A.3 AI Development History: 15 Stages and Key Papers
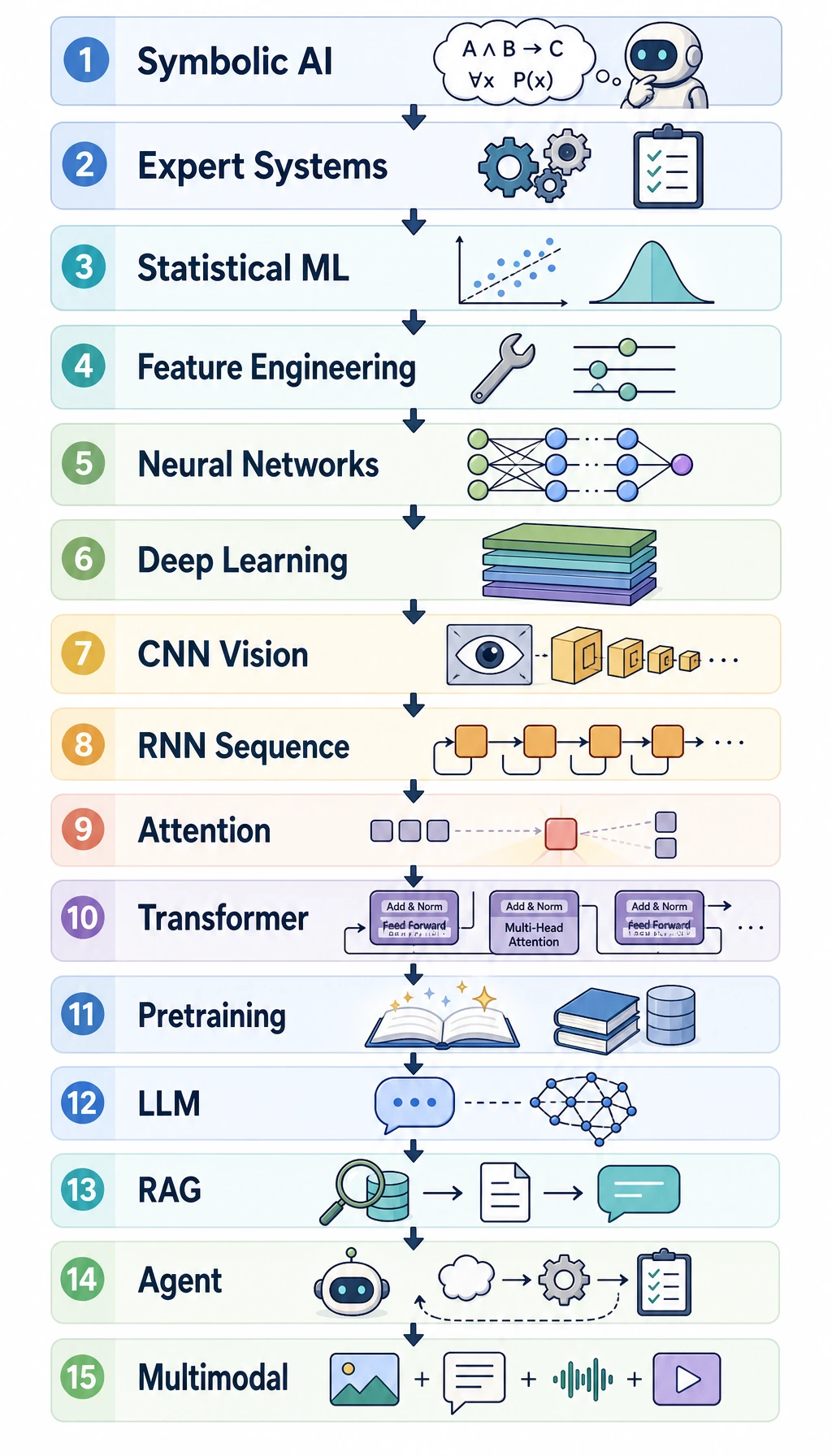
This appendix is optional. Read it when you want a historical “where did this come from?” map, not when you need to memorize papers for the first pass.
Use it in this order:
- Look at the 15-stage picture.
- Scan the stage table.
- Pick only the stage that matches the chapter you are studying.
- Come back later when a paper or algorithm name appears again.
The 15-stage map
| Stage | Beginner meaning | Course anchor |
|---|---|---|
| 1. The AI question | Can a machine show intelligent behavior? | Intro |
| 2. Symbolic AI | Humans write rules; machines reason with rules | Background |
| 3. Expert systems | Domain knowledge becomes rule-based software | System thinking |
| 4. Probability and statistics | Use uncertainty and evidence, not only fixed rules | Chapter 4 |
| 5. Classic machine learning | Learn patterns from data and features | Chapter 5 |
| 6. Early neural networks | A model learns simple decision boundaries | Chapters 5-6 |
| 7. Backpropagation | Multi-layer networks become trainable | Chapter 6 |
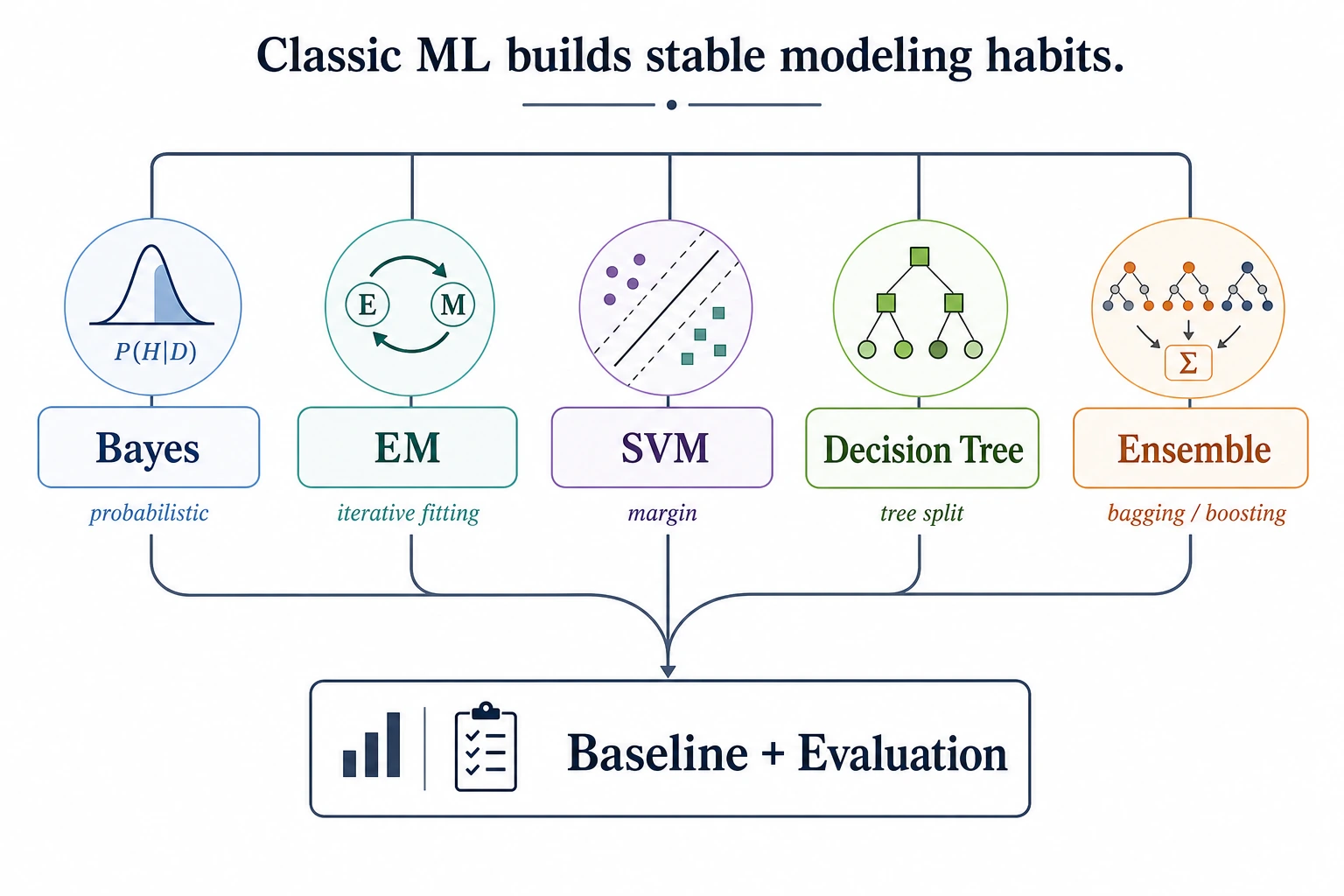
| 8. Kernel and ensemble era | SVM, trees, forests, and boosting make ML practical | Chapter 5 |
| 9. Deep learning breakthrough | Data + GPUs + deep networks unlock vision and speech | Chapters 6 and 10 |
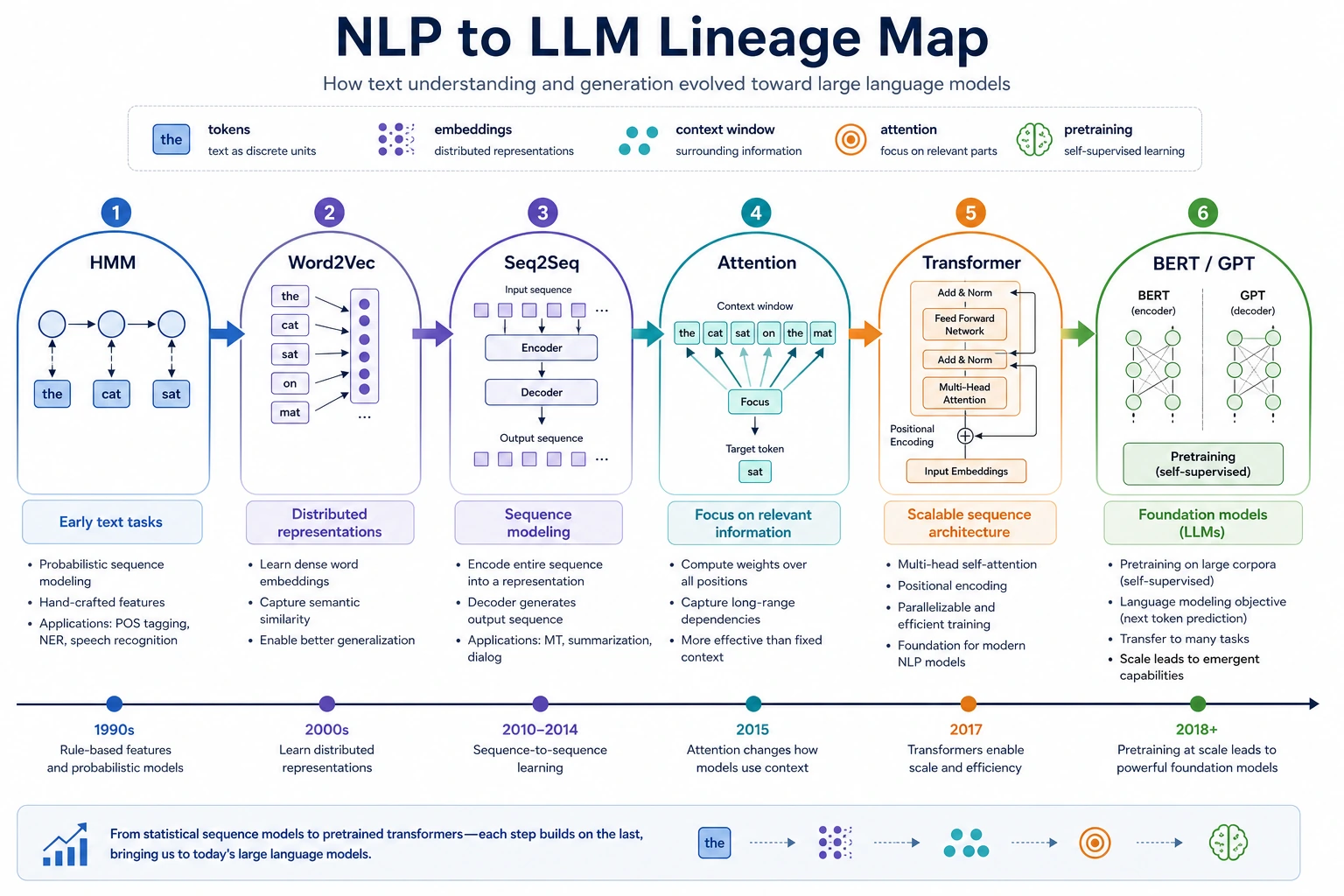
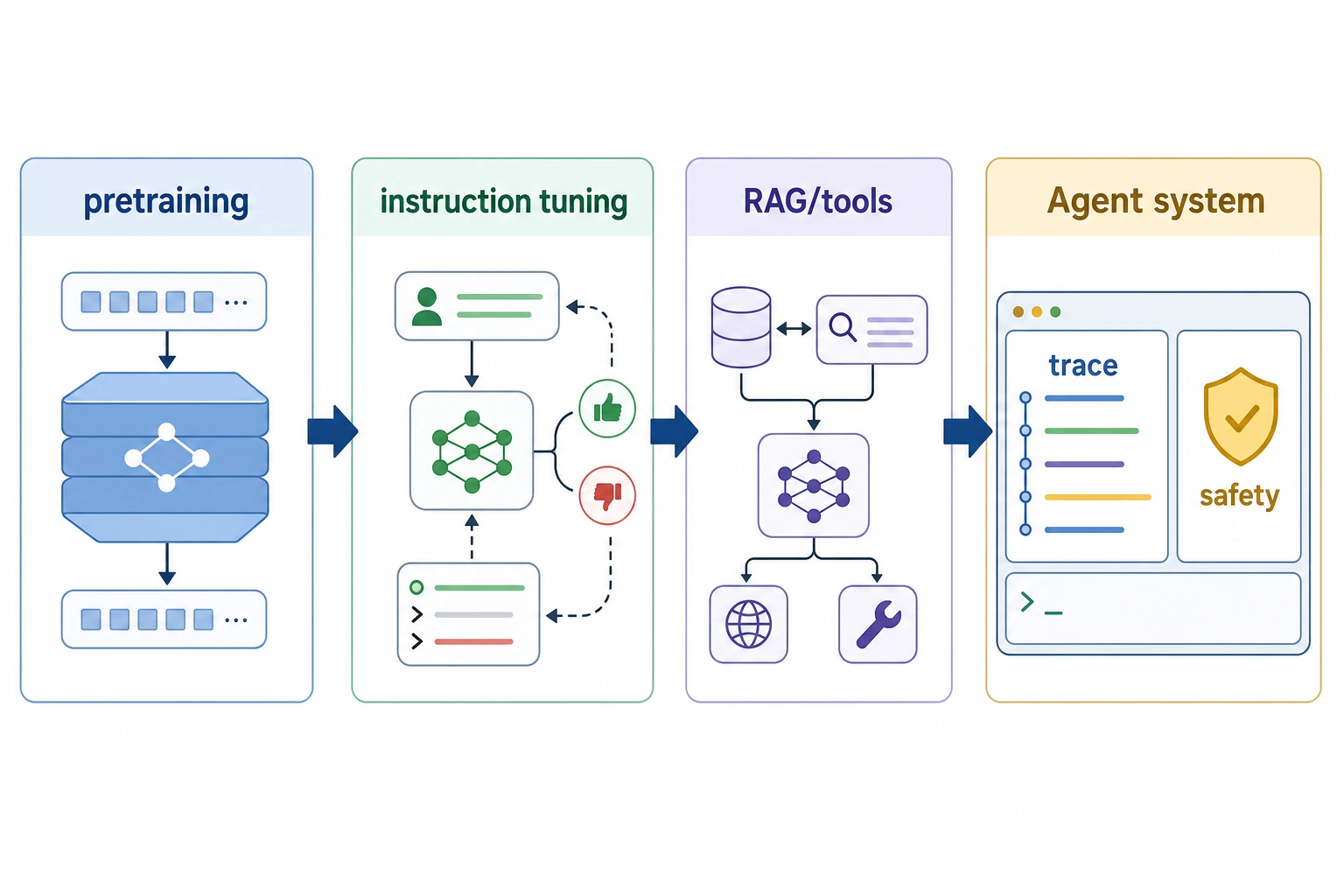
| 10. Embeddings and sequence models | Text becomes vectors; sequences become learnable | Chapter 11 |
| 11. Transformer and pretraining | Attention makes large-scale language models practical | Chapters 6-7 |
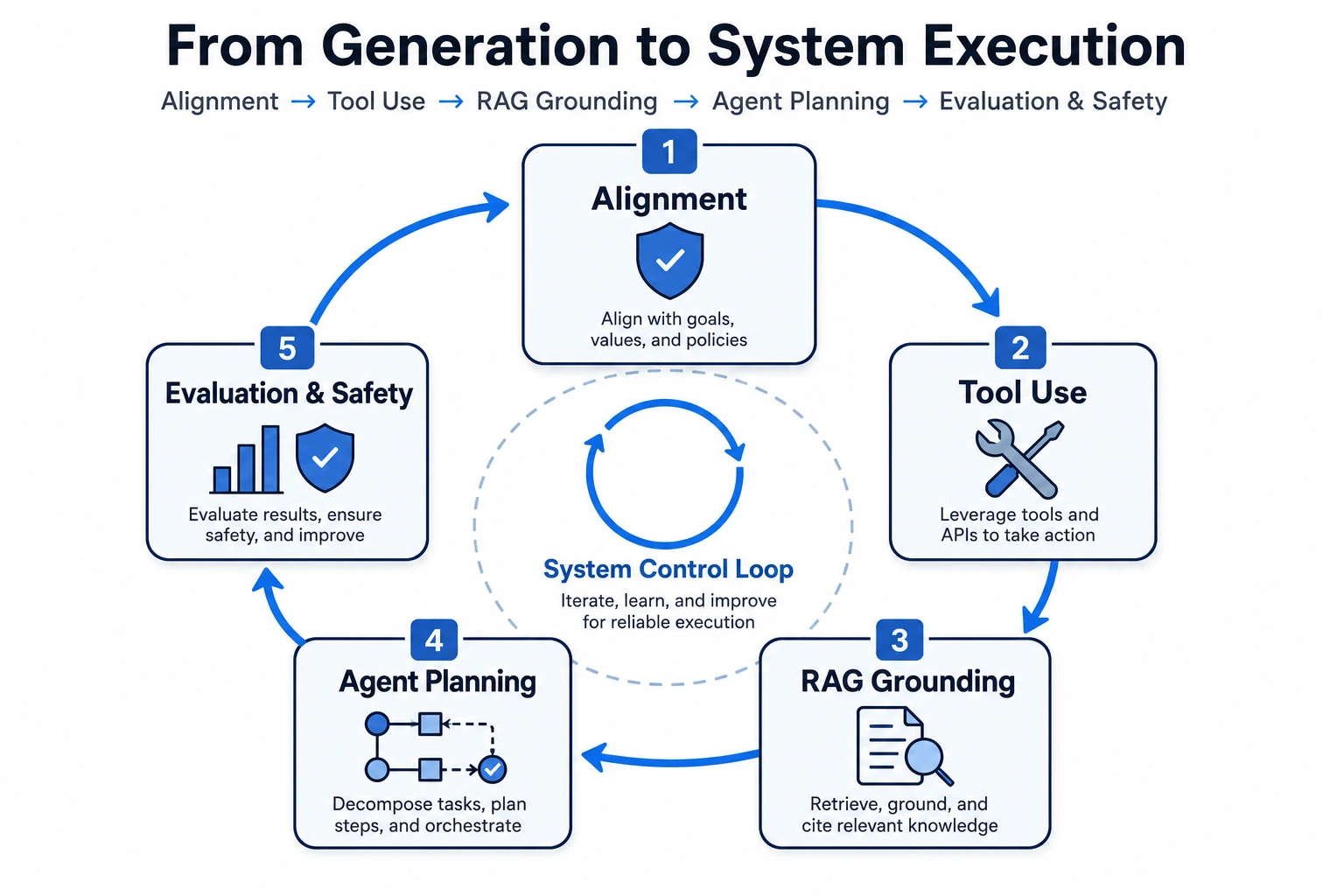
| 12. LLM and alignment | Models become instruction-following assistants | Chapter 7 |
| 13. RAG | Models connect to external knowledge and citations | Chapter 8 |
| 14. Agent and tool use | Models plan, call tools, and leave traces | Chapter 9 |
| 15. Multimodal and AIGC | AI works across text, image, speech, video, and generation | Chapter 12 |
The pattern is simple: every stage solves a bottleneck from the previous stage, then creates a new engineering problem.
Read the main storyline as a relay
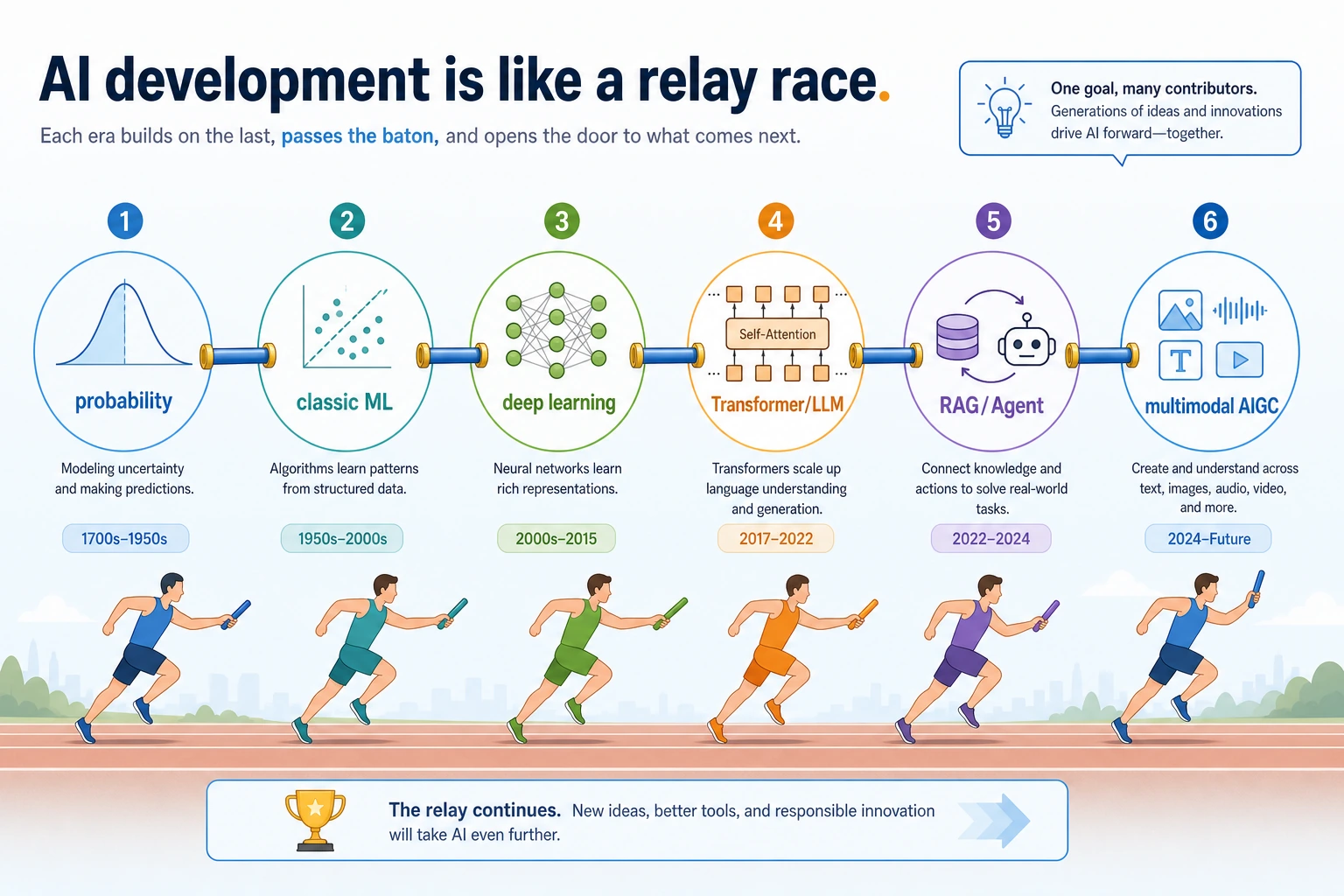
AI history is easier to remember as a relay than as a list of names:
| Relay handoff | What changed |
|---|---|
| Rules -> probability | Systems moved from fixed logic to uncertain evidence |
| Probability -> ML | Models started learning patterns from data |
| ML -> deep learning | Features became learned, not fully hand-designed |
| Deep learning -> Transformer | Sequence modeling became easier to scale |
| LLM -> RAG / Agent | Models connected to knowledge, tools, and workflows |
| Text -> multimodal | AI started understanding and generating multiple media types |
Six turning points worth remembering
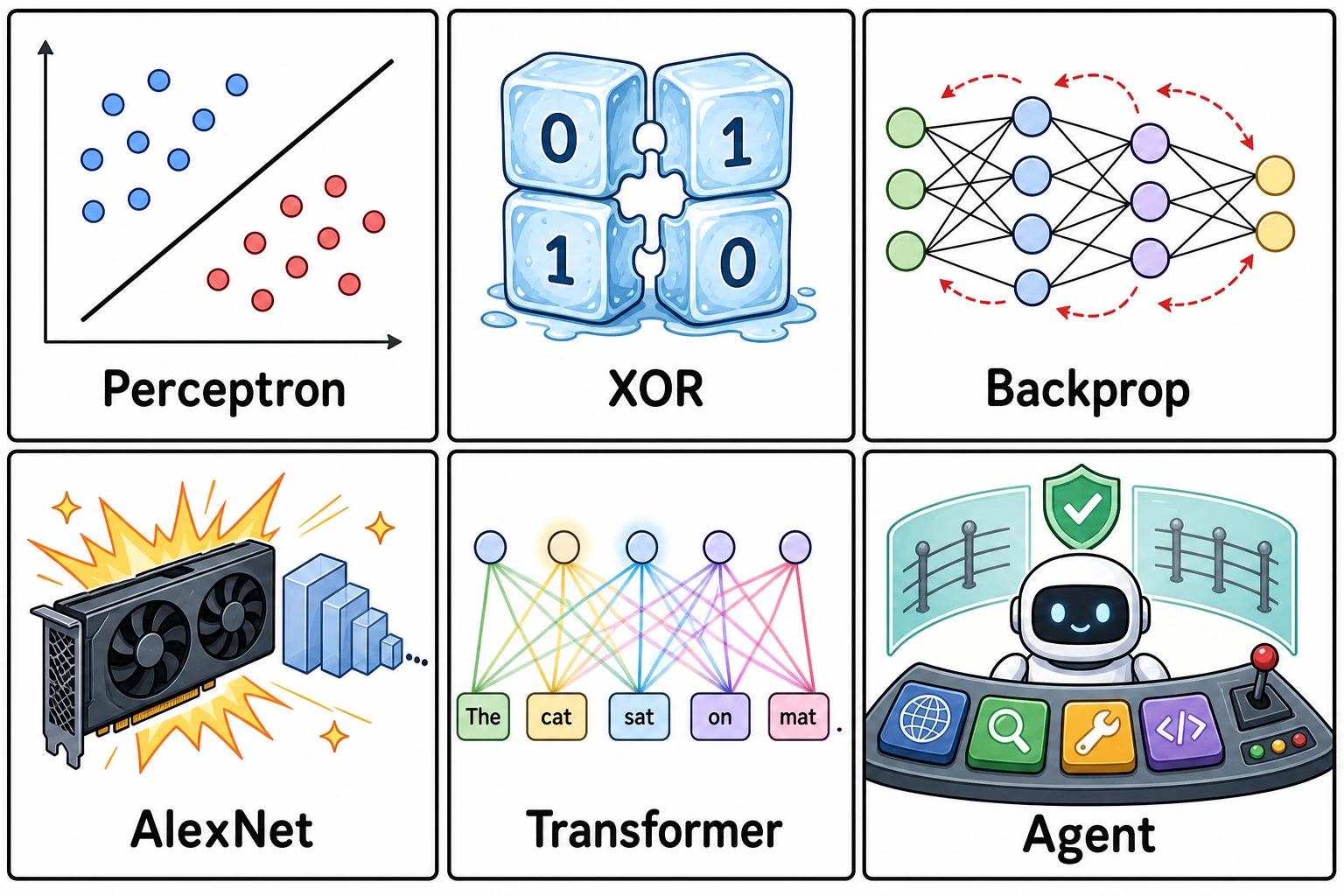
| Turning point | Why beginners should care |
|---|---|
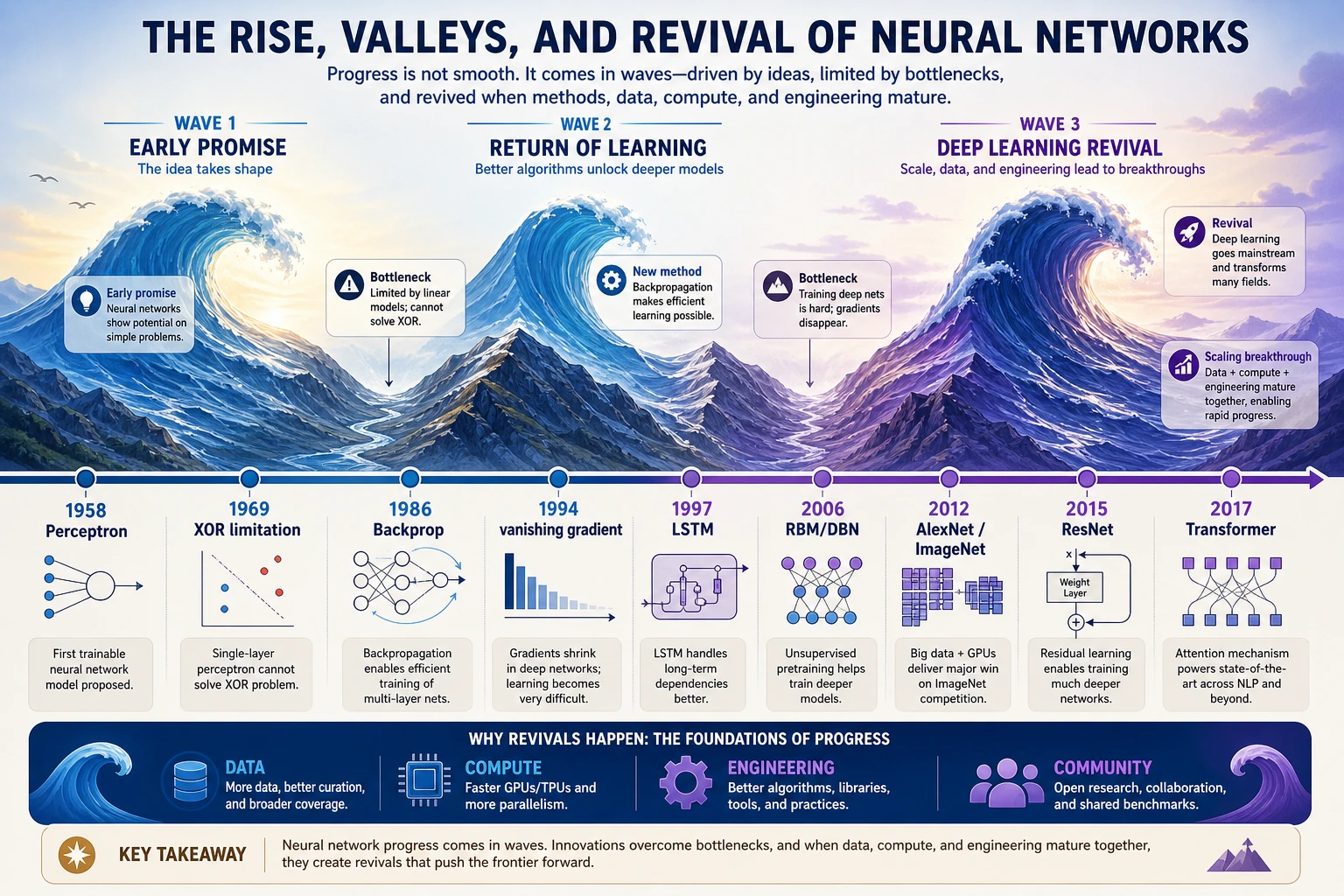
| Perceptron | The first strong feeling that machines might learn from data |
| XOR limitation | A reminder that simple linear models are not enough |
| Backpropagation | Multi-layer neural networks became trainable in practice |
| AlexNet | Data, GPUs, and deep CNNs made deep learning explode |
| Transformer | Attention replaced the old sequence-modeling main line |
| RAG / Agent | Models moved from answering text to using knowledge and tools |
Do not memorize every year first. Remember the shape: hope, setback, repair, scale, and engineering.
How to read a paper node
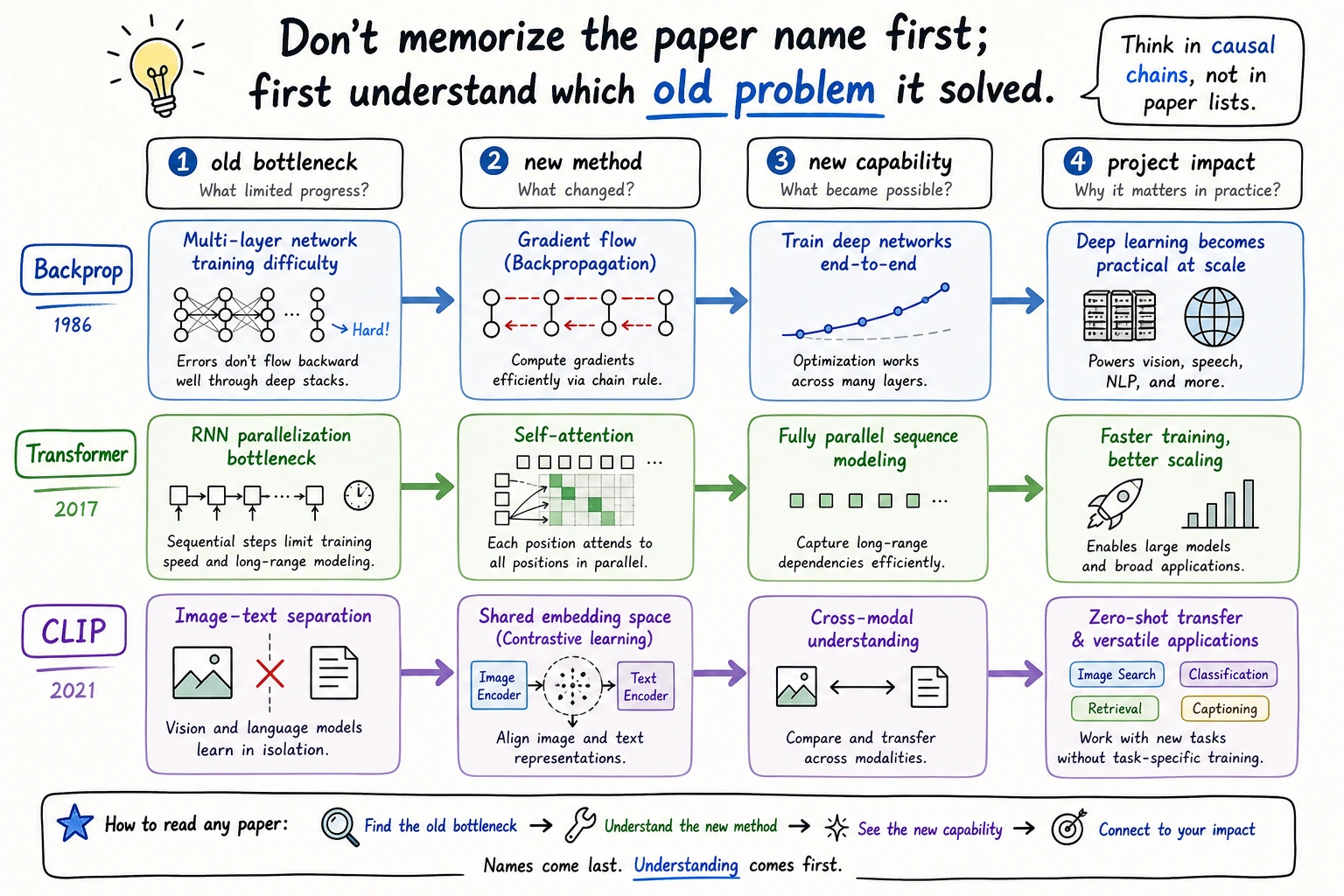
For any paper or algorithm, ask only four questions first:
| Question | Example: Attention Is All You Need |
|---|---|
| What old bottleneck existed? | RNNs were hard to parallelize and struggled with long paths |
| What new method appeared? | Self-attention, multi-head attention, positional encoding |
| What new capability opened? | Scalable sequence modeling and later large language models |
| Which projects changed? | LLMs, RAG, Agent systems, multimodal models |
This is enough for beginner-level historical understanding. Formula details can wait until the relevant chapter.
Key nodes by course line
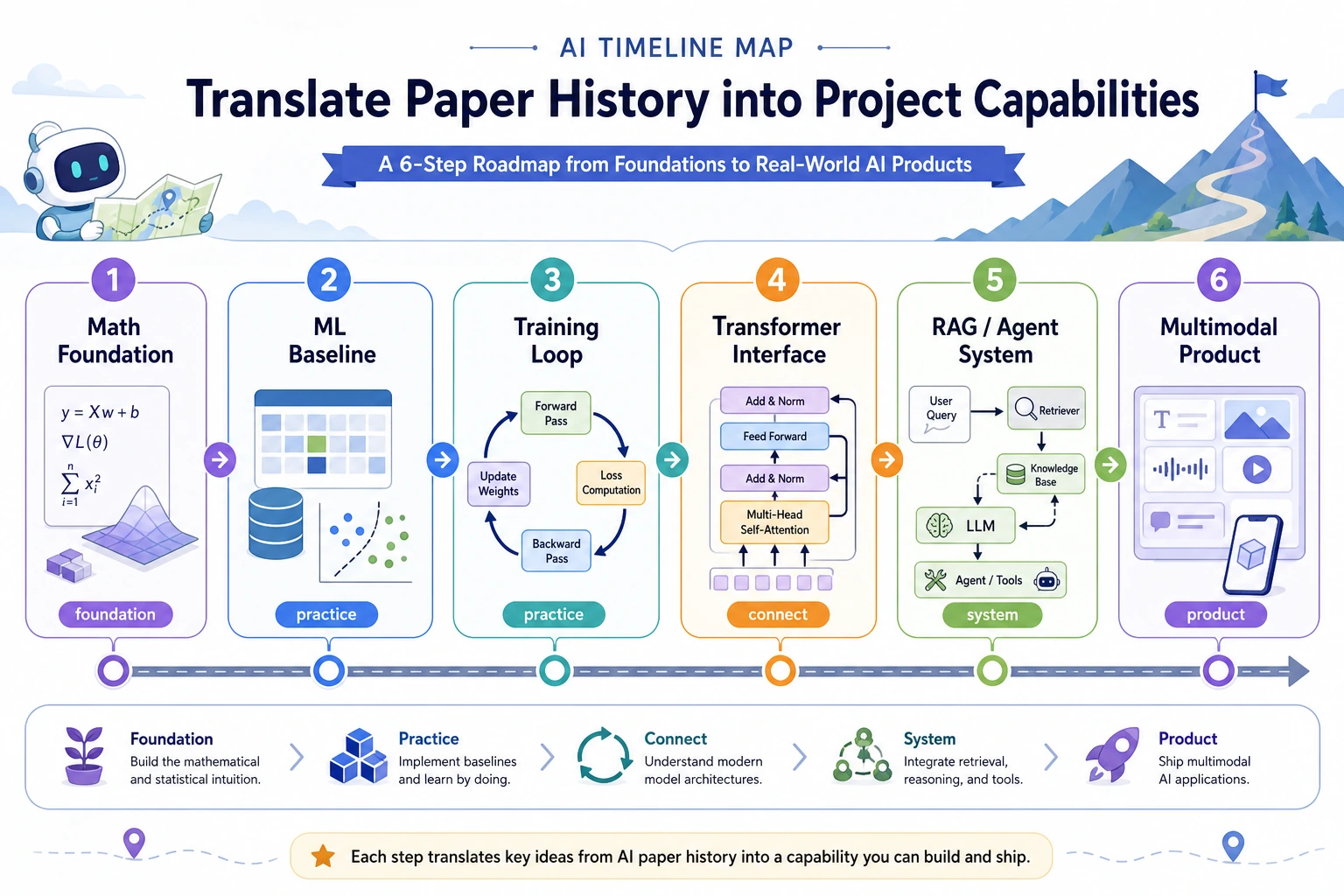
| Course line | Key nodes to recognize first | Why they matter |
|---|---|---|
| Math foundations | Bayes, Shannon, maximum likelihood, EM | Probability, information, and loss functions |
| Classic ML | CART, SVM, Random Forest, AdaBoost, XGBoost | Strong baselines and tabular-data engineering |
| Neural networks | Perceptron, XOR, Backpropagation, LSTM, AlexNet, ResNet | Why depth, gradients, data, and compute matter |
| NLP and LLM | Word2Vec, Seq2Seq, Transformer, BERT, GPT, InstructGPT | The path from word vectors to assistants |
| RAG and Agent | RAG, Chain-of-Thought, ReAct, Toolformer | External knowledge, reasoning traces, and tool use |
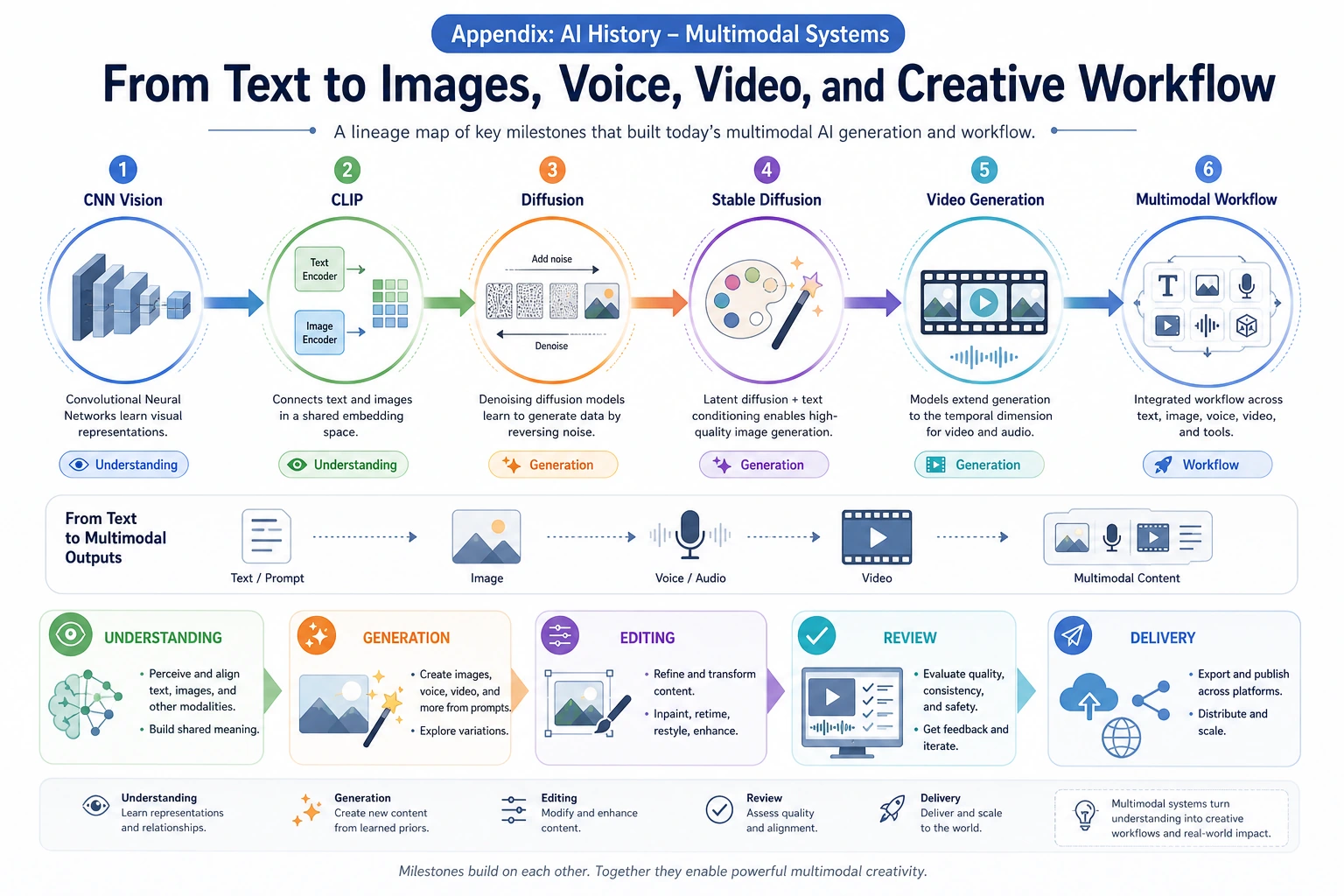
| Multimodal | CLIP, DDPM, Latent Diffusion, Whisper, SAM | Text, image, speech, video, and generation pipelines |
Some entries are landmark papers. Some are algorithm families or historical turning points. That is fine. The useful question is always: what problem did this node make easier?
Optional visual branches
Use these only when you are studying the related chapter.
Fast chapter lookup
| If you see this name | Go back to |
|---|---|
| Bayes, MLE, entropy, EM | Chapter 4 math foundations |
| SVM, Random Forest, XGBoost | Chapter 5 machine learning |
| Perceptron, backpropagation, CNN, LSTM, Transformer | Chapter 6 deep learning |
| GPT, RLHF, LoRA, instruction tuning | Chapter 7 LLM principles |
| RAG, vector retrieval, citations | Chapter 8 RAG |
| Chain-of-Thought, ReAct, Toolformer, tool use | Chapter 9 Agent |
| AlexNet, ResNet, YOLO, SAM | Chapter 10 computer vision |
| Word2Vec, Seq2Seq, BERT, GPT | Chapter 11 NLP |
| CLIP, diffusion, Whisper, multimodal generation | Chapter 12 multimodal |
Mini exercise
Pick any 3 nodes and rewrite them in project language:
Node: Attention Is All You Need
Old bottleneck: RNNs were not ideal for long sequences or parallel training.
New method: self-attention became the main line of sequence modeling.
Projects affected: LLMs, RAG, Agent systems, multimodal models.
Course chapter to revisit: Chapters 6, 7, 8, and 9.
The goal is not to recite history. The goal is to connect a historical node to a real capability you may build later.