---|---|---|---|
| 2017 | Attention Is All You Need | Vaswani 等 | 用 self-attention 替代 RNN 主线,显著改善并行训练能力,并缩短长距离依赖的信息路径 |
对新人来说,最值得先记的不是作者名,而是这句话:
Transformer 之所以重要,不只是因为它“更强”,而是因为它把序列建模从“按顺序传”改成了“直接全局关联”。
所以这节课里你看到的注意力,不是一个局部小技巧,
而是整个 Transformer 路线真正的心脏。
这节和 RNN 主线是怎么接上的
先看一个故事:阅读理解时你不会只记最后一句
想象你在做阅读理解,题目问:“文中‘他’指的是谁?”你不会只看这个字前面的最后一个词,而会回到整句话甚至整段里找线索。哪个名字、哪个动作和这个“他”最相关,你就会把注意力放到那里。
RNN 更像按顺序把信息一站一站传下去,长距离信息容易变弱。注意力机制更像允许当前位置直接回头看所有位置,并给每个位置分配不同权重。这样模型就不必把整句话压进一个固定长度记忆里。
如果你刚学完 RNN,可以先把这节理解成:
- RNN 是“按顺序边读边记”
- 注意力是“当前位直接去看全局最相关的部分”
所以这节真正新增的关键,不是公式,而是:
- 当前位不再只依赖一步步传下来的隐藏状态
- 而是可以直接建立远距离关系
一、为什么要有注意力机制?
1.1 先看 Seq2Seq 的一个痛点
早期的编码器-解码器结构常常这样做:
- 编码器把整句输入压成一个固定长度向量
- 解码器再根据这个向量生成输出
问题是:
一整句的所有信息都被塞进一个固定向量里,长句子特别容易丢信息。
比如翻译这句话:
“这家餐厅虽然位置很偏,但因为老板特别热情、菜量很大、价格也合理,所以我还是愿意再去。”
如果模型到生成最后半句时,还要回忆前面的“老板特别热情”,固定向量往往不够灵活。
1.2 注意力的核心改进
注意力机制说:
不要把整句压成一个点。当前处理某一步时,直接去看整句里哪些部分最相关。
这就像你答阅读理解时,不是把整篇文章全部背下来再答,而是:
- 看到问题
- 回到原文
- 找最相关的句子
这就是注意力的直觉。
1.3 �这一节最该先抓住的,不是 QKV,而是“为什么要变”
也就是说,先别急着背 Q / K / V。
先把这个问题立住:
- 如果固定长度向量会丢信息
- 如果长依赖很难靠一步步传递
那模型就需要一种更灵活的“随时回头看”的机制。
这个问题立住了,后面的 QKV 才不会变成纯记忆题。
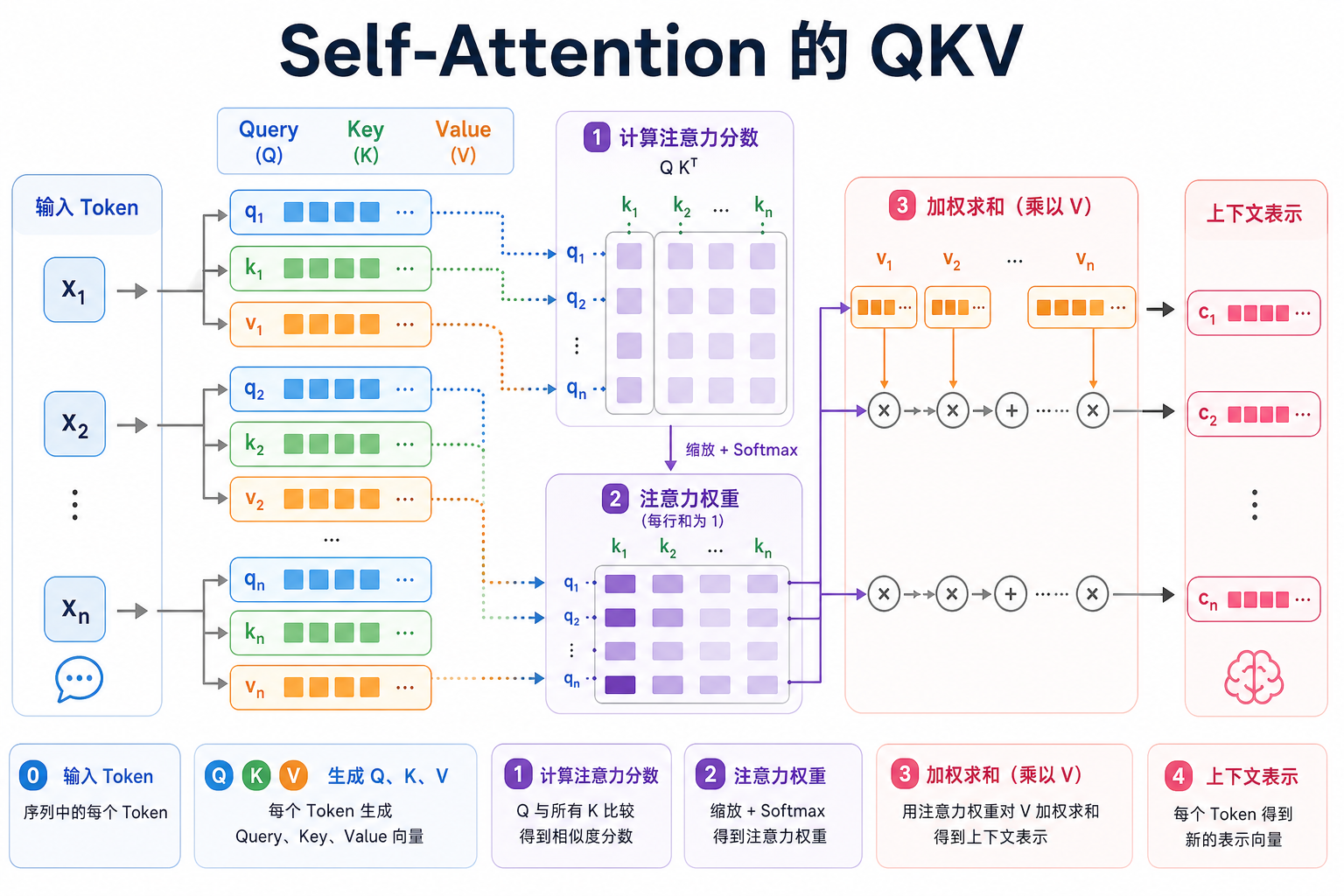
二、Query / Key / Value 到底是什么?
这是很多人一开始最迷糊的地方。
2.1 一个查资料的类比
你要在资料库里找信息:
- Query(查询):你现在想找什么
- Key(索引):每条资料告诉系统“我大概和什么相关”
- Value(内容):真正要取出来用的信息
注意力的过程可以理解成:
- 用 Query 去和所有 Key 做匹配
- 匹配越强,说明越相关
- 再按相关程度加权汇总对应的 Value
2.2 一句话版本
Q 负责提问,K 负责被匹配,V 负责提供内容。
2.3 第一次学 QKV,最容易卡住什么?
通常不是记不住英文,而是:
- 不知道它们为什么要拆成 3 个角色
一个更稳的理解方式是:
Q决定“我现在关心什么”K决定“我大概对应什么内容”V决定“真正被取出来混合的内容是什么”
你先把“角色分工”理解了,后面再看矩阵形式会容易很多。
三、最小可运行例子:手算注意力
3.1 先直接看代码
import numpy as np
# 假设一共有 3 个 token
X = np.array([
[1.0, 0.0], # token1
[0.0, 1.0], # token2
[1.0, 1.0] # token3
])
# 为了教学简单,这里直接让 Q K V 都等于 X
Q = X
K = X
V = X
scores = Q @ K.T
scaled_scores = scores / np.sqrt(K.shape[1])
def softmax(row):
e = np.exp(row - row.max())
return e / e.sum()
weights = np.apply_along_axis(softmax, 1, scaled_scores)
output = weights @ V
print("scores =\n", np.round(scores, 3))
print("weights =\n", np.round(weights, 3))
print("output =\n", np.round(output, 3))
3.2 第一行最重要:Q @ K.T
这一步是在算:
当前 token 和其他 token 有多相关
如果两个向量方向更接近,点积通常会更大。
3.3 第二步:softmax
softmax 会把这些相关性分数变成概率分布:
- 加起来等于 1
- 可以当作“关注程度”
3.4 第三步:weights @ V
这一步是在说:
不再只看当前 token 自己,而是按相关性,把所有 token 的信息加权混合进来。
这就得到新的表示。
3.5 这一步为什么是 Transformer 崛起的根部能力之一?
因为它第一次非常自然地做到了一件事:
- 当前位的表示,不再只由自己决定
- 而是由“自己 + 其他位置和自己的相关程度”共同决定
这意味着模型能更灵活地建立:
- 长距离依赖
- 多位置交互
- 全局上下文
四、为什么要“缩放”?
4.1 缩放点积注意力的公式
Transformer 里常见的是:
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k)) V
这里的 sqrt(d_k) 就是缩放项。
4.2 为什么要除这个数?
因为维度一大,点积数值会变大,softmax 可能过于尖锐:
- 一个位置权重特别大
- 其他位置几乎都接近 0
这样训练会变得不稳定。
所以要缩放一下,让分数更温和。
你可以把它理解成:
向量维度越大,点积天然越“激动”,所以先给它降个温。
五、什么是 Self-Attention?
5.1 Self-Attention 的关键
当 Query / Key / Value 都来自同一段输入时,就叫 self-attention。
这意味着:
序列中的每个位置,都可以去看同一序列里其他位置。
比如句子:
“小王把球给了小李,因为他接得很稳。”
这里“他”指的是谁?
要判断,就要看前面其他词。
self-attention 能直接建这种关系。
5.2 和 RNN 的区别
RNN:
- 顺着时间一步一步传
self-attention:
- 当前位直接看全局
这也是 Transformer 更适合长距离依赖的原因之一。
5.3 Self-Attention 最值得先记的,不是名字,而是能力边界
最值得先记的是:
- 它让每个位置都能直接看整段序列
这句话很重要,因为它正好对应了 RNN 的短板:
- RNN 更像一步步传消息
- Self-Attention 更像一次性建立全局关联
六、Mask 是干什么的?
6.1 为什么生成任务要 mask?
在语言生成里,预测当前位置时不能偷看未来词。
例如预测:
“我爱 ___”
如果模型已经偷看到了后面的真实答案,那训练就失真了。
所以 decoder self-attention 里常会加 causal mask。
6.2 一个最小掩码示例
import numpy as np
scores = np.array([
[2.0, 1.0, 0.5],
[1.2, 2.1, 0.7],
[0.8, 1.3, 2.2]
])
# 下三角可见,上三角屏蔽
mask = np.array([
[1, 0, 0],
[1, 1, 0],
[1, 1, 1]
])
masked_scores = np.where(mask == 1, scores, -1e9)
def softmax(row):
e = np.exp(row - row.max())
return e / e.sum()
weights = np.apply_along_axis(softmax, 1, masked_scores)
print("masked weights =\n", np.round(weights, 3))
你会看到:
- 第 1 个位置只能看自己
- 第 2 个位置只能看前两个
- 第 3 个位置才能看前三个
6.3 为什么 mask 一定要提前理解?
因为一旦进入生成任务,如果不理解 mask,你就很容易搞不清:
- 为什么训练时不能偷看未来
- 为什么 decoder 和 encoder 的注意力行为不一样
所以 mask 不是边角概念,它直接关系到“生成任务到底是不是在按规则训练”。
七、多头注意力为什么要“多头”?
7.1 不是一个头不够算,而是一个头不够看全
单个注意力头可能只学到一种关系。
多头注意力的思路是:
让模型从多个子空间、多个角度同时看关系。
比如不同头可能分别更关注:
- 语法关系
- 位置关系
- 主谓宾关系
- 长距离依赖
7.2 一个直觉类比
多头注意力像开会时请来几种不同角色的人一起看问题:
- 有人看语法
- 有人看语义
- 有人看结构
最后把这些观察拼起来,理解会更完整。
八、PyTorch 中的 MultiheadAttention
8.1 最小可运行示例
import torch
from torch import nn
torch.manual_seed(42)
# seq_len=4, batch=2, embed_dim=8
x = torch.randn(4, 2, 8)
attn = nn.MultiheadAttention(
embed_dim=8,
num_heads=2,
batch_first=False
)
out, weights = attn(x, x, x)
print("input shape :", x.shape)
print("output shape:", out.shape)
print("weights shape:", weights.shape)
8.2 输出 shape 怎么看?
-
out.shape = [4, 2, 8]- 每个位置输出一个新的 8 维表示
-
weights.shape = [2, 4, 4]- 2 个 batch
- 每个 batch 里都是
4x4的注意力矩阵
也就是说:
每个位置都在给序列中所有位置分配注意力权重。
九、注意力机制真正解决了什么?
可以总结成三句话:
- 不再依赖单一路径逐步传递信息
- 当前位可以直接利用全局上下文
- 更容易并行计算
这三点一结合,Transformer 就变得非常强。
十、一个常见错误:把注意力权重当成“最终解释”
注意力权重很直观,所以很多新人会下意识认为:权重高就等于模型“真正理解了原因”。这个理解要谨慎。
注意力权重只能说明在这一层、这个头、这个位置的计算里,某些 token 被赋予了更高权重。它很适合帮助你理解信息混合过程,但不能简单等同于完整因果解释。
所以第一次看 attention 可视化时,最稳的说法是:“这个头在这一层更关注这些位置”,而不是直接说“模型就是因为这个词才得出结论”。
十一、这一节的学习闭环
学完这一节后,可以用下面这张表自测:
| 层次 | 你应该能做到什么 |
|---|---|
| 直觉 | 能解释为什么注意力比固定向量更适合处理长句子 |
| 代码 | 能读懂 Q @ K.T、softmax 和 weights @ V 的作用 |
| 结构 | 能分清 self-attention、mask、multi-head 分别解决什么问题 |
| 后续连接 | 能说明为什么 Transformer、大模型和多模态模型都离不开注意力 |
十二、初学者最常踩的坑
12.1 把 Q / K / V 当成三种“神秘变量”
其实先按“查询 / 索引 / 内容”理解就够了。
12.2 只看公式,不看矩阵形状
注意力这类章节最容易在 shape 上翻车。
一定要盯住:
- 序列长度
- embedding 维度
- 头数
12.3 以为注意力天然理解一切
注意力机制很强,但它不是“自动推理魔法”。
它本质上仍然是:
- 相关性打分
- softmax
- 加权求和
理解这一点,后面学 Transformer 会更踏实。
小结
这一节最关键的不是记住那条公式,而是抓住这个直觉:
注意力机制让模型在当前时刻,能有选择地回头看整段输入中最相关的部分。
这正是 Transformer、大模型、多模态模型能大幅提升上下文建模能力的核心原因。
十三、练习
- 改一下最小注意力示例里的
Q / K / V,观察权重怎样变化。 - 把 mask 示例改成更长序列,看看未来位置如何被屏蔽。
- 用自己的话解释:为什么 self-attention 比单纯 RNN 更容易建模长距离依赖?
- 想一想:如果一个 token 对所有位置的注�意力都差不多,这通常说明什么?